 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2022-01-18. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.Table of Contents
Python零碎知识
interactive shell和script的差别一例
来自🔗 [python idle 解释和直接 python script.py 解释有什么差别? - 知乎] https://www.zhihu.com/question/29089863 的例子:

判断script mode还是interactive mode的方法
🔗 [Tell if Python is in interactive mode - Stack Overflow] https://stackoverflow.com/questions/2356399/tell-if-python-is-in-interactive-mode
import __main__ as main
print(hasattr(main, '__file__'))或者
import os
try:
os.path.realpath(__file__)
print('script')
except:
print('shell')隐马尔可夫-Viterbi
特别注意:Viterbi和Viterbi training是不一样的,见:🔗 [2022-03-19 - Truxton's blog] https://truxton2blog.com/2022-03-19/
首先是复习HMM要解决的3个问题:

Viterbi经典例题以及代码
例题(感冒发烧的那个)
由于这个例题太经典了,所以为这道题单独开一个目录。如果有必要还可能会拉出来单独作为一篇笔记。
有关Viterbi的阅读材料:
🔗 如何通俗地讲解 viterbi 算法? - Kiwee的回答 - 知乎https://www.zhihu.com/question/20136144/answer/239971177)(这个链接对应的问题下面有还有其他回答,但对Viterbi的DP部分讲述的不够好,所以仅仅推荐这个回答)
以防万一,决定备份这道题,如果Viterbi算法忘了就回来重新做一遍:
2023-03-27版本的代码
把去年写的代码修改了一版,去掉了去年临时hard-coding的一些变量数字。
如果要替换成其他程序,只需要修改到 init = np.array([0.6, 0.4]) 这一行即可。剩余的代码都不需要修改。
import numpy as np
from tabulate import tabulate
"""
在后续代码中,
s0就是state_set[0]=0,对应state_matching.get(0)=健康=状态为健康
ob0就是observe_set[0]=0,对应observe_matching.get(0)=正常=观测到正常
"""
observe_set = (0, 1, 2)
state_set = (0, 1)
observe_matching = {0: '正常', 1: '冷', 2: '头晕'}
state_matching = {0: '健康', 1: '发烧'}
observe_sequence = [0, 1, 2]
"""
状态转移矩阵
s0 s1
s0 0.7 0.3
s1 0.4 0.6
"""
trans = np.array([
[0.7, 0.3],
[0.4, 0.6]
])
"""
ob0 ob1 ob2
s0 0.5 0.4 0.1
s1 0.1 0.3 0.6
"""
emission = np.array([
[0.5, 0.4, 0.1],
[0.1, 0.3, 0.6]
])
"""
初始化:60% s0 , 40% s1
"""
init = np.array([0.6, 0.4])
"""
3天观测的结果:[ob0, ob1, ob2]
创建viterbi长条形矩阵
ob0 ob1 ob2
s0 0.6*0.5 ? ?
s1 0.4*0.1 ? ?
"""
vit = np.zeros((len(state_set), len(observe_sequence)), dtype=np.float128)
for i in range(0, len(state_set)):
vit[i][0] = init[i] * emission[i][0]
"""
创建回溯矩阵
(下面的0和1不代表真实数据,仅仅展示一种可能)
其中0和1代表"和当前节点连接的,前一天的index"
如果第3天判定为【健康】,那么回溯结果为:(这是一个从第一天开始的正向序列)发烧->健康->健康(这是一个从第一天开始的正向序列)
具体方法是:第3天为健康 -> 找到数字0 -> 寻找第2天的index=0行(健康) -> 得到数字1 -> 寻找第1天的index=1行(发烧)
如果第3天判定为【发烧】,那么回溯结果为:(这是一个从第一天开始的正向序列)健康->发烧->发烧
具体方法是:第3天为发烧 -> 找到数字1 -> 寻找第2天的index=1行(发烧) -> 得到数字0 -> 寻找第1天的index=0行(健康)
天数1 天数2 天数3
0健康 空 1 0
1发烧 空 0 1
"""
fast_previous_matrix = np.empty((len(state_set), len(observe_sequence))).astype(dtype=int)
