 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.和perma-cache无关,和Cloudflare R2/AWS S3类似。
大概是第一次学习存储桶/对象存储,之前一直没机会学这个

更便宜的还有backblaze(配合bunny CDN一起使用),但目前暂时不需要考虑这个(而且blackblaze主要是提供存储,cdn什么的不是他们家的主营)
用途1:大文件存储桶。实际上本站也用得上(大视频存储),这样就不用另外买个大盘鸡了。
比如一堆GB级别的.zip文件需要分享,
不用存储桶的话就要上大盘鸡,然后cloudflare(可能会被封,因为静态内容太多,和html不成正比),或者裸机直连(流量可能不够用,网络设备也跟不上),这个时候可以用廉价的bunny storage (HDD)和volume CDN(便宜):
先创建一个storage zone,名字随意,把文件传上去
然后去创建一个cdn pull zone,名字也随意(注意不要大写,因为cloudflare cname dns自动小写,然后大小写不一致就无法验证申请ssl证书),创建的时候基于那个storage zone创建
到这一步就已经可以通过b-cdn.net访问存储桶里面的文件了,要想换成自定义域名,比如static.example.com,就去添加hostname:添加一条cname解析指向xxx.b-cdn.net,然后验证SSL证书
最后force SSL即可。
这样就能分发大型静态文件了。注意上面的步骤不包含token鉴权,所以这个存储桶本质上是公开的。存储桶公有私有这种事情往往和各种账单爆炸流量爆炸有关,比如🔗 [How an empty S3 bucket can make your AWS bill explode | by Maciej Pocwierz | Medium] https://medium.com/@maciej.pocwierz/how-an-empty-s3-bucket-can-make-your-aws-bill-explode-934a383cb8b1
考虑到bunny至少有1美元/月的开销,所以把很多小型静态网站丢上去(作为临时展示)或者临时给一群人提供个文件下载还是很好用的。非常便宜!
但本博客...还是算了吧(至少html和图片目前是这样)。以后最多把一些特大文件(视频、工程文件、压缩包等)扔上去。
然后学了一会存储桶的token鉴权。用gpt学了一会也学会了。存储桶可以加入自定义的params以实现精准控制。比如精确控制这个url分给某个人,生成token的过程中就会包含这个人的uuid(是必须包含,因为uuid参与了sha256 hash计算,去掉/修改uuid会403),生成的完整url也包含这个人的uuid. 就算其他人偷了这个人的私密url并下载了文件,也可以在cdn访问日志中发现不对劲(多个完全不同地方的ip都用这个人的uuid下载了文件),然后就可以手动撤销/重新生成新的url.
下载大文件搞定了,马上第一反应就是能不能上传纯静态网站(临时展示用)
当然可以,比如hexo,但avif/webp的问题又出现了(虽然说大多数时候完全可以不考虑这个问题,因为目前纯静态网站在我这里只有临时展示用)
之前在perma cache的场景下就被bunny的avif/webp文件命名策略搞得头疼:要用户实际通过https访问以后才能在对应的目录下获取(正确命名的)avif/webp文件变体。但这里的静态网站是存储桶而不是nginx服务器,怎么办?
