WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2024-05-20. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.Table of Contents
前置内容
使用https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv
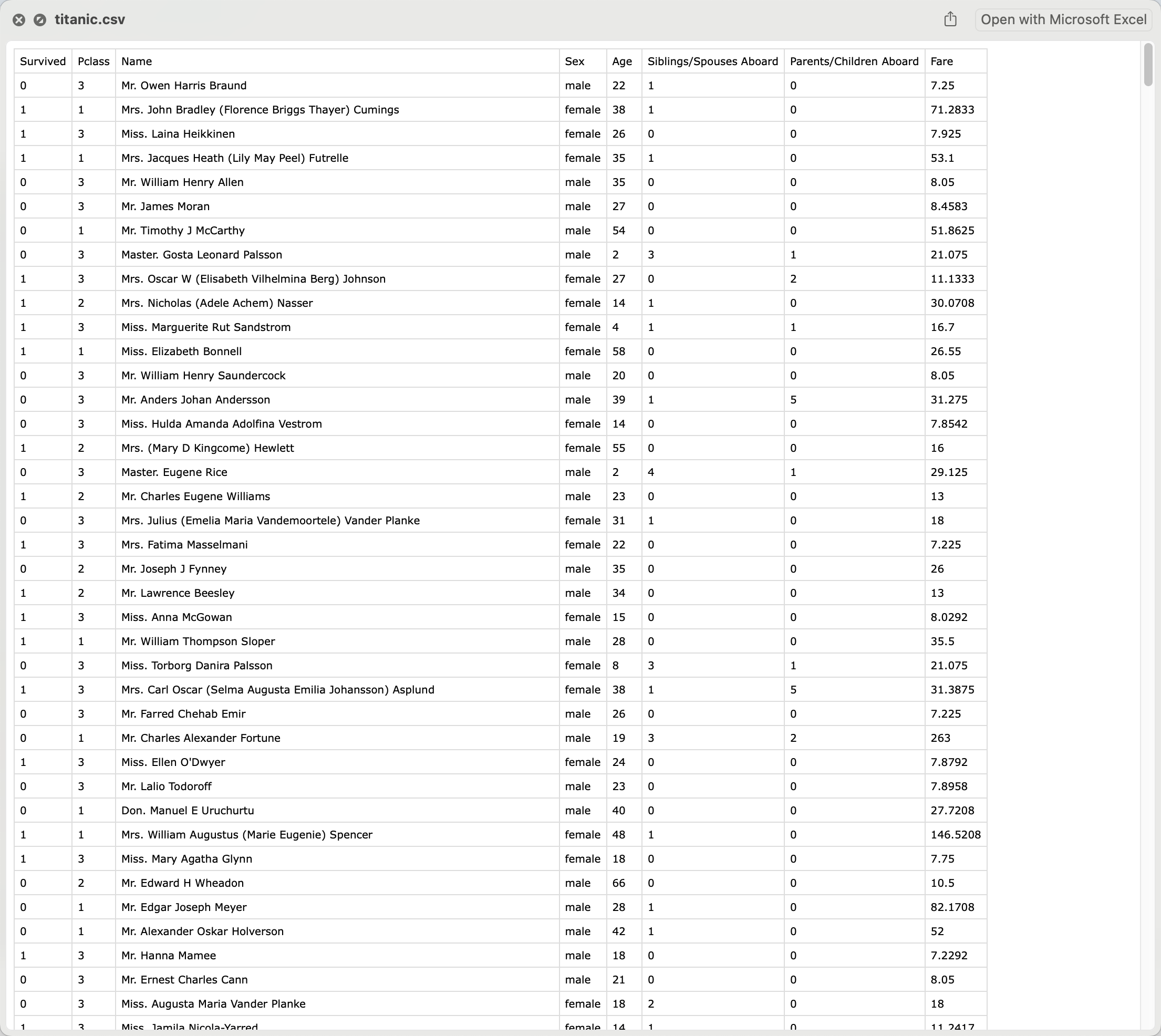
一共888行,其中第1行是csv head,所以数据已公示887条,注意:
wc -l titanic.csv
887这是因为命令wc -l并不是统计行数,而是统计有多少换行符。由于这个csv文件的最后一行没有换行符,所以会返回887
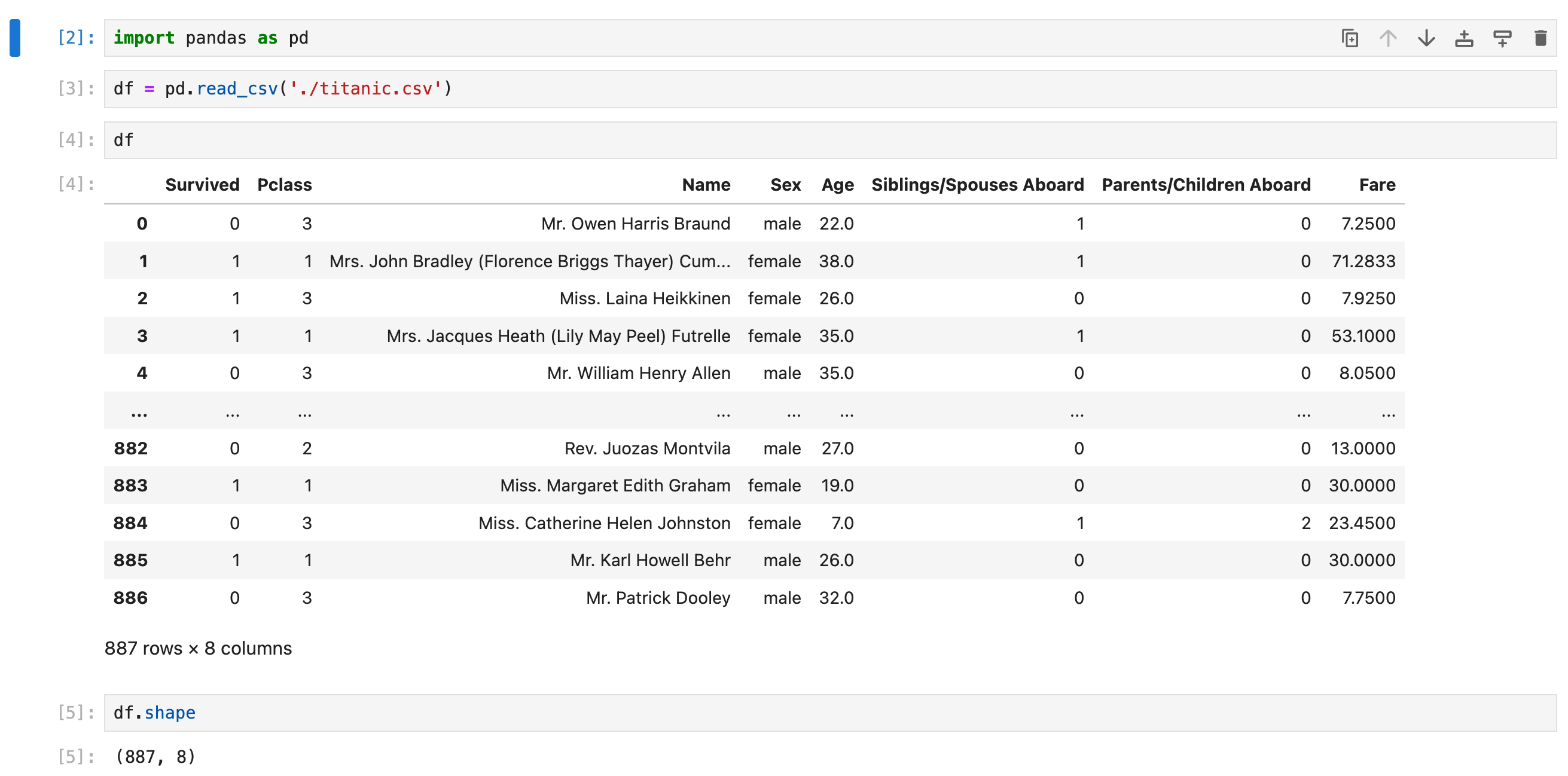
读文件
读取csv,获取基本信息
生成空DataFrame