# 开始处理第2天、第3天...
for column in range(1, len(observe_sequence)):
single_observe = observe_sequence[column]
previous_vit_col = vit[:, (column - 1)] # 获取前一天的一列
for i in range(0, len(state_set)):
ancestors = previous_vit_col * trans[:, i] * emission[i][single_observe]
vit[i, column] = np.max(ancestors)
fast_previous_matrix[i, column] = np.argmax(ancestors)
print(tabulate(vit, headers='keys', tablefmt='fancy_grid'))
"""
如果一切顺利,到目前为止的结果应该是:
vit
0.30000,0.08400,0.00588
0.04000,0.02700,0.01512
fast_previous_matrix
0,0,0
0,0,0
"""
"""
现在开始trace back
"""
status_result = []
# 取vit矩阵最后一天的那一列,选出数值最高的那个,然后映射fast_previous_matrix相同位置的index
status_result.insert(0, np.argmax(vit[:, -1]))
last_ancestor = fast_previous_matrix[:, -1][np.argmax(vit[:, -1])]
# 从倒数第二列开始,一直回溯到第0列
for column in range(vit.shape[1] - 2, -1, -1):
status_result.insert(0, last_ancestor)
last_ancestor = fast_previous_matrix[:, column][last_ancestor]
print(status_result)
# 然后转换为结果
status_result = np.array(status_result).astype(dtype=int)
printed_result = np.empty(len(status_result)).astype(dtype=str)
for state in state_set:
printed_result[np.where(status_result == state)] = state_matching[state]
print(list(printed_result))
另一个viterbi习题,来自🔗 [murray-z/viterbi: viterbi算法] https://github.com/murray-z/viterbi,用上面的代码稍稍修改一点即可:
import numpy as np
from tabulate import tabulate
"""
在后续代码中,
s0就是state_set[0]=0,对应state_matching.get(0)=健康=状态为健康
ob0就是observe_set[0]=0,对应observe_matching.get(0)=正常=观测到正常
"""
observe_set = (0, 1, 2, 3)
state_set = (0, 1, 2)
observe_matching = {0: 'Dry', 1: 'Dryish', 2: 'Damp', 3: 'Soggy'}
state_matching = {0: 'Sunny', 1: 'Cloudy', 2: 'Rainy'}
observe_sequence = [0, 2, 3]
"""
状态转移矩阵
s0 s1
s0 0.7 0.3
s1 0.4 0.6
"""
trans = np.array([
[0.5, 0.375, 0.125],
[0.25, 0.125, 0.625],
[0.25, 0.375, 0.375]
])
"""
ob0 ob1 ob2
s0 0.5 0.4 0.1
s1 0.1 0.3 0.6
"""
emission = np.array([
[0.6, 0.2, 0.15, 0.05],
[0.25, 0.25, 0.25, 0.25],
[0.05, 0.1, 0.35, 0.5]
])
"""
初始化:60% s0 , 40% s1
"""
init = np.array([0.63, 0.17, 0.20])
"""
3天观测的结果:[ob0, ob1, ob2]
创建viterbi长条形矩阵
ob0 ob1 ob2
s0 0.6*0.5 ? ?
s1 0.4*0.1 ? ?
"""
vit = np.zeros((len(state_set), len(observe_sequence)), dtype=np.float128)
for i in range(0, len(state_set)):
vit[i][0] = init[i] * emission[i][0]
"""
创建回溯矩阵
(下面的0和1不代表真实数据,仅仅展示一种可能)
其中0和1代表"和当前节点连接的,前一天的index"
如果第3天判定为【健康】,那么回溯结果为:(这是一个从第一天开始的正向序列)发烧->健康->健康(这是一个从第一天开始的正向序列)
具体方法是:第3天为健康 -> 找到数字0 -> 寻找第2天的index=0行(健康) -> 得到数字1 -> 寻找第1天的index=1行(发烧)
如果第3天判定为【发烧】,那么回溯结果为:(这是一个从第一天开始的正向序列)健康->发烧->发烧
具体方法是:第3天为发烧 -> 找到数字1 -> 寻找第2天的index=1行(发烧) -> 得到数字0 -> 寻找第1天的index=0行(健康)
天数1 天数2 天数3
0健康 空 1 0
1发烧 空 0 1
"""
fast_previous_matrix = np.empty((len(state_set), len(observe_sequence))).astype(dtype=int)
