 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2024-07-09. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.Table of Contents
总结
下面的两个目录,“多一个常数列”和“one-hot的时候drop_first“本质上是两个话题。虽然它们的结论差不多,但它们本质上并不一样!get_dummies的时候无论是否drop_first,得到的df都不是“多一个常数列”的那种情况。
多一个常数列
不会有任何影响,或者说这个常数列应该被去掉
🔗 [handling constant columns in machine learning - Data Science Stack Exchange] https://datascience.stackexchange.com/questions/109458/handling-constant-columns-in-machine-learning
🔗 [DropConstantFeatures — 1.8.0] https://feature-engine.trainindata.com/en/latest/user_guide/selection/DropConstantFeatures.html
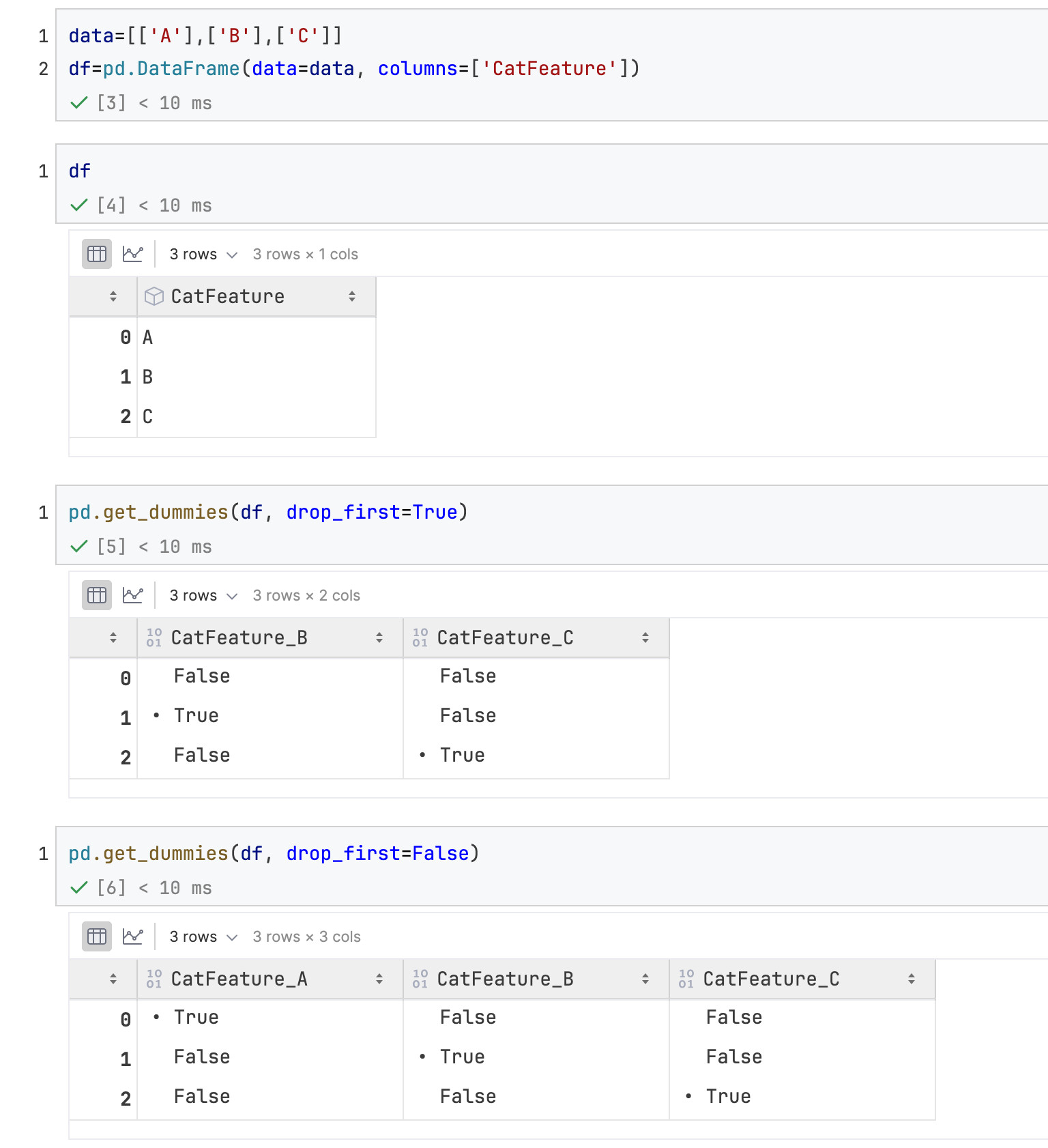
get_dummies(drop_first=True/False)
问题:pd.get_dummies(drop_first=True/False)是否会带来不同的结果
drop_first的效果如下:
先放一个gpt的【推荐】

上面这个只是【推荐】,并没有明确说明【(相同的数据)drop_first是否会影响最终模型的准确率】
先放出最终结论:(使用drop_first与否)理论上不影响模型准确率,实际代码里还是会有一点点点点影响(比如random forest);但一定会影响linear regression模型的coefficients
其他的(logistic regression,xgboost等)就不测了
代码是GPT写的:
Last Modified in 2025-08-03
