 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2023-04-02. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.2年多了,差点就想把这篇笔记埋了,但最终还是去花时间看了一眼以前的代码并重新学了一遍KNN
原始问题:去年学knn的时候手写的代码,跑digits和iris数据集的正确率永远比sklearn低个2%到5%. 我一直以为是代码少了某个优化环节(不然怎么只低了这么点?)
置顶最终结论:我写的KNN算法并不是某个地方有瑕疵,而是最关键的“投票决策”代码逻辑是错的(无论k设置为多少都相当于k=1)。
为什么完全错误的逻辑最终只比sklearn的正确率略低一点?因为k=1对于很多长得好看的sklearn自带数据集够用了。
接下来是学习的全过程:
一开始不知道问题能不能马上解决,所以代码丢给gpt看,gpt指出了问题(是正确的),重新跑代码以后发现正确率和sklearn一样了,所以决定开始认真学一下这是为什么
先找出一篇经典老文(第一次学knn的时候看的就是这篇):🔗 [机器学习实战教程(一):K-近邻(KNN)算法(史诗级干货长文)] https://cuijiahua.com/blog/2017/11/ml_1_knn.html
截取一些关键截图(看这些就够基本knn了):
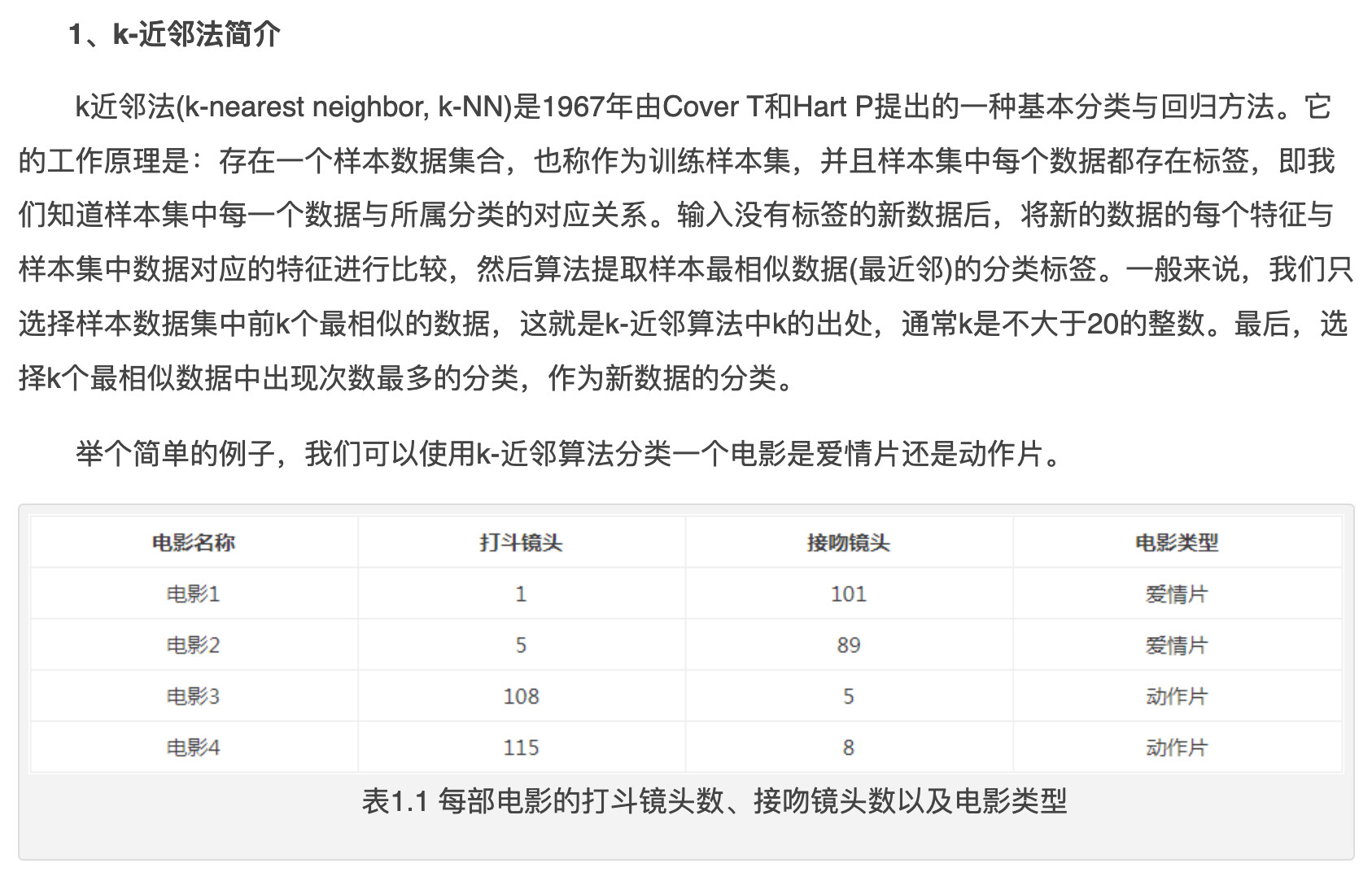

已知我有105个【已知类别的】训练数据(一共3类,0/1/2):

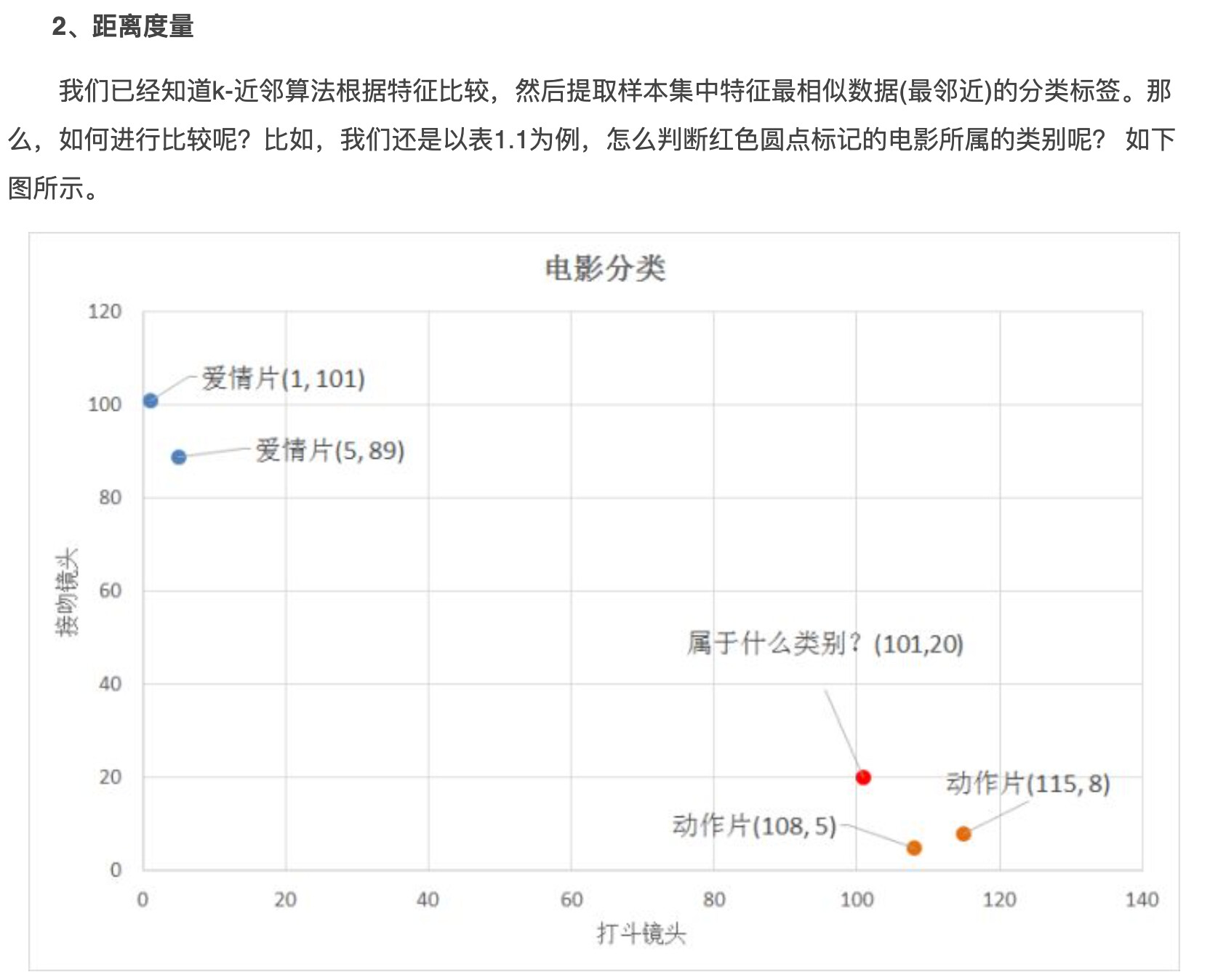
现在我有一个新数据要判断类别。
我会首先建立这个新数据到这105个已知标签的数据的距离(一共150个距离):

然后假设我的k=3,我就挑出距离最近的那3个点:
距离最近的3个点的index:[53, 95, 58],也就是原始数据data中的data[53], data[95], data[58],对应2, 1, 1接下来应该就是投票了:由于投class=1的有2个,投class=2的有1个,虽然这个点距离class=2的一个点(data[53])最近,但接下来2个次级点都投了class=1,所以最终也是class=1