从这篇博客里学到了avif/webp的原始html用法:(博客原文的代码用起来有点问题,实测下来需要加点别的,见下)
<picture>
<source srcset="r2.jpg.avif" type="image/avif">
<source srcset="r2.jpg.webp" type="image/webp">
<img src="r2.jpg">
</picture>这里面的type="image/avif"声明是必不可少的
然后准备3份文件(jpg, webp和avif),丢到bunny storage里面正确的路径即可。
因为不同文件名对应的一定是不同的图片文件,所以vary cache不用选:
注意:选取standard(HDD)存储的时候可以选择离自己比较近的那个存储点方便上传,选取SSD存储的时候就只有默认的法兰克福数据中心
关于同步/上传文件:
考虑到FTP不安全,所以下面默认排除FTP
目前看来bunny storage还不能像github pages - github repo那样通过git/rsync那样一键的方法镜像同步一堆小文件。官方的文件上传api只支持单个文件,一般用来上传视频什么的很合适,但对于一堆小文件的静态网站目前看来只能写个脚本,扫描每个文件,然后逐一操作。
试了下同步hexo:写了个脚本操作,还行,至少不需要手动创建目录(也就是说如果你在空目录下直接上传一个./subdir/subdir2/subdir3/file,前面的目录会自动创建好)。上传操作是直接覆盖的,所以也不需要每次手动清空存储重新上传。还行。对于其他需求(比如只上传修改过的文件)就以后再说了,现在是真的没有这个需求(目前并没有考虑把本博客搬到静态网站上面去)。
2025-11-12
freefilesync也成功了,步骤如下:
1, 可以用sftp,步骤和ftp是一样的
2, 一定要关掉这个,否则文件无法正常上传(因为无法重命名存储服务器的freefilesync tmp文件):
3, 目前作用仍然有限(bunny storage对sftp指令支持得不够好),不适合大文件的上传,适合小文件(比如hexo网站)的同步(已经上传过一次了,想要同步那些最近修改过的文件)
4, 由于文件同步过去以后的last modified date是修改过的,所以只能用file size进行比较(用file content也可以,但太浪费带宽了),这样一来就不够保险(万一有个文件只是修改了一个字符...)
2025-12-08补充:
可以使用LFT:🔗 [LFTP - sophisticated file transfer program] https://lftp.yar.ru/ ,这样就不用手写那些麻烦的同步指令了!
等待后续补充使用体验
对比大盘鸡
hosthatch $5/月,1TB硬盘,2.5TB流量
如果上面的消耗完全折算到bunny storage + cdn肯定要比$5贵很多了(即使是单点存储+volume tier CDN)
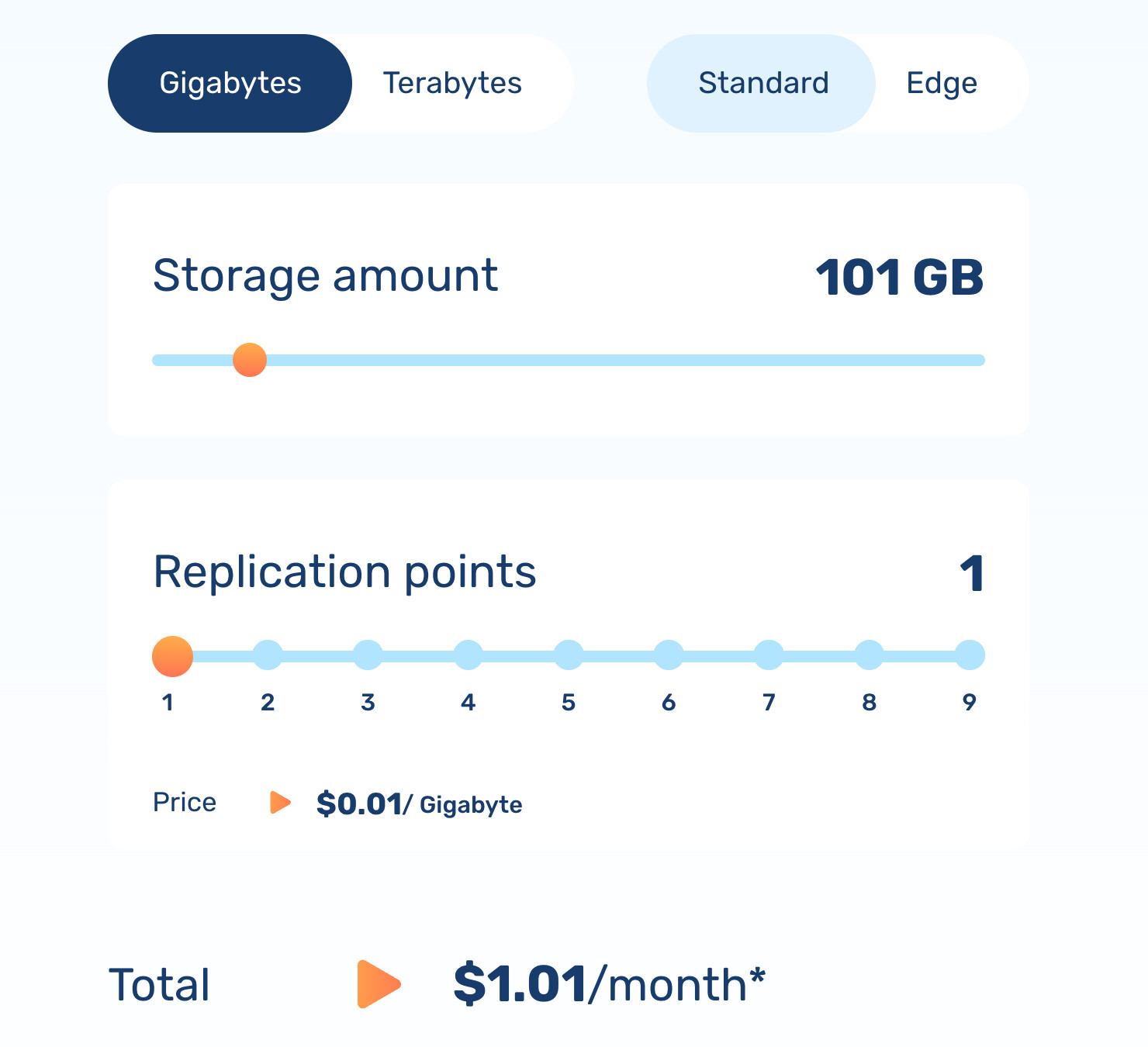
100GB存储+200GB流量=2刀/月
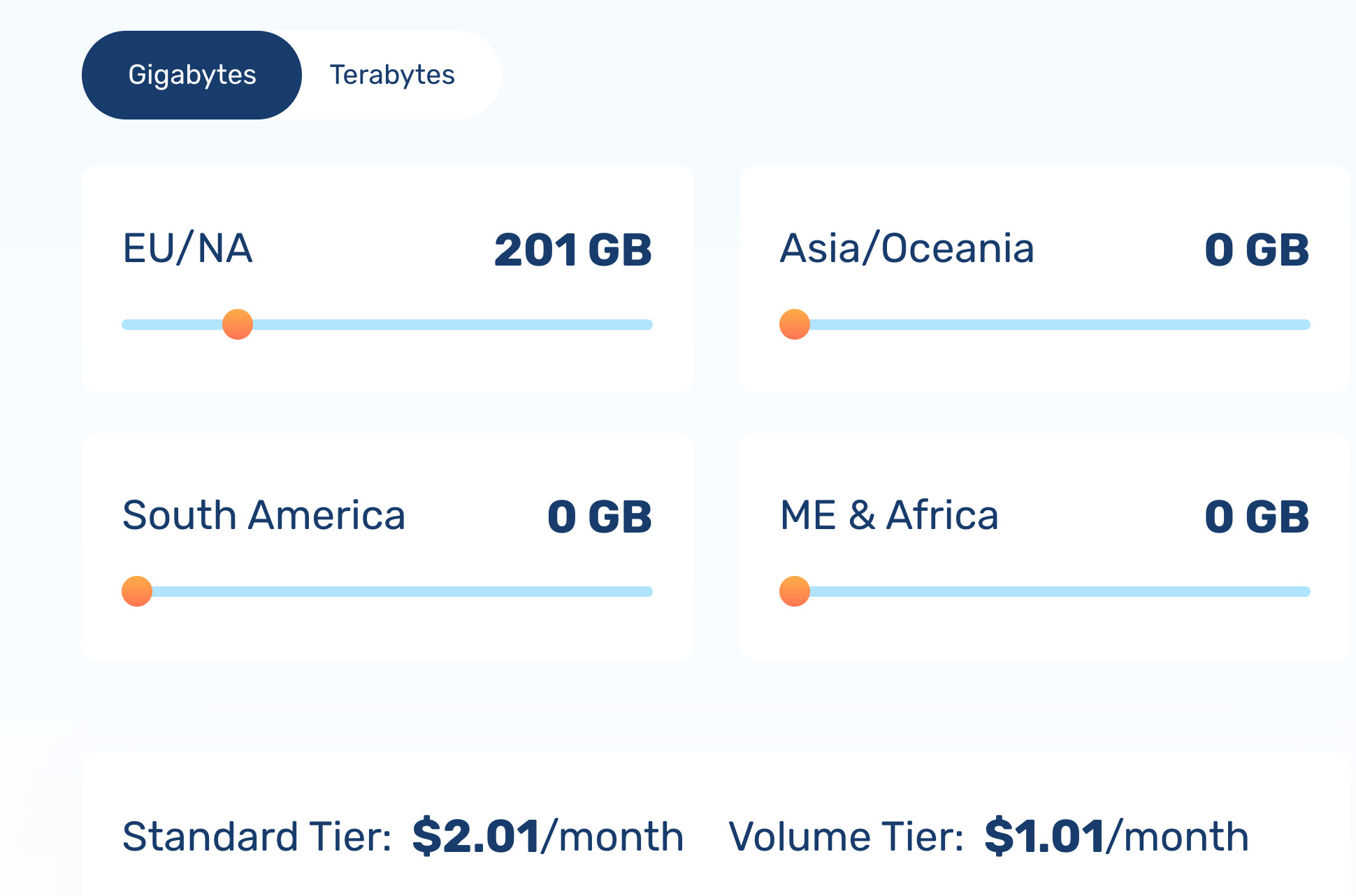
但这些资源(1T硬盘+2.5T流量)又不太能完全用完,而且CDN相比大盘鸡还有CDN自己的优点
所以(bunny)如果实际用量 <= $1/月还是挺好的
还是不太对,如果用proxy_pass+bunnyCDN+bunny storage,那就锁死了只需要存在LAX的那一份,流量也肯定都走lax volume节点,cdn的其他地区是完全用不上。那还算cdn吗?
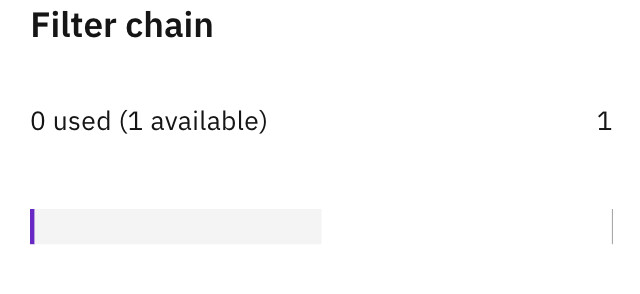
