 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2022-07-19. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.Table of Contents
乐理中英对照
subdominant/下属音
subdominant: 下属音
subdominant chord: 下属和弦
🔗 [下属音 - 维基百科,自由的百科全书] https://zh.wikipedia.org/zh-hans/下屬音
tonic 主音
tonic 主音
顺便学习主音和主和弦的关系:🔗 [主音 - 维基百科,自由的百科全书] https://zh.wikipedia.org/zh-hans/主音
机器学习:codebook
机器学习:codebook
最开始在《Fundamentals of ...》P287见到:

🔗 [浅析 Bag of Feature | Jermmy's Lazy Blog] https://jermmy.github.io/2017/04/28/2017-4-28-understand-bag-of-feature/
content-sensitive semantic smoothing
content-sensitive semantic smoothing
与之对应的前置概念是interpolation:🔗 [2022-07-15 - Truxton's blog] https://truxton2blog.com/2022-07-15/#Prefiltering
最开始在这里提到:

ext4与APFS的大小写敏感问题
区分大小写 = 相同目录下允许同时存在文件A和文件a = 大小写敏感 = case sensitive
不区分大小写 = 相同目录下不允许同时存在文件A和文件a = 大小写不敏感 = case insensitive
Linux普遍使用的ext4文件系统区分大小写(相同目录下允许同时存在文件A和文件a);
APFS文件系统 默认 不区分大小写(相同目录下不允许同时存在文件A和文件a)。
| 如果你看到: | 那么它代表着: | 也就是说: |
| APFS | case insensitive | 相同目录下不允许同时存在文件A和文件a |
| APFS (case sensitive) | case sensitive | 相同目录下允许同时存在文件A和文件a |