但我的代码出了点问题,并没有去对[2, 1, 1]投票,而是去对[53, 95, 58]投票了,[53, 95, 58]其实都是一堆不重复的索引当然不会有什么有意义的投票结果,但代码规定必须投一个所以就投了默认的第一个53,最后把53对应的class=2当成了最终结果。
总结起来就是,我的错误代码相当于恒定k=1(从一堆训练数据中找出距离最近的那个点的class作为预测结果),本质上就是距离谁最近就认定自己数据哪一边,所以相比于sklearn(使用sklearn iris+digits dataset):
在k=1的时候预测正确率完全相同
在k>1的时候正确率略低2%~5%
这么离谱的代码为什么还能得到相当高的准确率(比如对于iris dataset,我的准确率也有个95%~98%,而sklearn是100%)
是因为iris dataset的3簇数据本身就区分得很开,很容易让你做对。
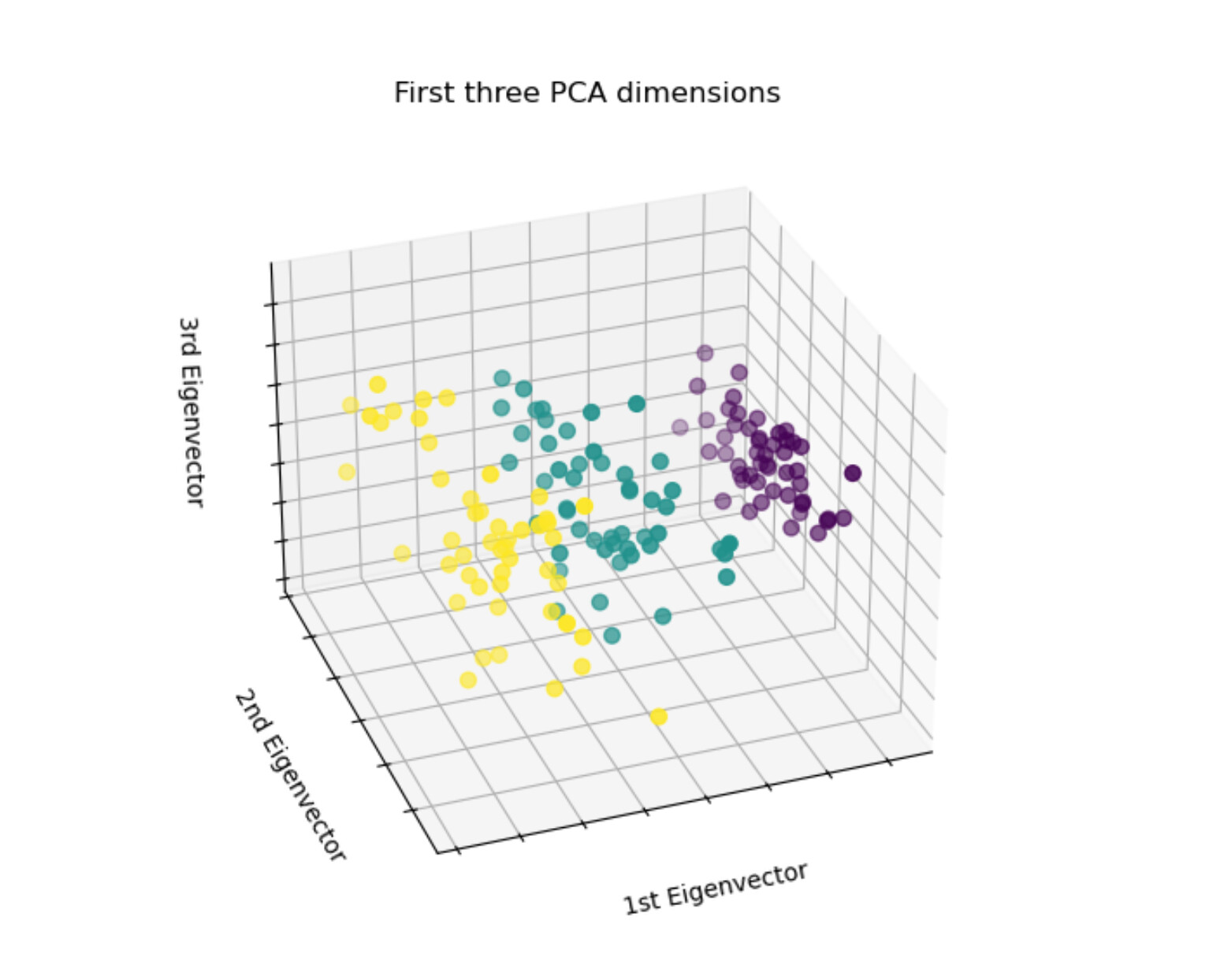
以上面的图为例,紫点基本上都抱团。我随便从紫色点里面取一个点预测(用剩余的数据训练),结果发现离这个点最近的就是紫色点,我的错误代码(相当于k=1)马上就判定它为紫色,实际上对于iris dataset而言也基本不会错。
错误代码:

正确代码:

