 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2023-11-07. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.🔗 [Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus?] https://www.nber.org/system/files/working_papers/w31122/w31122.pdf
Horton, John J. Large language models as simulated economic agents: What can we learn from homo silicus?. No. w31122. National Bureau of Economic Research, 2023.
The basic idea about this paper:
LLM models can be used to help simulating social science studies. By assigning endowments, information, preferences, etc, LLMs can be used as Homo economicus. By comparing the results from LLMs with several economical experiments, showing that LLMs simulate real human quite well, plus a much border space to conduct further experiments.
The above paragraph mainly comes from the abstract and the overall content of the paper.
Basic experiment method
- Buy OpenAI GPT API
- Assign basic infomation(endowments, information, preferences, etc) by using prompt-engineering input
- Ask LLM economical questions (the first three questions have historical experiments and results; the fourth experiment is inspired by a true field experiment). Note that the author may ask LLM further insightful (variant) questions, compared to the original experiment.
- Compare the answers to these questions' original experiments. In short, compare LLM answers to real human answers. Note: the author also conducts some experiments in different GPT-3 models (more advanced davinci−003 and prior {ada, babbage, currie}−001)
- Deriving conclusions
Data
Economical questions, and their original experiments' results
Tool
OpenAI GPT API
Experiments and Results
The paper uses several famous economical experiments:
1: A social preferences experiment: Charness and Rabin (2002)

Some interesting insights from the experiment result:
- In this experiment, LLMs can't have similar results to the original experiment. This is not surprising to the author; instead, the author accepts the result, and summaries a possible way to conduct the remaining experiments (see below).
- Different generations of LLMs have significant difference.
- Even endowed with specific characteristics, sometimes LLMs can still not listening to the command. cite
From this experiment, the author thinks of a way to do the next experiments:
Since the characteristics of LLMs can't be strictly controlled (at least until experiment 1 in the original paper), we can first do many experiments using many LLM conversations, then summarize each conversation's "characteristics" and use the overall LLM conversations charactierstics distribution to do the following experiment. cite
2: Fairness as a constraint on profit-seeking: Kahneman et al. (1986)
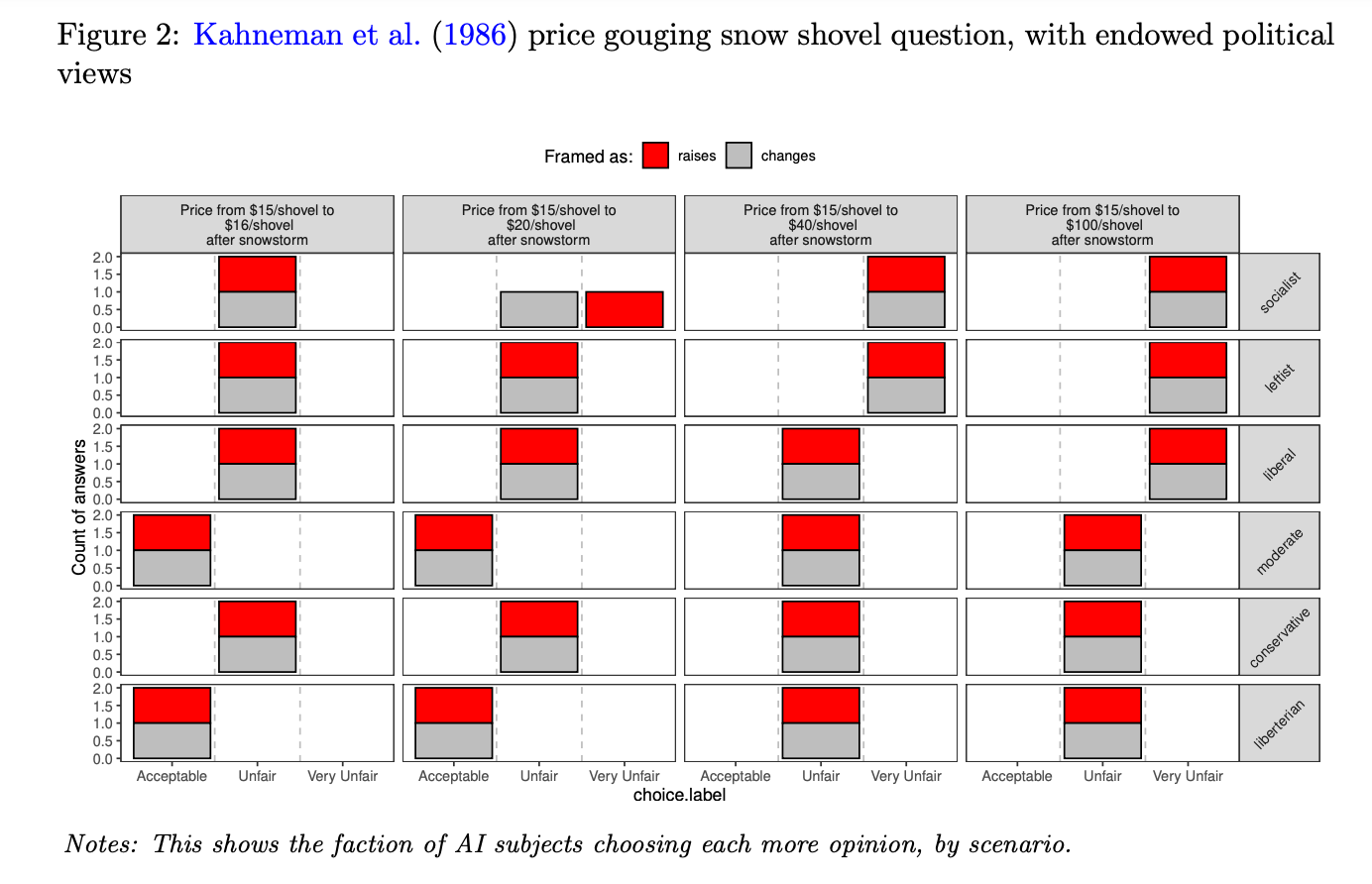
Explain about the "raises"/"changes" difference in the above figure:

Some interesting insights from the experiment result:
- The author conducts more experiments compared to the original experiment.
- Compared to 25-years-ago's experiment, although LLMs do not accurately re-produce the same propotion of original results, there are still some insightful observations: (1). There are some explains about the concept changes over the years. cite (2). This experiment shows that LLMs producing explorable results when endowing with different political views and questions.
- The experiment also conduct different framing terms to test if LLMs are sensitive to framing. (the result is: in this experiment, almost 0 sensitivity). This is different compared to experiment [3].
3: Status Quo bias in decision-making: Samuelson and Zeckhauser (1988)
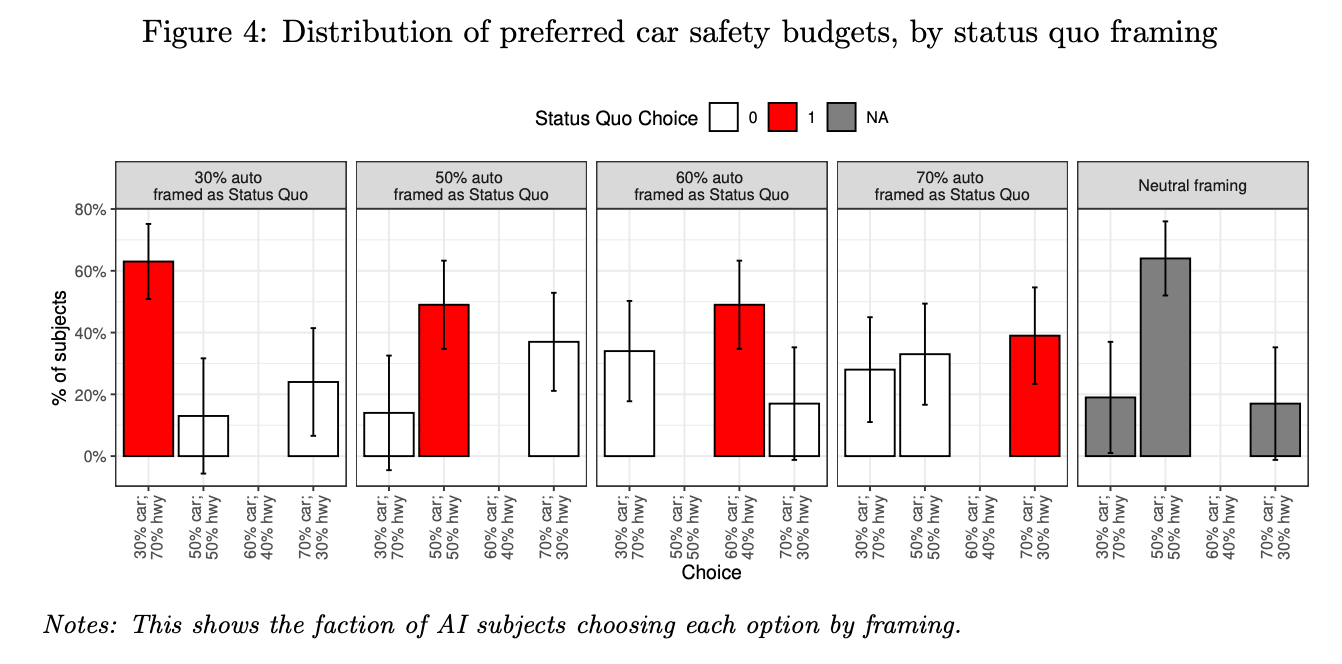
Some interesting insights from the experiment result:
- The experiment can be regarded as an "opposite example" of experiment [2], since this experiment shows how LLMs treat "framing" in decision-making scenarios.