df = pd.DataFrame(columns=['column1', 'column2', 'column3'])通过list生成DataFrame(很常用)
2025-08-09补充,非常常用的通过list制作df的方法
list代表1列
先来个简单的:每列的数据存储在不同命名的list里面(下面的代码分了featureA_lst和featureB_lst)
假设有featureA_lst和featureB_lst这两个list(长度相同):
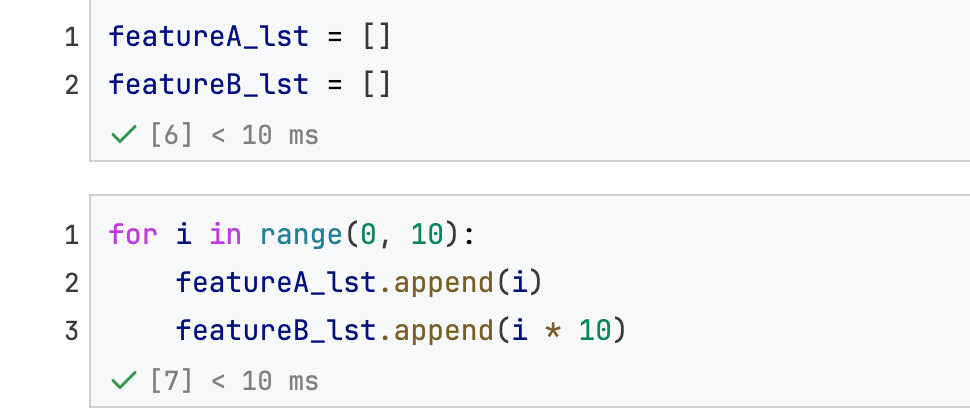
构建方法1:使用zip
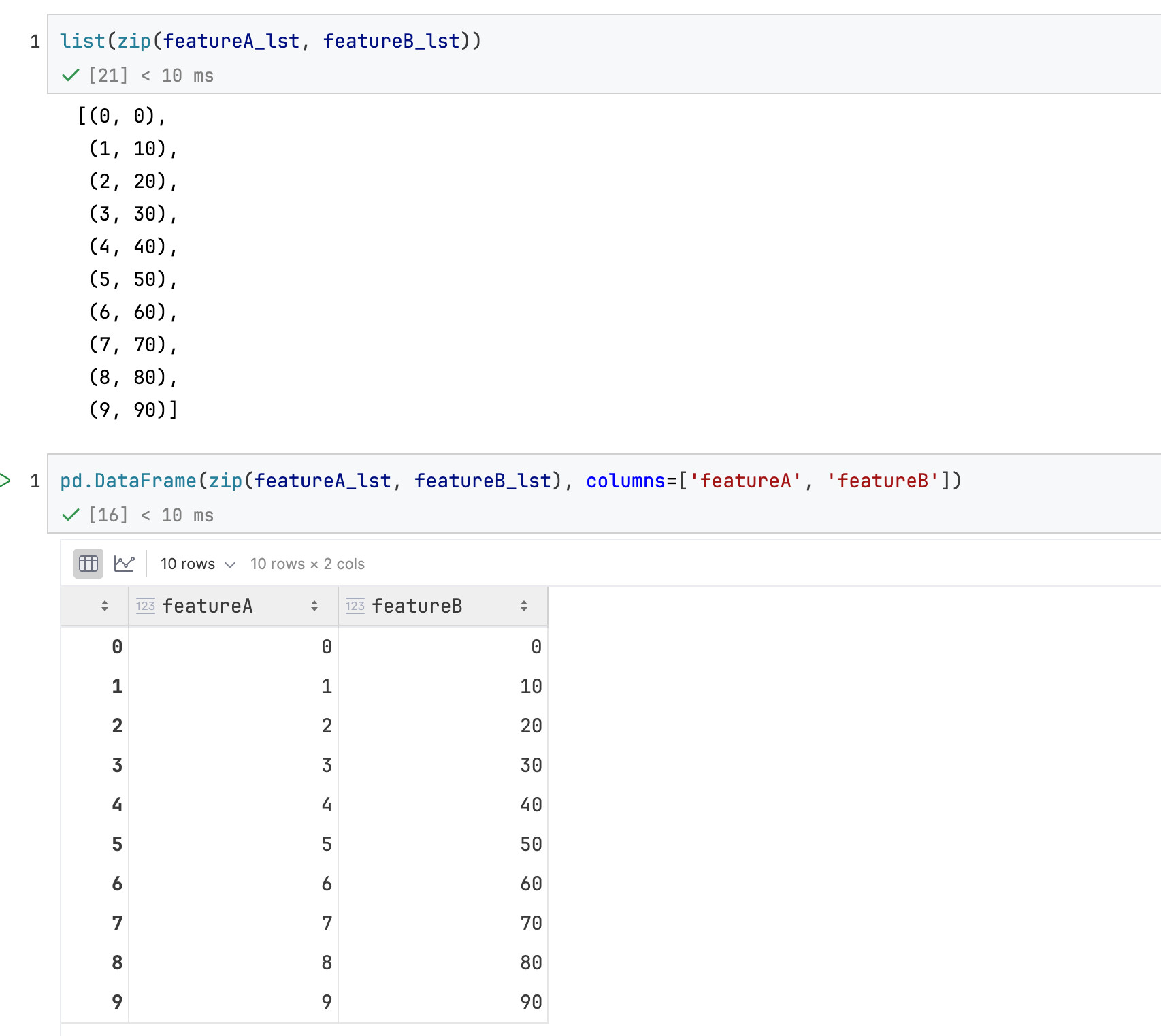
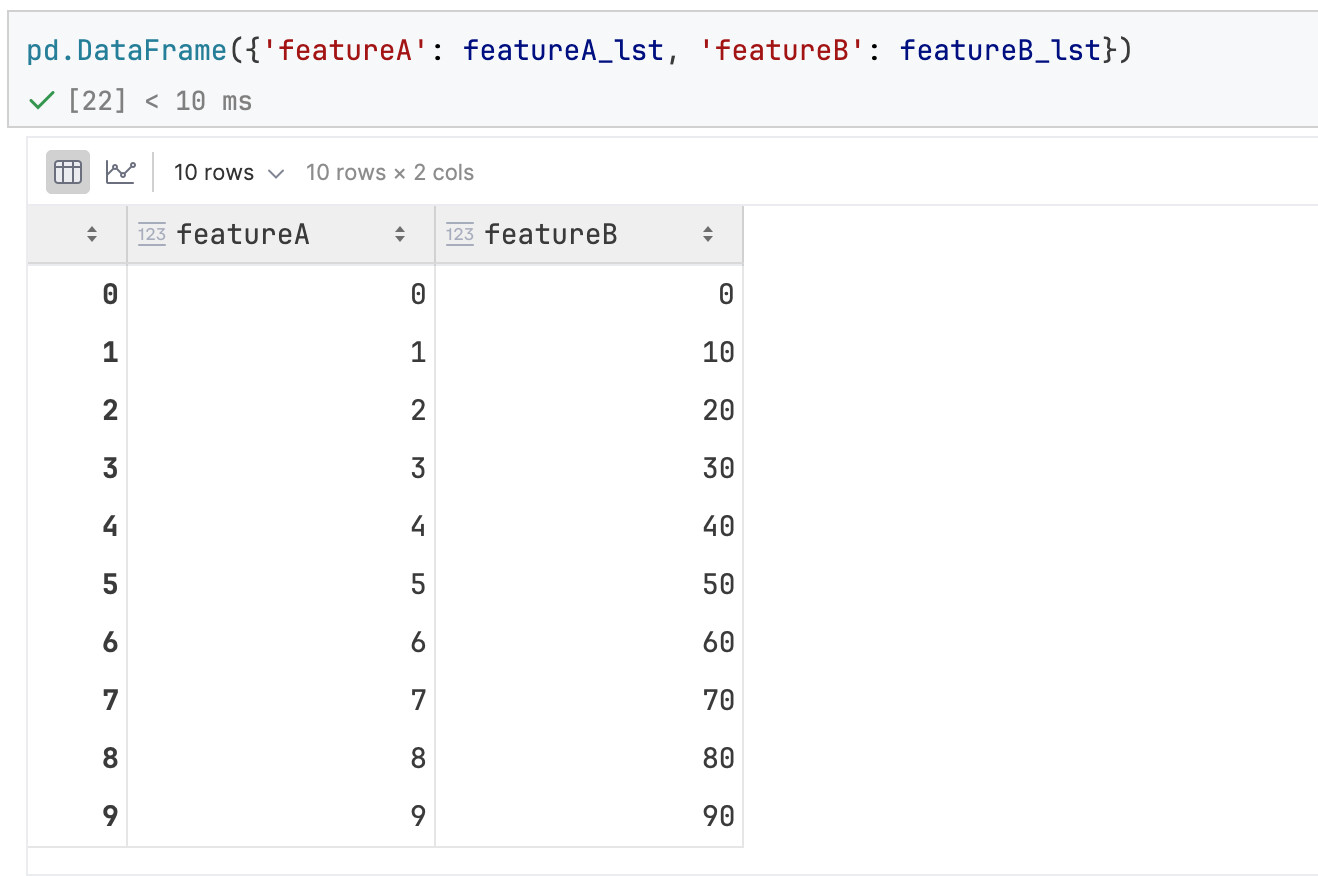
构建方法2:使用dict的写法
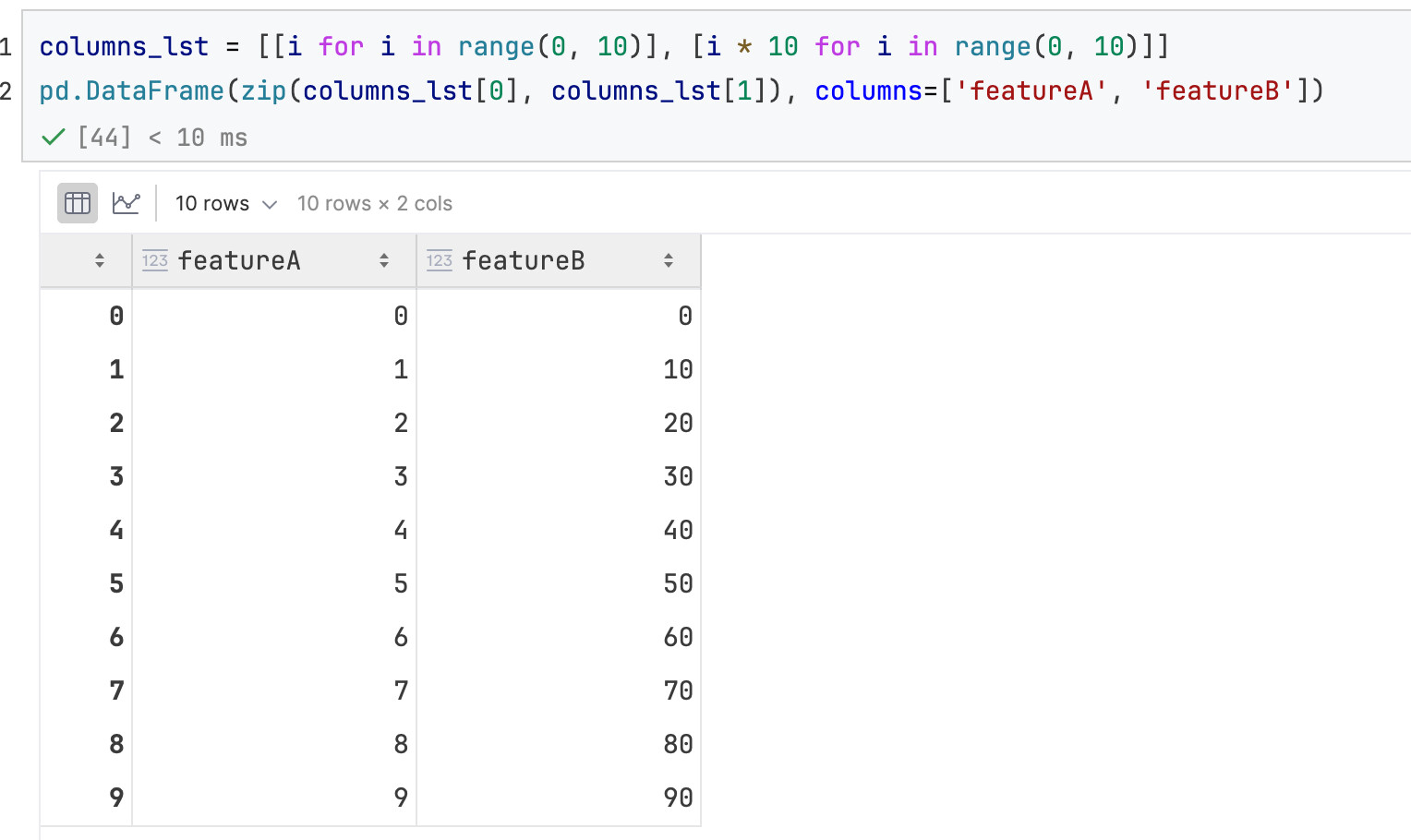