或者搞geodns分流,但目前懒得搞国内A记录+国外cname的那种模式(需要1条filter chain规则,目前懒得搞)
除了那种1TB级别的大盘鸡,还有很多中等量型的大盘鸡(100~200GB)可以选择:
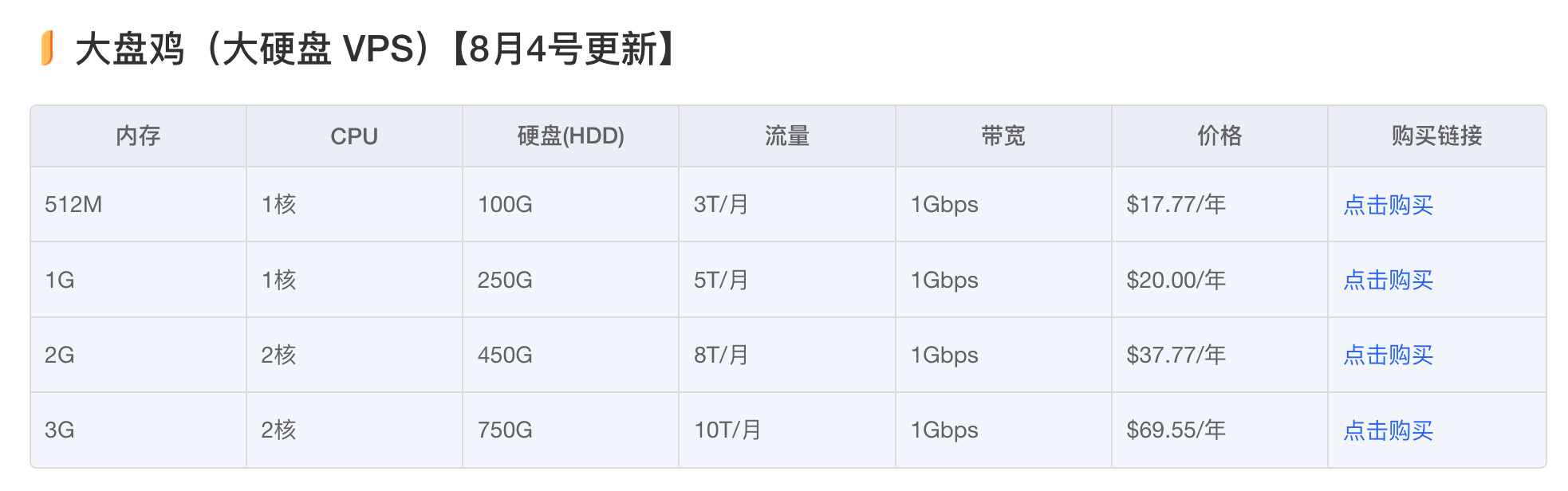
可以先用中盘鸡,等什么时候dmit流量撑不住了再换成dns分区解析(A + cname)
2025-11-19
(这几天在学next.js/react/SPA/SSG这些)
next.js生成的SSG当然可以直接丢到bunny storage里面去当网站用;
如果是SPA呢(貌似bunny storage没办法像nginx那样写个try_files配置)
也是可以的(或者说amazon s3/azure blog这些对象存储都提供了类似功能):
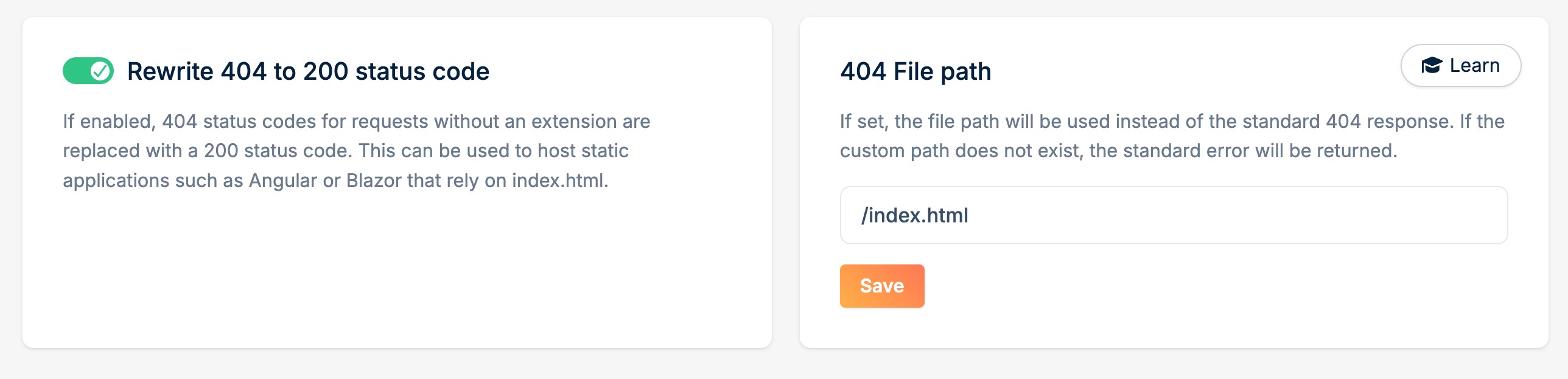
把右边的404 file path配置好了以后其实就已经能跑SPA项目了,只是访问router path的时候dev tools会显示这个路径404(404,但仍然返回了根目录的index.html),把左边的rewrite 404选上以后dev tools也不会有红色404请求
