 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2025-06-18. Obviously, expired content is less useful to users if it has already pasted its expiration date.
Table of Contents
用途
word实际上自带一个 Reduce File Size 功能,但部分优化参数、优化细节不可控,有的时候还是想要一个能自己可控的优化程序。
作用1:压缩本地docx/pptx文件体积,尤其是那种粘贴了一大堆原图的PPT,顺便,由于🔗 [MacOS Microsoft Word.app编辑大文件时对硬盘并不友好 - Truxton's blog] https://truxton2blog.com/mac-microsoft-word-disk-io/,还能节约不必要的硬盘IO开销。
有的时候如果不想优化全部图片,可以选择性地处理少数几张图片,然后把docx/pptx打包回去继续编辑。
作用2:Google docs限制单个文件大小50M(这条限制可能过时了,我有一个超过100M的Google Docs文件依然能正常编辑),如果一个google docs文件因为大尺寸图片过多的原因超过了50M,可以通过 下载docx-优化docx-重新上传-重新转换为google docs 的方法给文件续命。
online word(也就是office 365 sharepoint)(据文档所说)限制了单个文件大小为100M,如果真的有这个需求(即:docx大小超过了100M,但无法使用/不想使用word桌面版去编辑这个docx文件),也可以通过 下载docx-优化docx-重新上传 的方法给文件续命。
docx/pptx的解压和重新压缩
解压比较随意,命令行unzip, 7za或者随便找个什么keka这样的解压软件就能完成任务。下面主要讨论压缩。
关键步骤:🔗 [macos - re-zipped docx files don't open in Word - Super User] https://superuser.com/questions/411911/re-zipped-docx-files-dont-open-in-word
关键点在于打包的路径,要从一堆word解压文件的根目录(而不是包含了这些文件的上层文件夹)开始打包:
比如:
注意,压缩并制作完成的Archive.zip.docx首次被word打开的时候可能仍然会报错/警告(比如因为zip文件夹里包含了.DS_Store文件),这种错误word是能修复的(修复文件并另存为另一个.docx即可),但如果打包的基本结构有问题(比如没有从根目录开始打包),word是无法修复的。
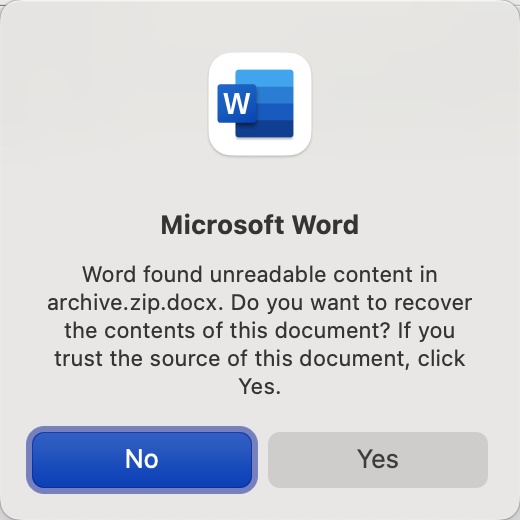
虽然上面的这个Word found unreadable content警告可以被word修复,但强迫症显然忍不了这一点,一开始我还以为是keka压缩参数的问题,所以改用了/usr/bin/zip命令:
- 用macOS自带的zip命令/usr/bin/zip
- 去掉.DS_Store和__MACOSX文件夹
综合起来就是(在.docx根目录下):
$ zip -r opt.docx * -x "*.DS_Store" "__MACOSX*"
或者
$ zip -r opt.pptx * -x "*.DS_Store" "__MACOSX*"这样可以规避.DS_Store带来的问题,但后来我发现Word found unreadable content警告仍然有几率出现,只是word都能修复它。最后我发现是word设置的问题,比如:由于种种原因,你的docx文件设置了“嵌入字体”,但实际保存的时候word并没有往docx压缩包里面添加正确的字体文件,而是添加了0字节大小的 font*.odttf . (这种字体策略不一致的问题可能来自不同版本/不同平台的word,或者来自Google Docs/Libreoffice这些非word程序).
实际上word压缩docx的压缩率仍然比macOS自带的/usr/bin/zip(默认参数)要低,比如你用/usr/bin/zip重新打包以后得到的docx是10M,用word打开然后修改一点点(加个空格什么的)然后再保存它,这个docx可能就变成了12M. 又或者你遇到了上面提到的“0字节大小的font*.odttf“问题(word再次保存的时候又会把>0M的字体文件给它加上),这些繁琐的word设置都可能让你新保存的.docx文件变得更大。但这些都属于无关紧要的问题,因为解压-重新压缩docx的目的是压缩图片(图片文件大小大幅度优化,且重新制作的docx文件没有出现严重错误)。
图片优化的思路(2024草稿)
接下来是jpg/png的优化问题。jpg还好说,全部丢给mozjpeg就可以。png稍微麻烦点,目前是2个思路:
思路1:png就用其他的png优化库(这样可以防止文档中出现的透明png样式被搞乱)
思路2:png也喂给mozjpeg(要确定这个文档里没有透明png的需求),但要同时改变各种xml文档中的字符串(从.png变成.jpg)
暂时实现的是思路2;2025年也实现了思路1.
遗留问题:如果一个docx被反复优化并反复添加新图片,那么留在docx里面的“老图”质量会越来越低。思路:可能要用exif进行标记。
遗留问题:pdf缓存问题:用脚本优化并重新打包docx以后,用word再次打开(优化后的文件)并另存为pdf,仍有可能导出一个巨大的pdf,这可能来自于word.app的缓存问题(内存缓存或者硬盘缓存)。解决方法:待续(重命名?)
遗留问题:png优化(目前没有实现这个功能,而是把所有png变成了jpeg,主要原因还是没有透明png这个刚需,不想去花时间挑选以及测试那些png优化库)
2024-11-22更新:
完全一样的程序还可以作用于.pptx文件!很多时候pptx更需要优化,因为图多
但有些pptx会用到透明png的特性(比如logo展示),所以要注意png的处理是否恰当
图片优化(成品python代码)
2025-06-18,我终于想起了这个项目还没收尾。事实上过去一年我一直在用上面的思路制作的半成品(只能处理jpeg的python程序)来压缩docx/pptx,效果很好。对于极少数透明png,我的做法是在程序压缩完毕以后直接手动把这些透明png添加回去。
现在终于加入了pngquant把程序收尾了。总体思路如下:
- pngquant可选。如果文档里没有透明png的需求:所有jpeg/png都会用mozjpeg变成压缩过的jpeg;如果文档里有透明png的需求:jpeg使用mozjpeg压缩成jpeg,png使用pngquant压缩成png(保留png的透明特性)。
- mozjpeg可选压缩比,一般我习惯用85;pngquant暂时没有引入额外参数
- 使用exiftool对优化过的图片进行exif标记:优化后的图片会带有 {"Keywords": ["docx_opt"]} ,同时程序会自动跳过带有这种标记的图片(防止一张图片被反复压缩)
代码如下(部分代码是gpt给的,很多代码写的很烂比如检查 [Content_Types].xml 的代码,但是懒得改了):
注意:需要exiftool, mozjpeg, pngquant的运行程序( /PATH/cjpeg-static , /PATH/pngquant , /PATH/exiftool )以及python-exiftool.
import os
import sys
import codecs
import argparse
import exiftool
def set_exif_tag(file_path):
with exiftool.ExifToolHelper() as et:
et.set_tags(
[file_path],
tags={"Keywords": ["docx_opt"]}
)
os.remove(file_path + '_original')
def check_exif_tag(file_path):
with exiftool.ExifToolHelper() as et:
for d in et.get_metadata(file_path):
for k, v in d.items():
if k == 'IPTC:Keywords' and 'docx_opt' in v:
return True
return False
def try_utf8(filename):
# https://stackoverflow.com/questions/3269293/how-to-write-a-check-in-python-to-see-if-file-is-valid-utf-8
try:
file_str = codecs.open(filename, encoding='utf-8', errors='strict').read()
return file_str
except UnicodeDecodeError:
return None
def list_files(path):
files_path = []
for root, dirs, files in os.walk(path):
for name in files:
files_path.append(os.path.join(root, name))
return files_path
def mozcjpeg_in_place(img_path, quality):
os.system('/PATH/cjpeg-static -quality %d %s > %s' % (quality, img_path, img_path + '.tmp'))
os.rename(img_path + '.tmp', img_path)
print('optimize: %s' % img_path)
def mozcjpeg_png(img_path, quality):
os.system('/PATH/cjpeg-static -quality %d %s > %s' % (quality, img_path, img_path.replace('.png', '.jpg')))
os.remove(img_path)
print('%s -> %s' % (img_path, img_path.replace('.png', '.jpg')))
def run_pngquant(img_path):
# currently just use default options in pngquant
os.system(f'/PATH/pngquant {img_path} --output {img_path + '.opt'}')
os.rename(img_path + '.opt', img_path)
print(f'pngquant optimize {img_path}')
def replace_xml_file(files_path, original_str, new_str):
# https://stackoverflow.com/questions/17140886/how-to-search-and-replace-text-in-a-file
for file_path in files_path:
# Read in the file
if '/media/' not in file_path:
with open(file_path, 'r') as file:
file_str = try_utf8(file_path)
if file_str:
# Replace the target string
if original_str in file_str:
file_str = file_str.replace(original_str, new_str)
# Write the file out again
with open(file_path, 'w') as file:
file.write(file_str)
print('change file: %s' % (file_path))
if __name__ == '__main__':
# 检查参数
parser = argparse.ArgumentParser()
# Positional argument: quality (must be int between 1 and 99)
parser.add_argument(
'quality',
type=int,
help='Quality value between 1 and 99'
)
# Optional flag: --pngquant
parser.add_argument('--pngquant', action='store_true', help='Enable pngquant compression')
args = parser.parse_args()
# Validate quality range
if not (0 < args.quality < 100):
print('error: input parameter invalid (must be between 1 and 99)')
exit(1)
print('quality: %d' % args.quality)
quality = args.quality
# Handle pngquant flag
if args.pngquant:
print('--------------------------All png files will be compressed by pngquant--------------------------')
pngquant = True
else:
print('--------------------------All png files will be converted to jpeg--------------------------')
pngquant = False
# 检查当前运行环境
files_path = list_files('.')
check_dir = False
for path in files_path:
if './[Content_Types].xml' == path:
check_dir = True
break
if not check_dir:
print('error: this python script must run inside docx directory which includes [Content_Types].xml')
exit(1)
# 检查必要工具
if not os.path.isfile('/PATH/cjpeg-static'):
print('error: mozjpeg not found: /PATH/cjpeg-static')
exit(1)
if not os.path.isfile('/PATH/exiftool'):
print('error: exiftool not found: /PATH/exiftool')
exit(1)
# 现在也检查pngquant
if not os.path.isfile('/PATH/pngquant'):
print('error: pngquant not found: /PATH/pngquant')
exit(1)
# 开始优化
print()
for file_path in files_path:
if '/media/' in file_path:
if file_path.lower().endswith('.jpg') or file_path.lower().endswith('jpeg'):
if not check_exif_tag(file_path):
mozcjpeg_in_place(file_path, quality)
set_exif_tag(file_path)
else:
print('Already optimized: skip %s' % file_path)
print()
if file_path.lower().endswith('.png'):
head, filename = os.path.split(file_path)
if not check_exif_tag(file_path):
if not pngquant:
mozcjpeg_png(file_path, quality)
replace_xml_file(files_path, filename, filename.replace('.png', '.jpg'))
set_exif_tag(file_path.replace('.png', '.jpg'))
else:
run_pngquant(file_path)
set_exif_tag(file_path)
else:
print('Already optimized: skip %s' % file_path)
print()
用法示例:
先解压一个docx/pptx,然后进入解压后的目录(目录下一定有一个 [Content_Types].xml 文件),运行:
# 需要进入[Content_Types].xml的同级目录,然后把docx_opt.py拷贝过来运行
# 优化docx:选择mozjpeg压缩jpeg,选择pngquant压缩png
# 其他用法同理
$ cp /PATH/TO/docx_opt.py ./docx_opt.py
$ python3 docx_opt.py 80 --pngquant (可选jpeg压缩以及调整压缩率)
$ zip -r opt.docx * -x "*.DS_Store" "__MACOSX*" "docx_opt.py"然后用word/powerpoint程序打开 opt.docx 并检查文件是否正常。如果报了小错就修复文件(如之前的内容所示)。把优化后的docx/pptx拷贝出来存着,然后把剩下的那堆垃圾删掉即可。
直接修改xml(其他用途)
在习惯了对docx/pptx进行解压-重新压缩处理以后,很多word内部比较难处理的任务可以直接通过查询/修改xml来解决。
用法举例:把一个docx文档里的Cambria Math字体(word默认的数学公式字体)全部修改为Latin Modern Math字体(LaTeX默认的数学公式字体):
注意1:正规的方法应该用word内部的replace - advanced replace功能进行替换,但我尝试了几次都替换不干净,干脆直接修改xml去了;
注意2:因为是纯字符串替换,所以下面的命令可能会有误伤
先解压,然后进入表层目录(带有[Content_Types].xml文件的那层目录),执行
$ find . -type f -name "*.xml" -exec sed -i '' 's/Cambria Math/Latin Modern Math/g' {} +然后原地打包docx
