 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2021-09-29. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.主要内容:Bayesian Linear Regression / 贝叶斯线性回归
b站机器学习(见下面的链接)学习笔记:https://github.com/ws13685555932/machine_learning_derivation
网上找的一个cheatsheet: https://static1.squarespace.com/static/54bf3241e4b0f0d81bf7ff36/t/55e9494fe4b011aed10e48e5/1441352015658/probability_cheatsheet.pdf
最小二乘估计 / least squares method
https://zh.wikipedia.org/zh-hans/%E6%9C%80%E5%B0%8F%E4%BA%8C%E4%B9%98%E6%B3%95
最小二乘法只有在因变量服从正态分布时才能用吗? https://www.zhihu.com/question/55084299
为什么一定要使用[mathjax]x^2[/mathjax],而不是[mathjax]|x|[/mathjax]或者其他的方法作为最小二乘估计的计算方法?http://www.atyun.com/29890.html
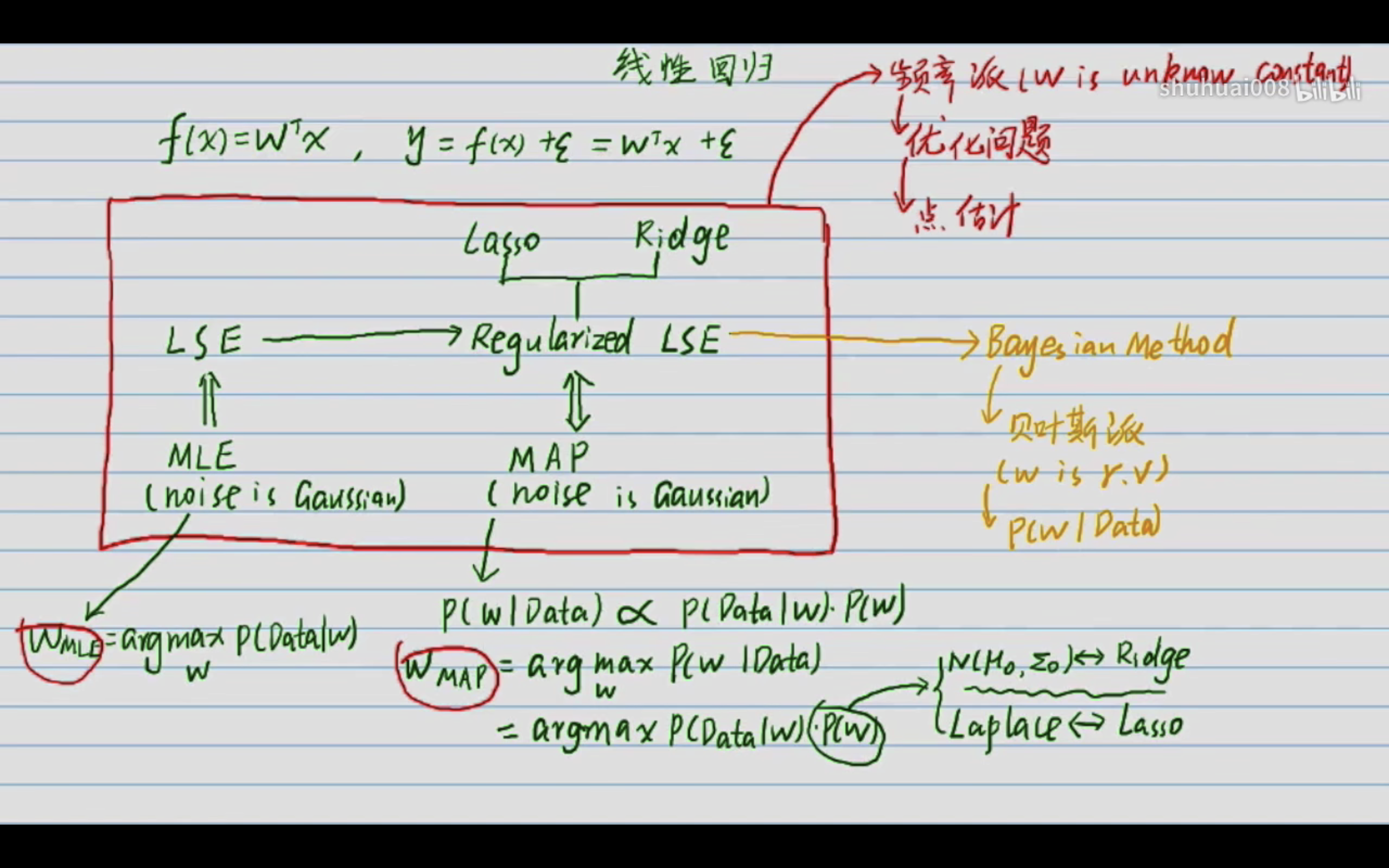
Bayesian Linear Regression的前导---LSE(见同篇文章后续的这张图片)
线性回归---最小二乘法估计
一个完善的理论slide:https://education.illinois.edu/docs/default-source/carolyn-anderson/edpsy584/lectures/MultivariateNormal-beamer-online.pdf
一个入门讲解视频:https://www.bilibili.com/video/BV1hW41167iL
[mathjax-d]L(w)=\sum_{i=1}^{N}\left||w^{\top} x_{i}-y_{i}\right||^{2}[/mathjax-d]

least squares estimate of normal distribution 正态分布的最小二乘估计
Conditional Probability with the Normal Distribution / 多元正态分布的条件概率 / 多元正态分布 求解函数概率密度问题
https://www.youtube.com/watch?v=-KjA-MFeZ2A 印度老姐的通熟易懂入门讲解(例题视频)
首先是一个更简单的例子:(搜索引擎关键词)conditional probability of bivariate normal distribution
一个附带了简单例题的链接:https://blog.csdn.net/omade/article/details/28408663,具有非常详细的推导公式
类似的链接:https://zhuanlan.zhihu.com/p/364942187
https://blog.csdn.net/omade/article/details/28408867
有2种不同的方法(求出相同的结果):LSE或者gussian
例题:http://www.stats.ox.ac.uk/~steffen/teaching/bs2HT9/gauss.pdf 见最后的example
岭回归与Bayesian Linear Regression之间的关系
【贝叶斯方法与Ridge回归的联系】https://blog.csdn.net/Analy101/article/details/110506479
【Is Bayesian Ridge Regression another name of Bayesian Linear Regression?】https://stats.stackexchange.com/questions/328342/is-bayesian-ridge-regression-another-name-of-bayesian-linear-regression
【岭回归的统计学解释】https://blog.csdn.net/gaoxueyi551/article/details/90751477
Bayesian Linear Regression的简单入门介绍
https://zhuanlan.zhihu.com/p/303368534 不是非常适合入门
https://www.bilibili.com/video/BV1St411m7XJ 入门视频,内容如下:



Conditional Probability

Model selection: evidence maximization
基本介绍和定义:https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm
【【机器学习】EM——期望最大(非常详细)】https://zhuanlan.zhihu.com/p/78311644
EM和MAP / MAP with hyperparameters的关系:
🔗 [有关MAP、ML和EM的个人理解 - handspeaker - 博客园] https://www.cnblogs.com/hrlnw/archive/2012/11/18/2776599.html

hyperparameters的介绍:https://en.wikipedia.org/wiki/Hyperparameter_(machine_learning)
协方差矩阵的特征值和特征向量