| macbook原厂系统的APFS硬盘 | case insensitive | 相同目录下不允许同时存在文件A和文件a |
| ext4 | case sensitive | 相同目录下允许同时存在文件A和文件a |
如果linux-ext4文件系统的某个文件夹下存在2个仅有大小写区别的文件(比如/PATH/AAAA.txt和/PATH/aaaa.txt),那么它们同步到macOS系统上的时候可能会出现问题!FreefileSync论坛上已经有类似问题了:🔗 [Case-sensitive collision detection - FreeFileSync Forum] https://freefilesync.org/forum/viewtopic.php?t=7657
那么如何找到所有这样的文件呢?
网上有很多种解法,试了很多,最后发现这个命令比较适合我的情况(recursive所有子目录;仅考虑同一目录下的此类文件,目录不同就不需要考虑了):🔗 [bash - How to find duplicate files with same name but in different case that exist in same directory in Linux? - Stack Overflow] https://stackoverflow.com/questions/2109056/how-to-find-duplicate-files-with-same-name-but-in-different-case-that-exist-in-s
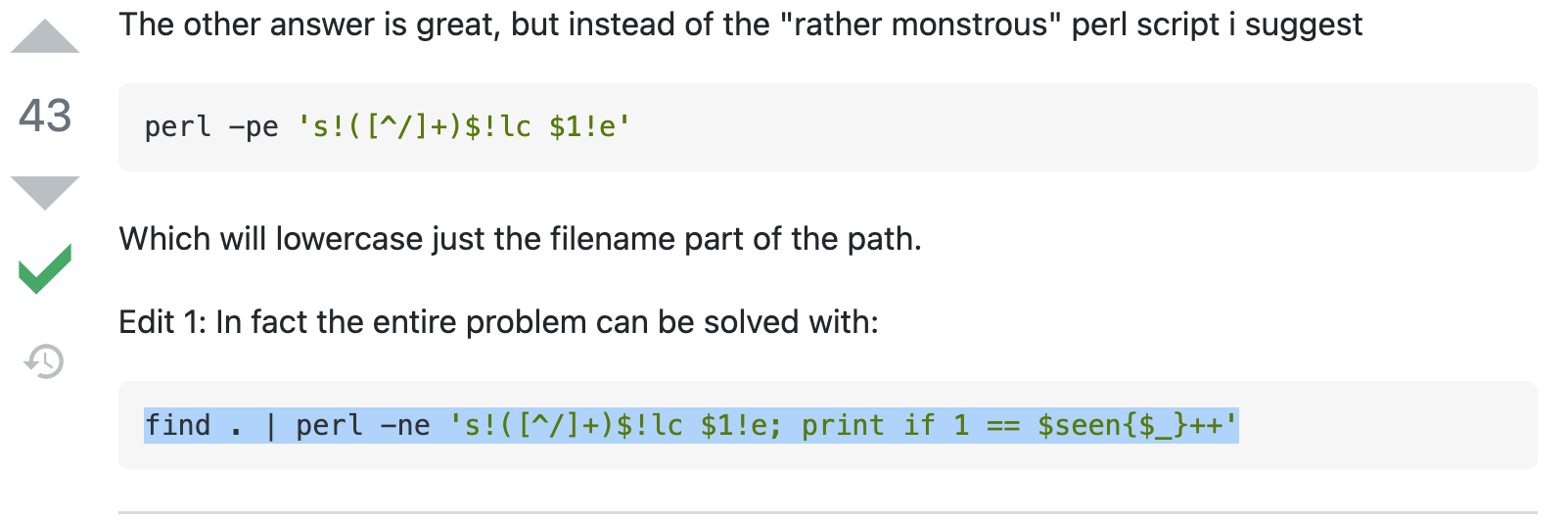
也就是
find . | perl -ne 's!([^/]+)$!lc $1!e; print if 1 == $seen{$_}++'先找到可疑的文件,然后再使用其他方法进一步查看分析。
那么本站有没有可能产生这样的文件呢?(不考虑故意行为或者系统出现严重错误)
概率为0. 一张图片的格式为 精确到秒的日期+时间,再加5个随机字符 ,比如: 20220719_171606_lcOPF.png ,而本站只有1个admin用户。
那么Wordpress的搜索功能对大小写宽容吗?比如我想搜索 20220719_171606_lcOPF.png ,但实际上只输入了 opf.png .
是宽容的(当然这个实际上是mysql的实现,所以更应该说是mysql给了宽容度):