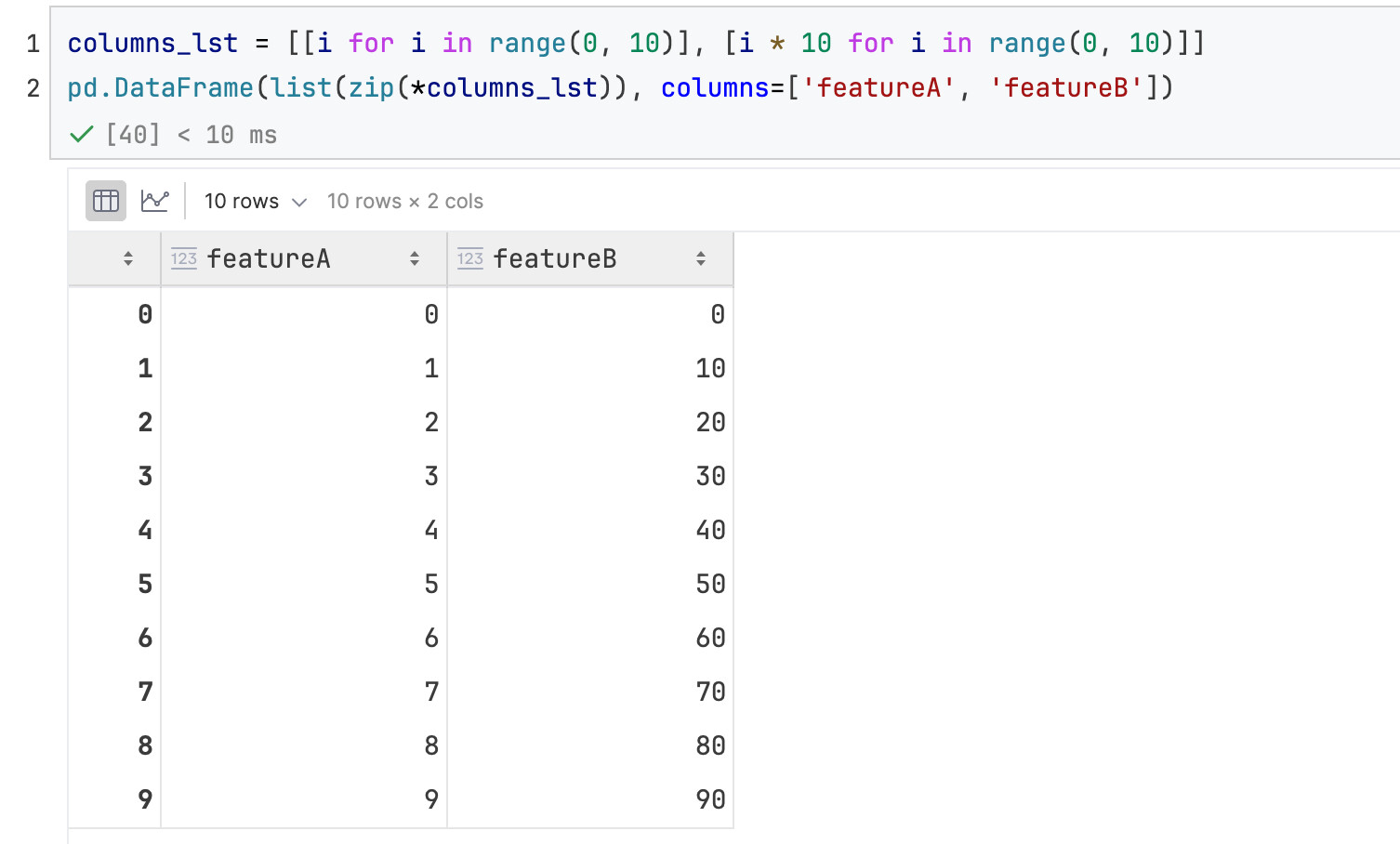
再来个组合的:list of lists,每个(里面的)list代表1列的数据
方法1:手动命名(本质上和上面的代码一样):
zip版本:
手动命名版本:
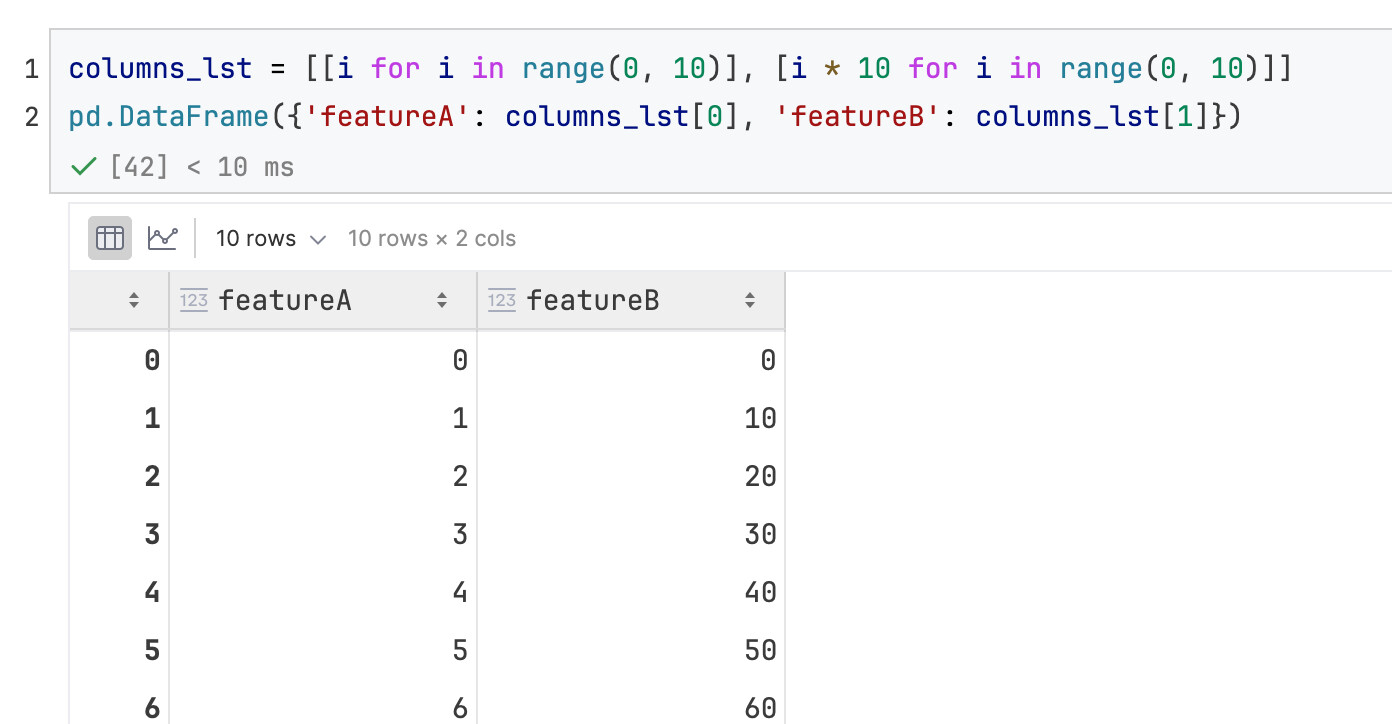
方法2:自动命名:
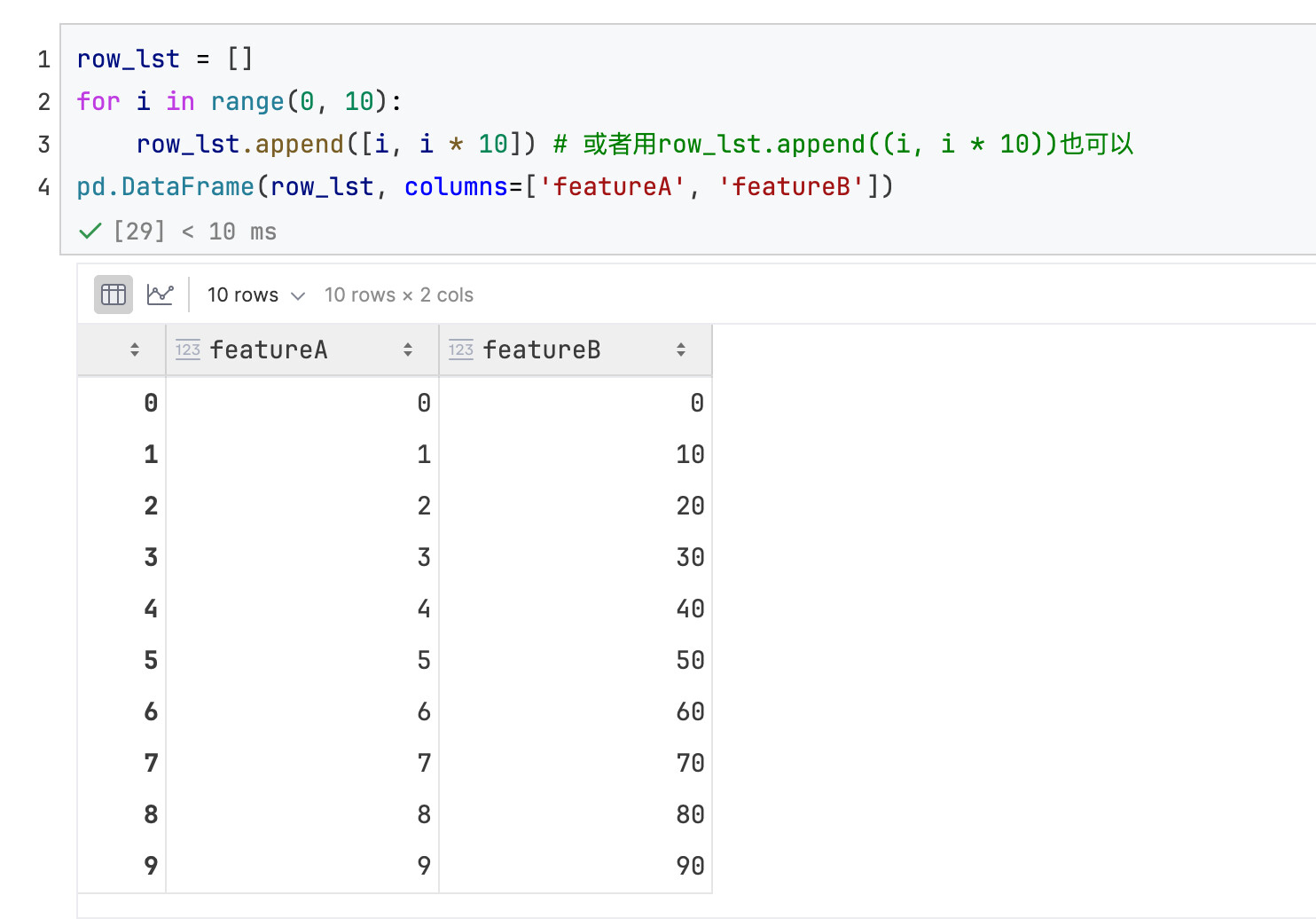
list代表1行
list of lists,每个(里面的)list代表1行的数据
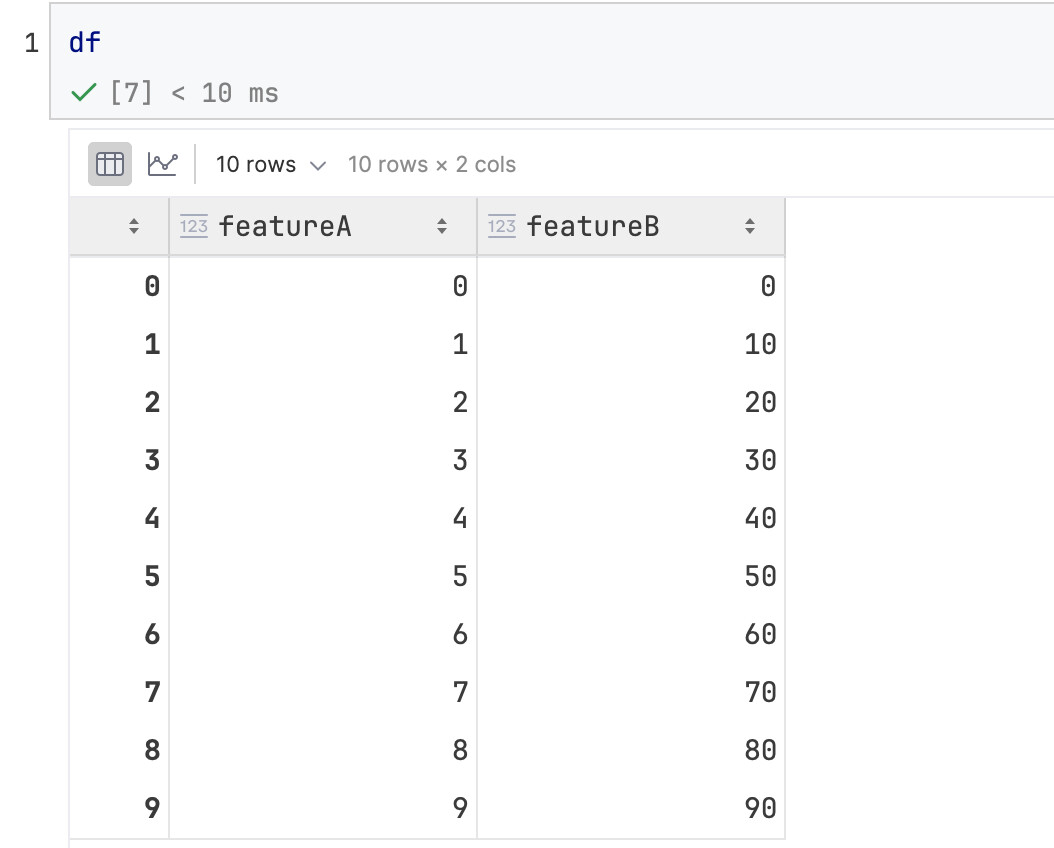
从现有df转换过来
本篇笔记的后面写有类似这样的内容:

但这种方法的代码效率是偏低的。上面介绍的方法(从list of lists直接变成df)又是从零开始构建数据的。如果给定一个已经存在的df,但又想高效率地往df尾巴上增加很多行,其实还有个办法就是1. 把df转换成list of lists(每个里面的list代表一行)2. 对list of lists进行数据增加的操作 3. 把list of lists变回df取代之前的
代码如下,假设从这个df开始,要在df的尾巴上继续粘贴10行:
转换核心代码: df.values.tolist() ,把df变成list of lists (或者用 df.to_numpy().tolist() 也可以)
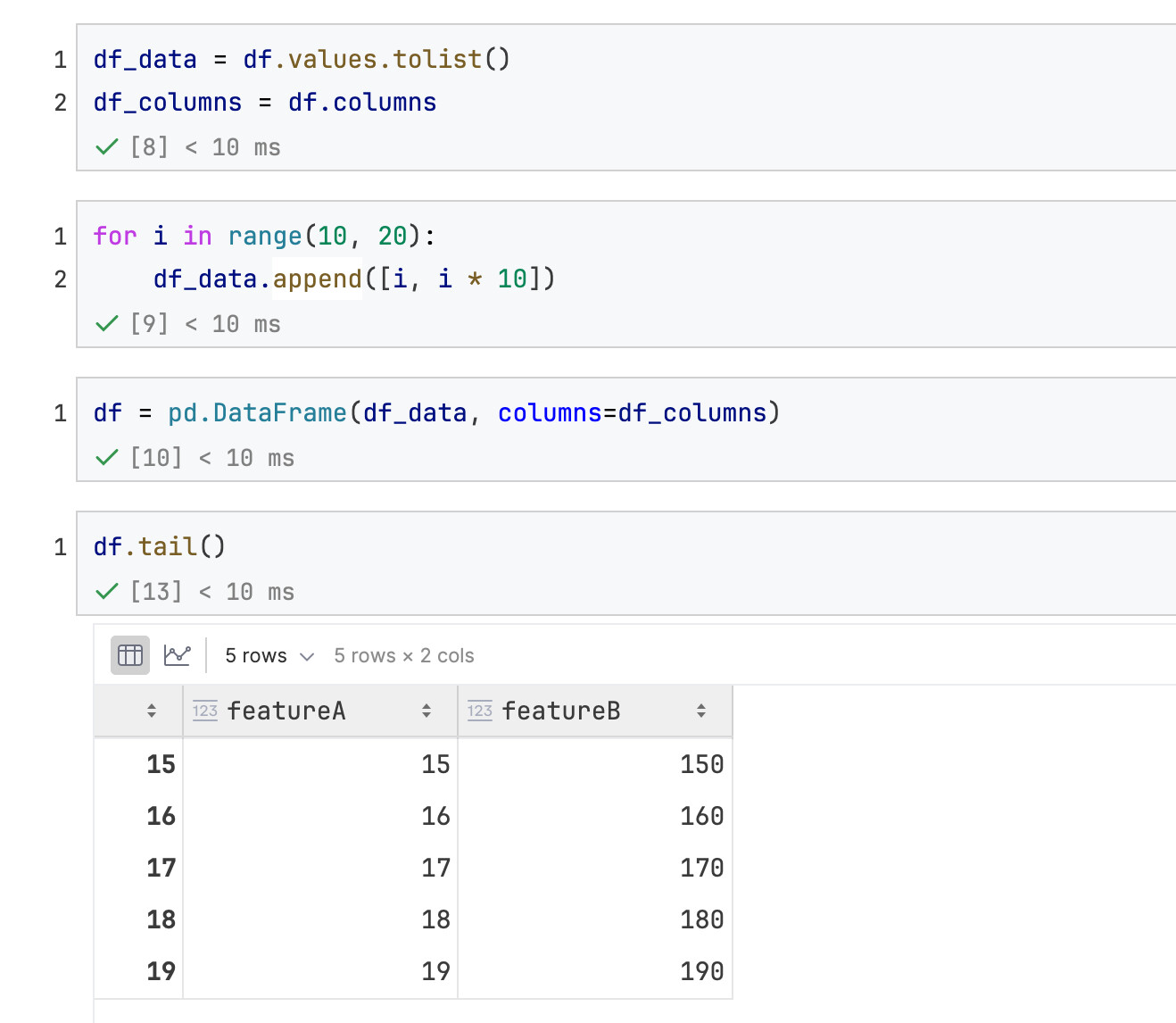
获取所有column name
获取所有column name(as a list)
以后会用得上
判断df内容相同
判断两个dataframe内容完全相同
使用 df1.equals(df2)来判断
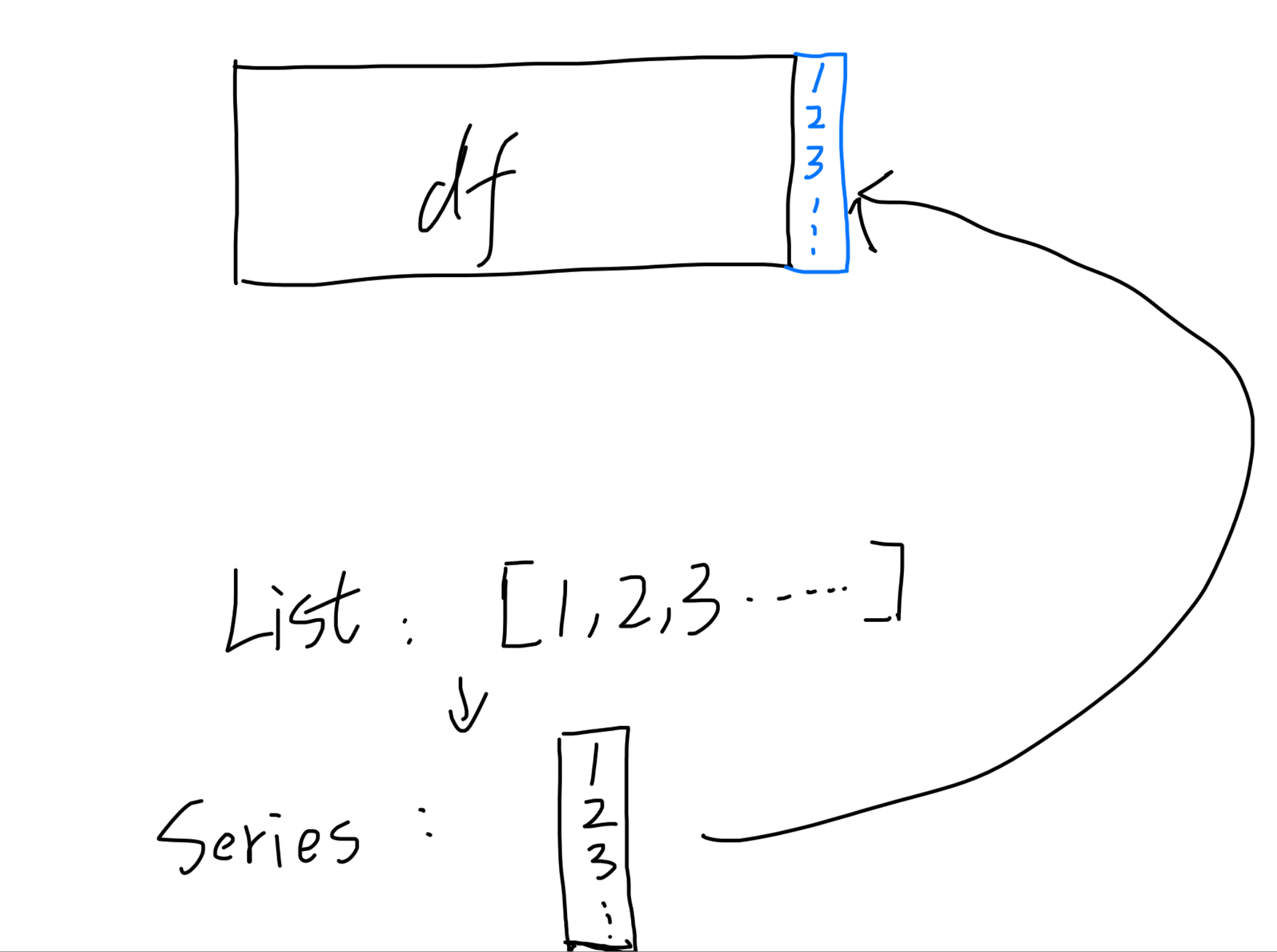
series和dataframe
区分
先区分pandas.series和pandas.dataframe


series转list以及numpy array
用list(series)或者series.to_list()就可以转换为list
转换为list以后当然就可以直接用np.array(list)转换为numpy array,当然也有直接转换的方法to_numpy()
series转dataframe
series可以转成dataframe,但记得转置:
series转dict
在之前的一系列操作(series转list, numpy array等)很容易让人误以为series就是一个像list的对象,用自然数作为索引下标。实际上并不是的:
实际上我们获取的series都可以转换为dict,只是在之前的场景下我们用不到series的"自然数key",但现在我们需要用到series的“字符串key“:

List转Series
其实就是反过来的操作,但要注意,创建pandas.Series数据的时候可以指定一些东西,可以解决很多【合并】方面的问题:
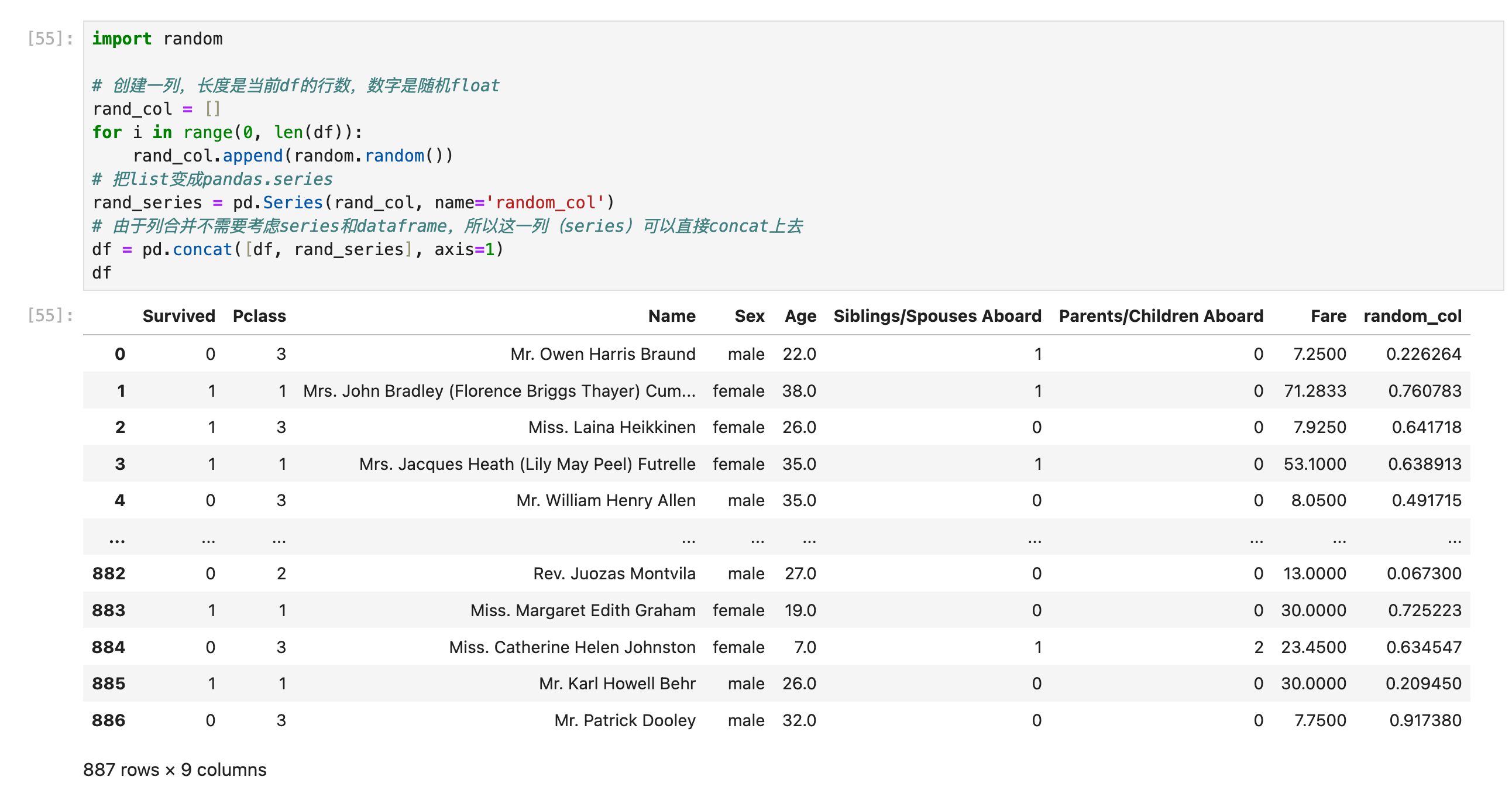
1:比如作为column name,常见于“把Series合并为新的一列“:
(下面这张图来自后面的目录【Dataframe合并List,List作为新的一列】)
2:又比如作为"index",常见于“把Series合并为新的一行“
(下面这张图来自后面的目录【合并多行(series index带来的问题)】)

索引(index和Integer-location based index)
总结
总结一下就是:
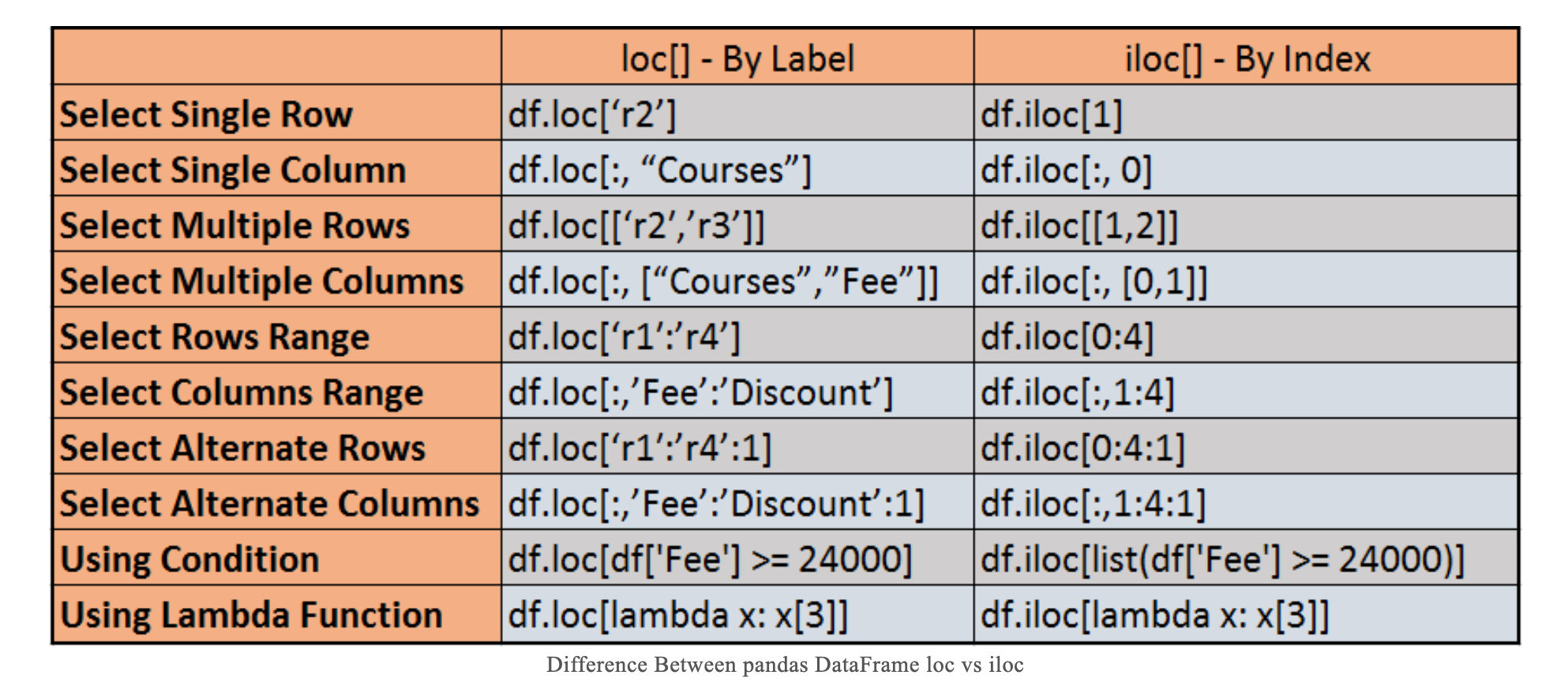
index/row index:使用df.loc, df.at时传入的index,可以是0, 1, 2, 3, 4, .... 这种自然数也可以是小数、字符串等各种数据类型,甚至可以重复。如果创建dataframe的时候没有特意声明这个index,那么pandas会默认赋予0, 1, 2, 3...自然数的index,这种情况下df.at和df.iat返回的结果相同.
Integer-location based index/positional index:使用df.iloc, df.iat时传入的index. 就是0, 1, 2, 3, 4, .... 自然数。
下面这段代码在titanic.csv上跑起来没有问题,但实际上代码设计是错误的:

因为df.at接受的index是row index! 如果像titanic.csv这样的df,上面的代码还能侥幸得到正确的结果(因为titanic.csv使用默认index),但并不意味着上面的代码没有问题。只要换一个df(比如下面介绍的【非自然数row index dataframe】),代码就有可能出问题!

正确方法是使用iloc(这里还不适合用df.iat,因为df.iat要求column也是positional index类型的):
row index可以不是自然数(来自reset_index)
这个问题是写完这篇笔记后引入的。具体来说就是:
由于本篇笔记基本都在分析titanic.csv,涉及到的row index都是0, 1, 2, 3...的自然数(用pandas的称呼叫做sequential index)。但有些时候一旦涉及到删除行+reset_index,一些奇怪的问题就会出现。
example 1:🔗 [pandas.DataFrame.reset_index — pandas 2.2.2 documentation] https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.reset_index.html

row index可以重复(来自drop)
example 2:
来自本篇笔记后面的例子:
下面的语句本质上是在drop row index为0, 1, 2, 3, 886的这几行(而不是在drop物理意义/iloc意义上的这几行),所以第二次drop的时候会出问题:
row index不是物理意义的index(来自iloc, loc和at)
总结:loc和at使用的是row index,iloc使用的“物理意义”的index被称为integer-location based index/positional index.
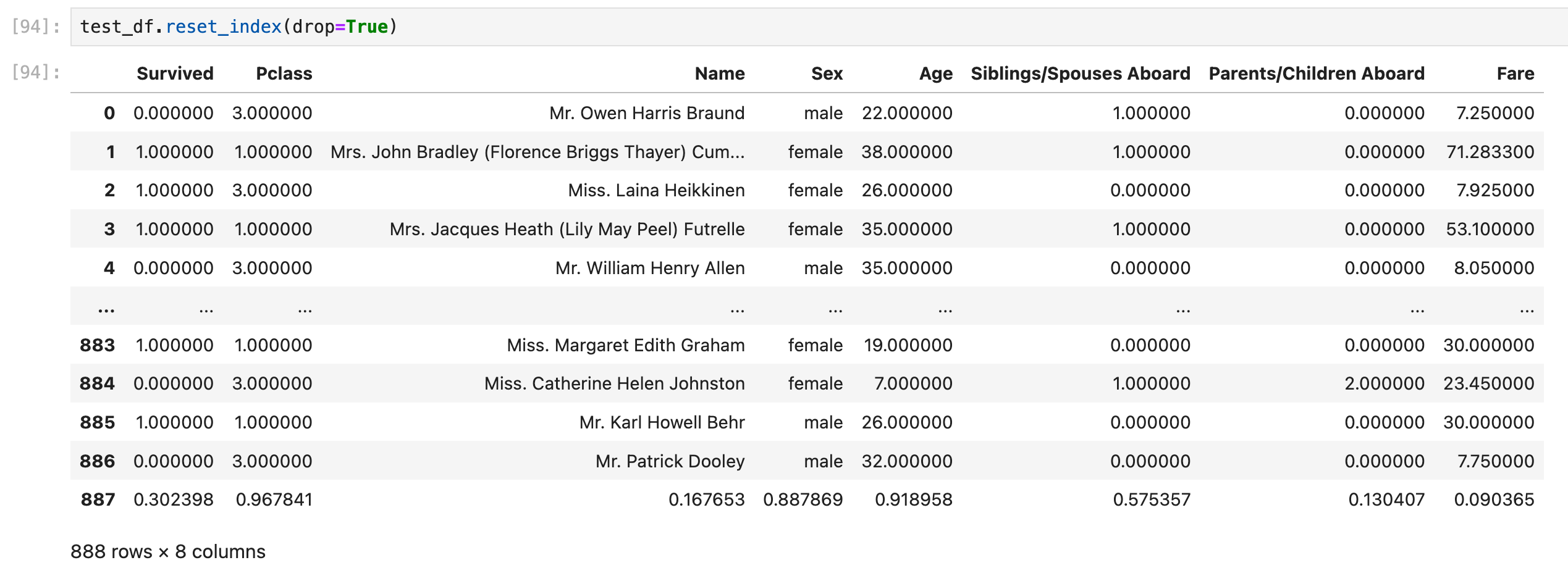