# 开始处理第2天、第3天...
for column in range(1, len(observe_sequence)):
single_observe = observe_sequence[column]
previous_vit_col = vit[:, (column - 1)] # 获取前一天的一列
for i in range(0, len(state_set)):
ancestors = previous_vit_col * trans[:, i] * emission[i][single_observe]
vit[i, column] = np.max(ancestors)
fast_previous_matrix[i, column] = np.argmax(ancestors)
print(tabulate(vit, headers='keys', tablefmt='fancy_grid'))
"""
如果一切顺利,到目前为止的结果应该是:
vit
0.30000,0.08400,0.00588
0.04000,0.02700,0.01512
fast_previous_matrix
0,0,0
0,0,0
"""
"""
现在开始trace back
"""
status_result = []
# 取vit矩阵最后一天的那一列,选出数值最高的那个,然后映射fast_previous_matrix相同位置的index
status_result.insert(0, np.argmax(vit[:, -1]))
last_ancestor = fast_previous_matrix[:, -1][np.argmax(vit[:, -1])]
# 从倒数第二列开始,一直回溯到第0列
for column in range(vit.shape[1] - 2, -1, -1):
status_result.insert(0, last_ancestor)
last_ancestor = fast_previous_matrix[:, column][last_ancestor]
print(status_result)
# 然后转换为结果
status_result = np.array(status_result).astype(dtype=int)
printed_result = np.empty(len(status_result)).astype(dtype=str)
for state in state_set:
printed_result[np.where(status_result == state)] = state_matching[state]
print(list(printed_result))
我的运行结果:
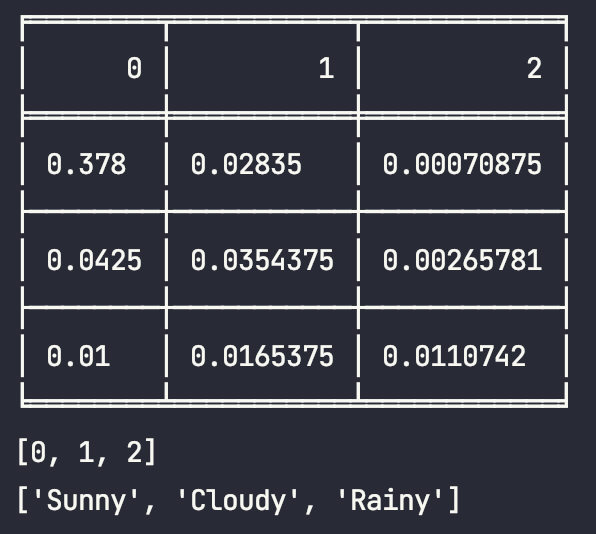
🔗 [murray-z/viterbi: viterbi算法] https://github.com/murray-z/viterbi 的代码的运行结果(额外print了probability变量)方便对比数字:

后续优化:还可以事先检查转移矩阵和发射矩阵是否合规(每行/每列相加为1),但暂时先不搞了。
2022-12-01版本的代码
2022-12-01更新:代码:
import numpy as np
"""
3天观测的结果:[正常,冷,头晕]
这里的数值对应了trans matrix里的column index
正常 冷 头晕
健康 0.5 0.4 0.1
发烧 0.1 0.3 0.6
"""
observe = [0, 1, 2]
"""
健康 发烧
健康 0.7 0.3
发烧 0.4 0.6
"""
trans = np.array([
[0.7, 0.3],
[0.4, 0.6]
])
"""
正常 冷 头晕
健康 0.5 0.4 0.1
发烧 0.1 0.3 0.6
"""
emission = np.array([
[0.5, 0.4, 0.1],
[0.1, 0.3, 0.6]
])
"""
初始化:60%概率发烧,40%概率正常
"""
init = np.array([0.6, 0.4])
"""
3天观测的结果:[正常,冷,头晕]
创建viterbi长条形矩阵
天数1 天数2 天数3
健康 0.6*0.5 ? ?
发烧 0.4*0.1 ? ?