chord recognition: postfiltering
chord recognition - postfiltering
步入正轨
从这部分开始阅读:

读完P273以后,接下来的好几节是已经掌握的知识,大概是不需要看了。
注意到书上会使用“Hidden State Sequence Uncovering Problem”这样的描述(P280),这个其实就是“HMM的decoding问题”,给定HMM模型和观察序列,求最有可能的状态序列。
接下来读到P287:

这部分内容好像以前看过!确实看过,但是只看过一点点:🔗 [2022-03-29 - Truxton's blog] https://truxton2blog.com/2022-03-29/
现在继续。
有关HMM模型的选择(离散还是连续)
有关HMM模型的选择(离散还是连续)
书中比较了离散和连续2种选择的优劣。但是已经超过了书本的知识范畴。
值得注意的是,即使“离散HMM模型”是老旧过时技术,也不意味着codebook一共只有24种chord状态!24种chord状态是最简单的理论模型,实际投入使用的时候面临的情况远不止这些。
如果使用真实数据构建HMM chord codebook,那么可以使用各种机器学习clustering算法来分出很多cluster,然后使用quantization方法来决定一个HMM状态到底属于codebook中的哪一类。
有关transition probability的构建方式
有关transition probability的构建方式
从P288开始
尽管《Fundamentals of …》在之前已经介绍过Baum-Welch算法了,但是构建transition probability matrix的内容却没有用到这方面的算法,而是采用了一些更简单粗暴的方法:直接统计。
甚至还可以直接让资深乐理砖家来生成这个转移概率矩阵。
当然更常见的方法是直接统计音乐库里的和弦转移情况,然后生成和弦转移概率矩阵(要求标注数据)。比如:
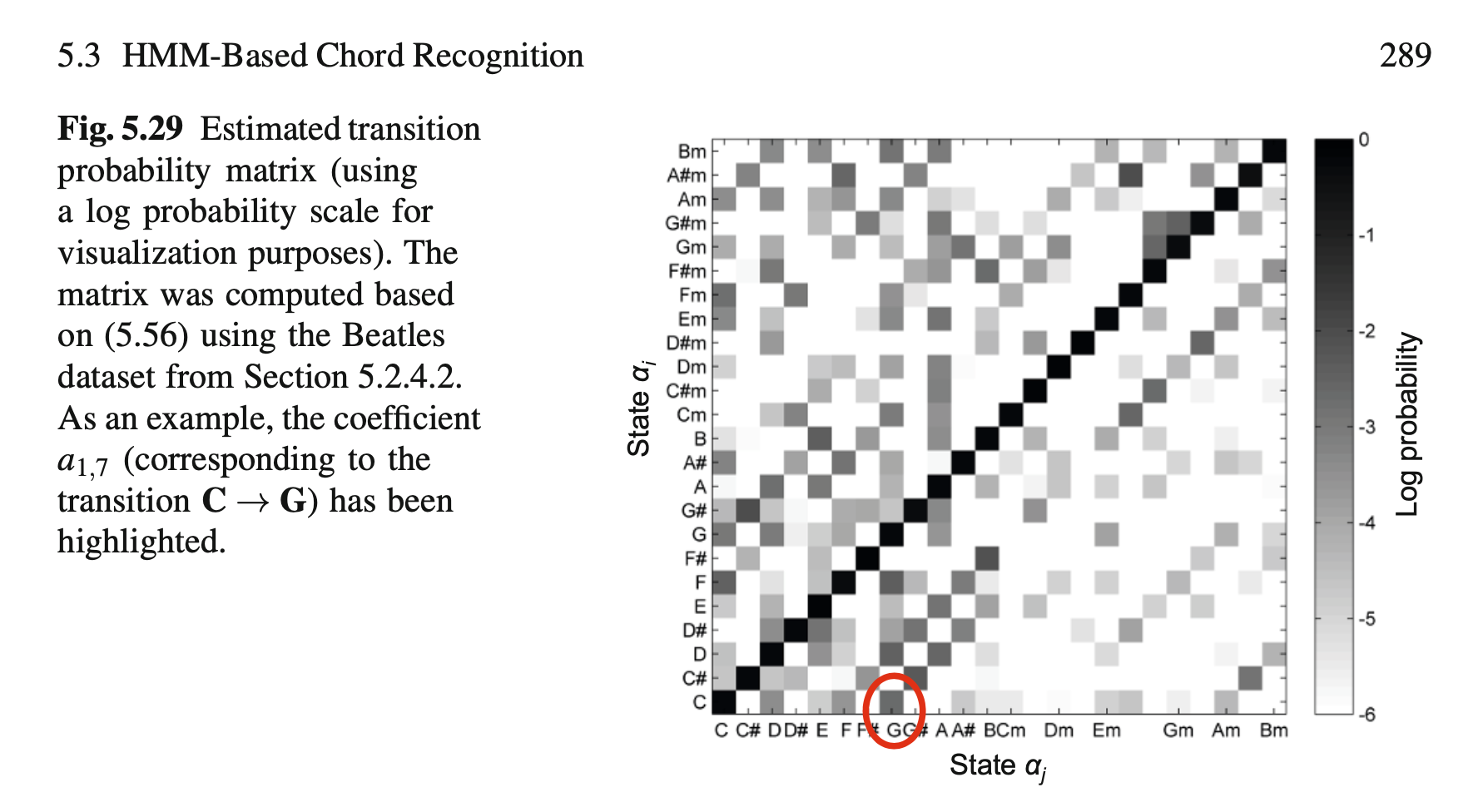
可以看出,除了自身转移以外,和弦C转移到G的概率最高,这也符合大众乐理认知和审美。
当然前面已经提到过了,这样做的前提是准备好正确标注的学习库。遇到学习库残缺不齐的情况怎么办?现代音乐充满了大量相似、滥用的和弦进行模版(比如卡农),比如1000首歌里只学到了90%的和弦转移情况,还有10%的小众和弦转移怎么办?
书上介绍了这个方法:cyclic chroma shift:

其实理解起来很简单,就是在一个12平均律的圆周上平移chroma ...