- In experiment [2], "framing" seems to have near 0 effects. However, in this experiment, "framing" seems to have significant decision-making effects.
- The author does not strictly compare the experiment result to the oiriginal.
4: Labor-labor substitution in the presence of a minimum wage: Horton (2023)
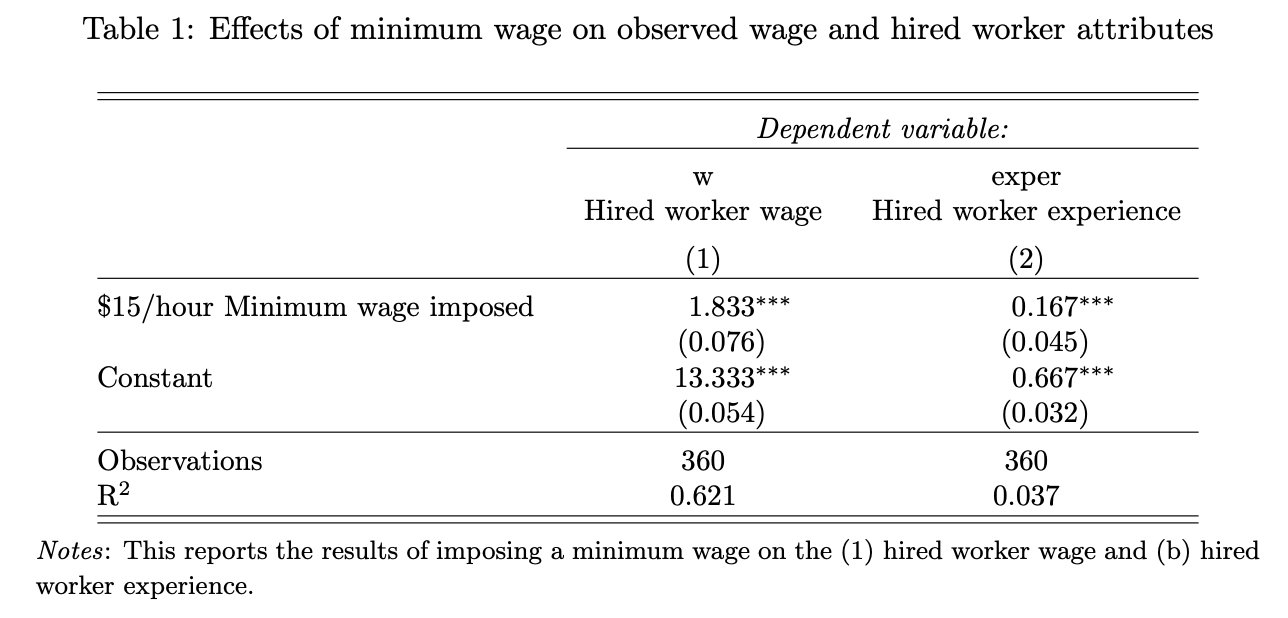
- The author does not strictly compare the experiment result to the oiriginal. However, the author thinks LLMs results are reasonable and consistant to the experiment's inputs. cite
Conclusion:
(From the author) Use LLMs to replace real human surveies is a good choice. It's low-costing, quick, convenient, and does not involve ethical concerns.
My personal view after reading the results of four experiments: it's convenient to use LLMs to produce a variety of different scenarios, so long as LLMs respond meaningful difference with different framings. Choosing meaning framings is important when choosing LLMs rather than random or hard-coding selection, because we are expecting LLMs to parse scenario differences from those framings.
My ideas after reading this paper:
- Framing is the key reason when introducing LLMs in the existing research project.
- We can tear-down experiments into many steps, to build LLM's characteristics, or, to get the distribution of LLM's characteristics. (from experiment [1]). Since sometimes the LLMs are hard to control, and they are not always listen to the prompt.
- This is one of the ways to involve LLMs to existing research project. For another idea, I plan to read 🔗 [[2310.02207] Language Models Represent Space and Time] https://arxiv.org/abs/2310.02207
- Due to the tremendous changing in LLM area, I may need to involve actual GPT API coding in order to learn better prompt engineering. This is important, because building trust to LLM models is another challenge.