"""
vit = np.zeros((2, 3))
vit[0][0] = 0.6 * 0.5
vit[1][0] = 0.4 * 0.1
"""
创建回溯矩阵
下面的0和1不代表真实数据,仅仅展示一种可能
如果第3天判定为【健康】,那么回溯结果为:发烧->健康->健康
如果第3天判定为【发烧】,那么回溯结果为:健康->发烧->发烧
天数1 天数2 天数3
0健康 空 1 0
1发烧 空 0 1
"""
fast_previous_matrix = np.empty((2, 3)).astype(dtype=int)
# 开始处理第2天、第3天
for column in range(1, 3):
single_observe = observe[column]
previous_vit_col = vit[:, (column - 1)] # 获取前一天的一列
# 如果当天观测到【正常】
if single_observe == 0:
# 上一天?->当天健康->观测到【正常】
# trans[:,0]其实是[0.7, 0.4]
ancestors = previous_vit_col * trans[:, 0] * 0.5
vit[0, column] = np.max(ancestors)
fast_previous_matrix[0, column] = np.argmax(ancestors)
# 上一天?->当天发烧->观测到【正常】
# trans[:,1]其实是[0.3, 0.6]
ancestors = previous_vit_col * trans[:, 1] * 0.1
vit[1, column] = np.max(ancestors)
fast_previous_matrix[1, column] = np.argmax(ancestors)
# 如果当天观测到【冷】
elif single_observe == 1:
# 上一天?->当天健康->观测到【冷】
# trans[:,0]其实是[0.7, 0.4]
ancestors = previous_vit_col * trans[:, 0] * 0.4
vit[0, column] = np.max(ancestors)
fast_previous_matrix[0, column] = np.argmax(ancestors)
# 上一天?->当天发烧->观测到【冷】
# trans[:,1]其实是[0.3, 0.6]
ancestors = previous_vit_col * trans[:, 1] * 0.3
vit[1, column] = np.max(ancestors)
fast_previous_matrix[1, column] = np.argmax(ancestors)
# 如果当天观测到【头晕】
elif single_observe == 2:
# 上一天?->当天健康->观测到【头晕】
# trans[:,0]其实是[0.7, 0.4]
ancestors = previous_vit_col * trans[:, 0] * 0.1
vit[0, column] = np.max(ancestors)
fast_previous_matrix[0, column] = np.argmax(ancestors)
# 上一天?->当天发烧->观测到【头晕】
# trans[:,1]其实是[0.3, 0.6]
ancestors = previous_vit_col * trans[:, 1] * 0.6
vit[1, column] = np.max(ancestors)
fast_previous_matrix[1, column] = np.argmax(ancestors)
print('debug here')
"""
如果一切顺利,到目前为止的结果应该是:
vit
0.30000,0.08400,0.00588
0.04000,0.02700,0.01512
fast_previous_matrix
0,0,0
0,0,0
"""
"""
现在开始trace back
"""
status_result = []
# 取vit矩阵最后一天的那一列,选出数值最高的那个,然后映射fast_previous_matrix相同位置的index
status_result.insert(0, np.argmax(vit[:, -1]))
last_ancestor = fast_previous_matrix[:, -1][np.argmax(vit[:, -1])]
# 从倒数第二列开始,一直回溯到第0列
for column in range(vit.shape[1] - 2, -1, -1):
status_result.insert(0, last_ancestor)
last_ancestor = fast_previous_matrix[:, column][last_ancestor]
print(status_result)
# 然后转换为结果
status_result = np.array(status_result).astype(dtype=int)
printed_result = np.empty(len(status_result)).astype(dtype=str)
printed_result[np.where(status_result == 0)] = '健康'
printed_result[np.where(status_result == 1)] = '发烧'
print(list(printed_result))
运行结果为
debug here
[0, 0, 1]
['健康', '健康', '发烧']代码里的一些数值暂时hard coding...等以后有机会修改。
剩余学习材料
🔗 [tutorial.pdf] https://courses.media.mit.edu/2010fall/mas622j/ProblemSets/ps4/tutorial.pdf
搜索关键词: real time viterbi
OCR辅助查找工具
1.sublime运行结果 20 21 a = 10.1 22 b = 10.1 23 print a is b 24 print id(a) 25 print id(b)True 30697672 30697672 [Finished in 0.0s]2 python idle 运行结果公公公 & 10.1 h = 10.1 〉〉〉a is h False〉〉〉 id(a) 30697528L 〉>〉idch〉 30697480L10.1.3 隐马尔可夫模型的3 个基本问题隐马尔可夫模型有3个基本问题: (1)概率计算问题。给定模型入二(A,B,T)和观测序列O=(o1,02,⋯ or),计 算在模型入下观测序列◎ 出现的概率 P(OIA)。10.2 概率计算算法 197(2)学习问题。己知观测序列◎=(ol,o2,⋯⋯,0T),估计模型入=(A,B,丌)参数, 使得在该模型下观测序列概率 P(OIA) 最大。即用极大似然估计的方法估计参数。 (3)预测问题,也称为解码(decoding)问题。已知模型入=(A,B,不)和观测 序列◎二(o1,02,,oT),求对给定观测序列条件概率 P(IIO)最大的状态序列 [二(n,2,,i)。即给定观测序列,求最有可能的对应的状态序列。