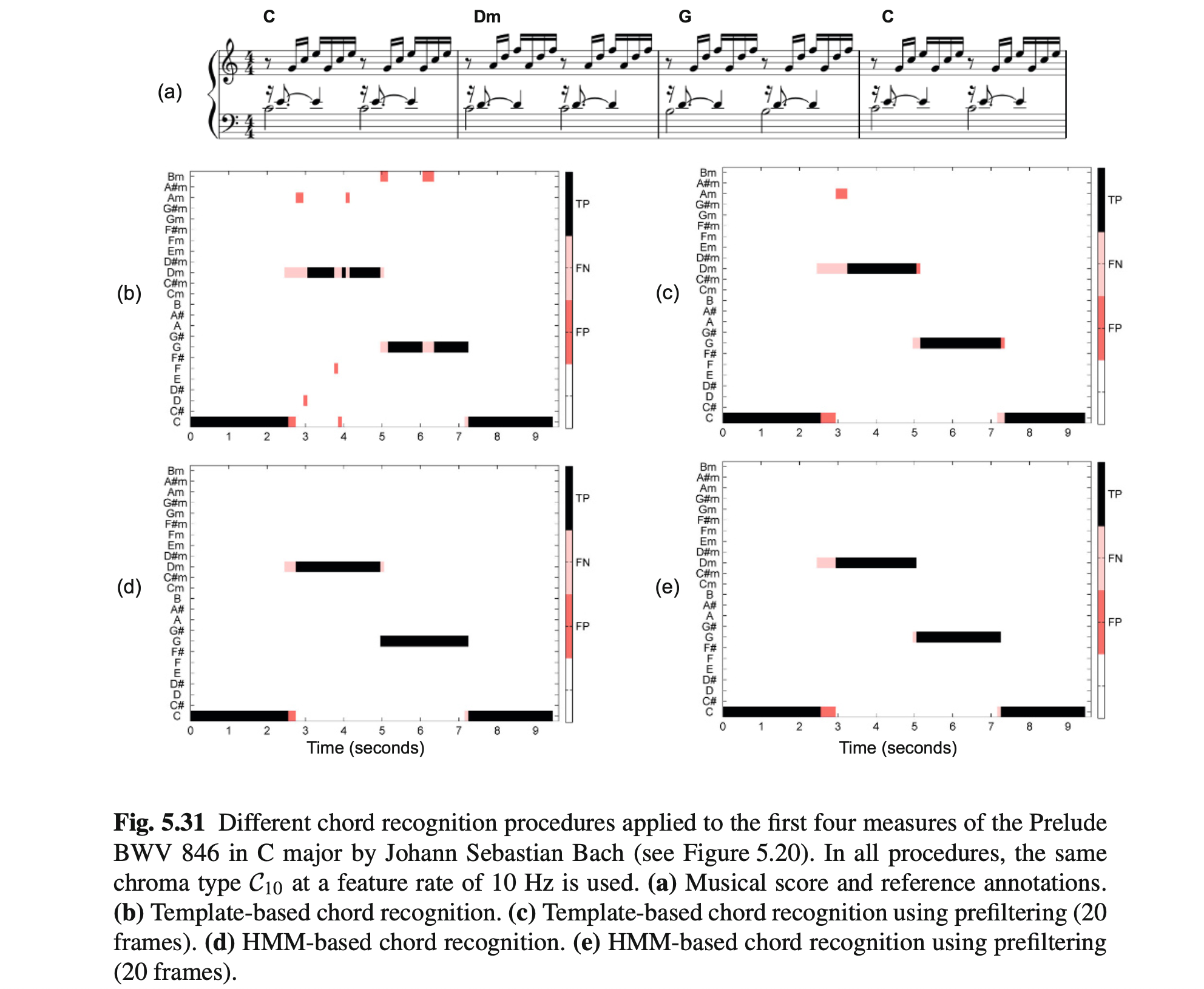
chord recognition: prefiltering和postfiltering的选择和对比
回顾chord recognition本身
首先把结论写在最前面:一个识别效果优秀的chord recognition程序可以没有prefiltering,而且往往没有prefiltering . 很多时候单独使用postfiltering的效果要优于prefiltering + postfiltering.
话说回来,什么才是Postfiltering?HMM和基于模型的传统chroma识别多多少少有一点点功能上的冲突(到底该听谁的?),那么《Fundamentals of …》一书是如何将HMM模型投入chord recognition流水线上的?
需要阅读P290: 5.3.4.3 Effect of HMM-Based Postfiltering
首先还是看到这条chord recognition流水线:
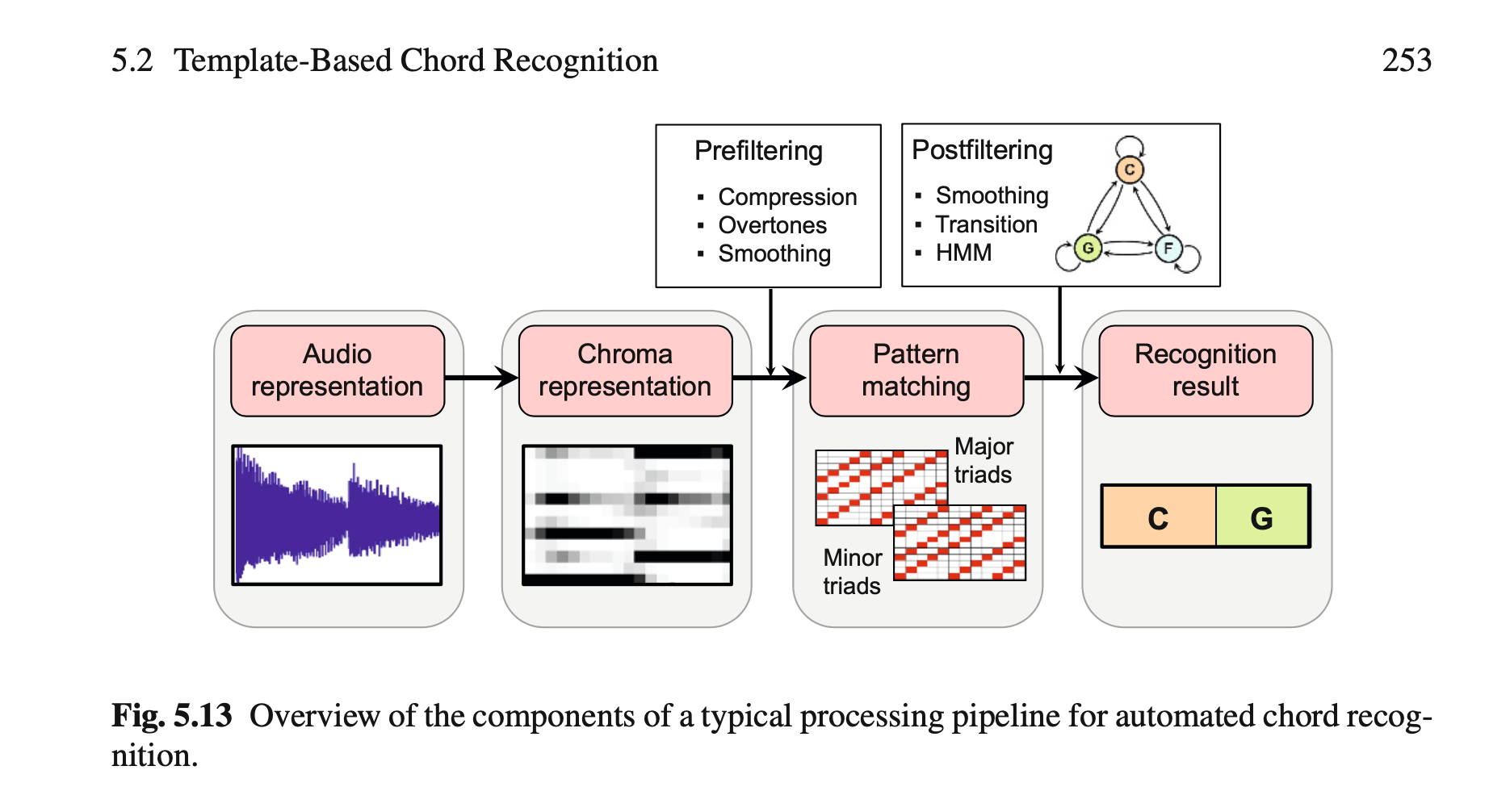
首先,目前接触到的任何prefiltering算法,都是类似“压缩”、“平滑”、“线性插值”这样的简单算法。
这些prefiltering算法往往有一个很大的缺点:
This not only smooths out noise-like frames, but also washes out characteristic chroma information and blurs transitions.
《Fundamentals of …》P291
而postfiltering会原封不动接受所有原始音频处理带来的细节,没有人为的平滑处理!所以在《Fundamentals of …》一书中,「仅使用postfiltering」 > 「使用prefiltering和postfiltering」 > 「仅使用prefiltering」 > 「什么都不使用」。
对错误识别的容忍程度
复习文章的时候发现了过去笔记里的一段话:

这个问题可以这样理解:
首先,就目前来看,HMM识别相关的论文应该识别的不是单个音符,而是更上层的音乐结构,比如chord, beat .
其次,就算是识别chord,也比语音识别的建模更简单得多,为什么还会有很多优化空间?

我们注意到这个很严重的问题:在识别和弦的时候,稍微偏差一点点而导致的识别错误,很有可能在音乐领域是一个无法理解、无法容忍的错误,比如莫名其妙的半音和弦转调(这种和弦转调正常音乐节一辈子都不会写出来)。
相对来说,语音处理和文本阅读的容错率可能会更高一点,比如:
「你今天吃饭了煐吗?吃了多少竔?好翙不好吃?」
而在音乐识别领域可能需要更为严谨的结果,比如这张对比图:
可以看出,template-based chord recognition的错误率还是太高了,这样会导致对音乐的进一步分析出现严重偏差。