dataframe是允许重复row index的!所以很多时候会遇到奇怪的dataframe,比如下面这张图里的dataframe,row index为0的行有2行!
(这张图来自后面的目录【dataframe合并List,List作为新的一行】,所以这个dataframe长得有点奇怪,因为最后加上来的这一行全部都是float类型的数据)
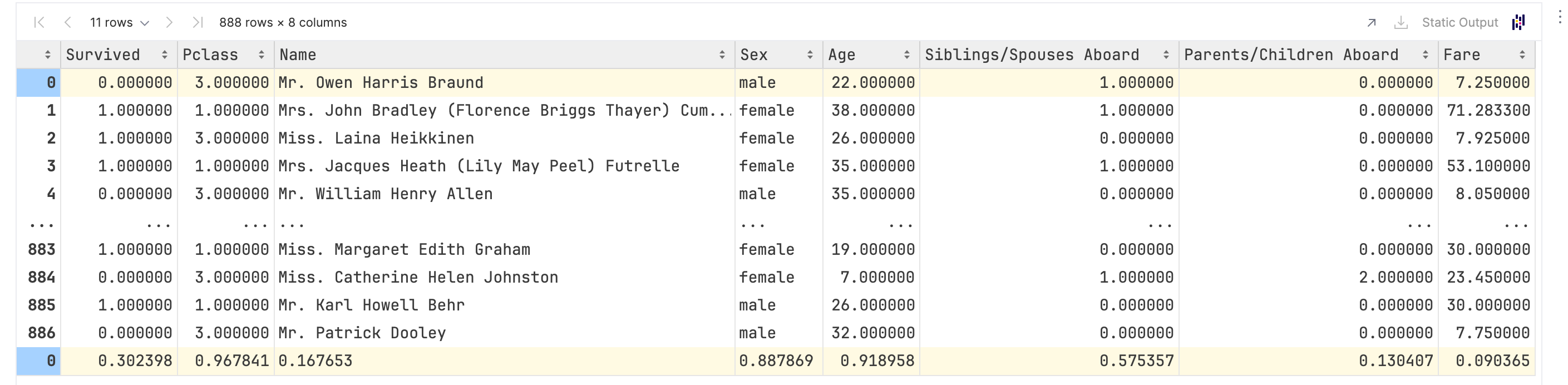
如果用iloc试图获取“物理意义上的倒数第一行“,就会获得最后一行:

如果用loc试图获取“row index为0的行“,就会获得2行:

如果想获取【第xx行+y列】的数据,使用下面的方法会获取到2个数值(第一行和最后一行),说明下面的2种方法都是基于row index(而不是物理index)的:
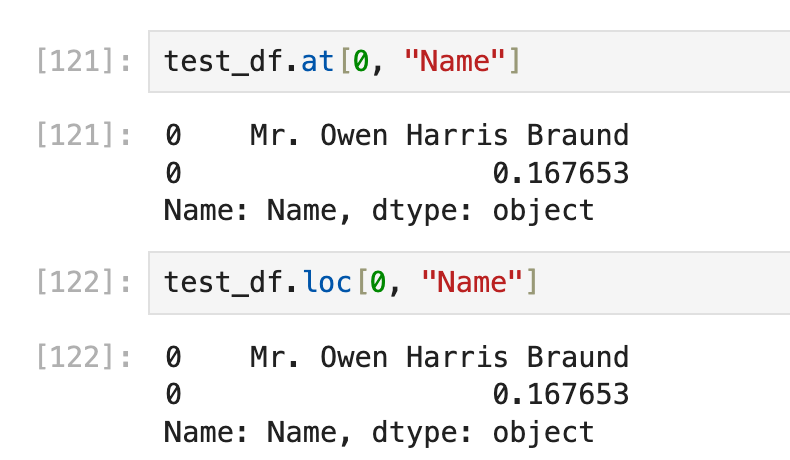
如果要想真-获取【最后一行的column 'Name'的那一个数值】,就需要先使用iloc,然后用列名获取:
上面这种dataframe会干扰我们的程序(一般情况下,只有“有意义”的Index才有重复的意义),解决方法是reset_index():
Unnamed: 0的出现原因(来自to_csv)
titanic.csv长这样:
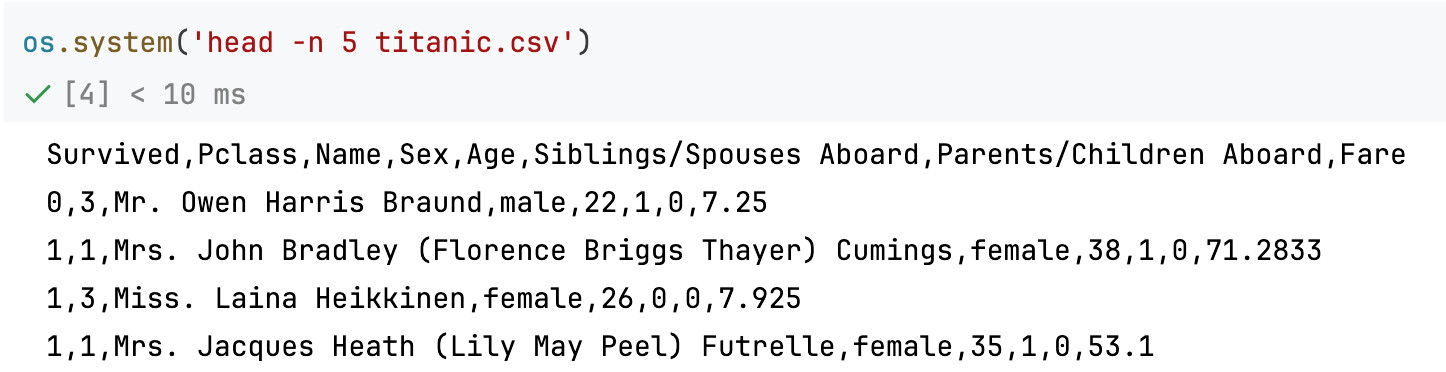
如果读取titanic.csv然后使用df.to_csv('titanic_copy.csv')导出csv,导出的csv实际上有所不同:
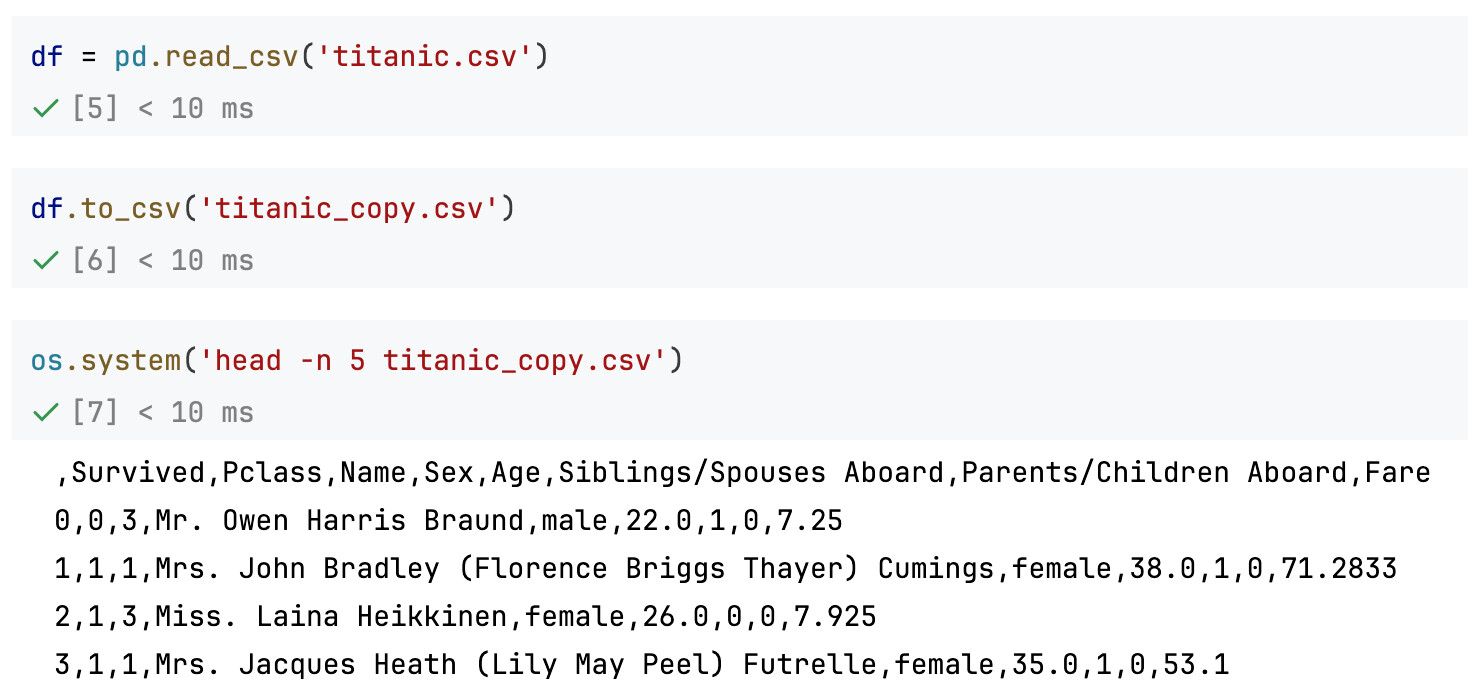
可以注意到csv新增了一列,这一列没有column name(实际上是row index)。如果再把这个csv读回来,会发现多了一列被命名为Unnamed: 0的列:
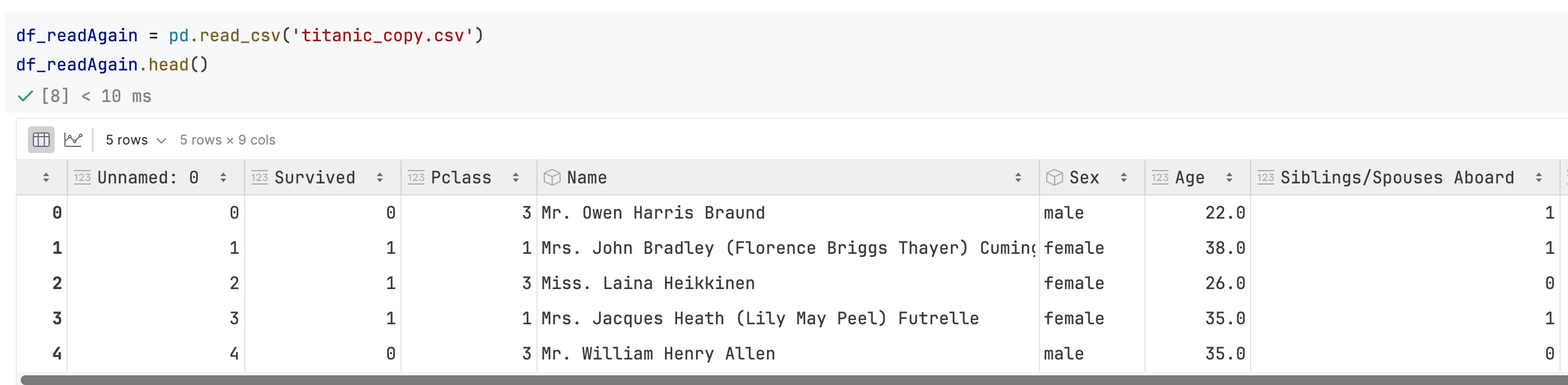
所以大多数时候我都会导出csv的时候加参数index = False.
iloc操作
基本介绍
iloc操作的是【物理意义上的索引】(见上面有关row index的说明)
先写iloc操作,是因为iloc只涉及索引下标,最容易学
学了iloc以后再学loc
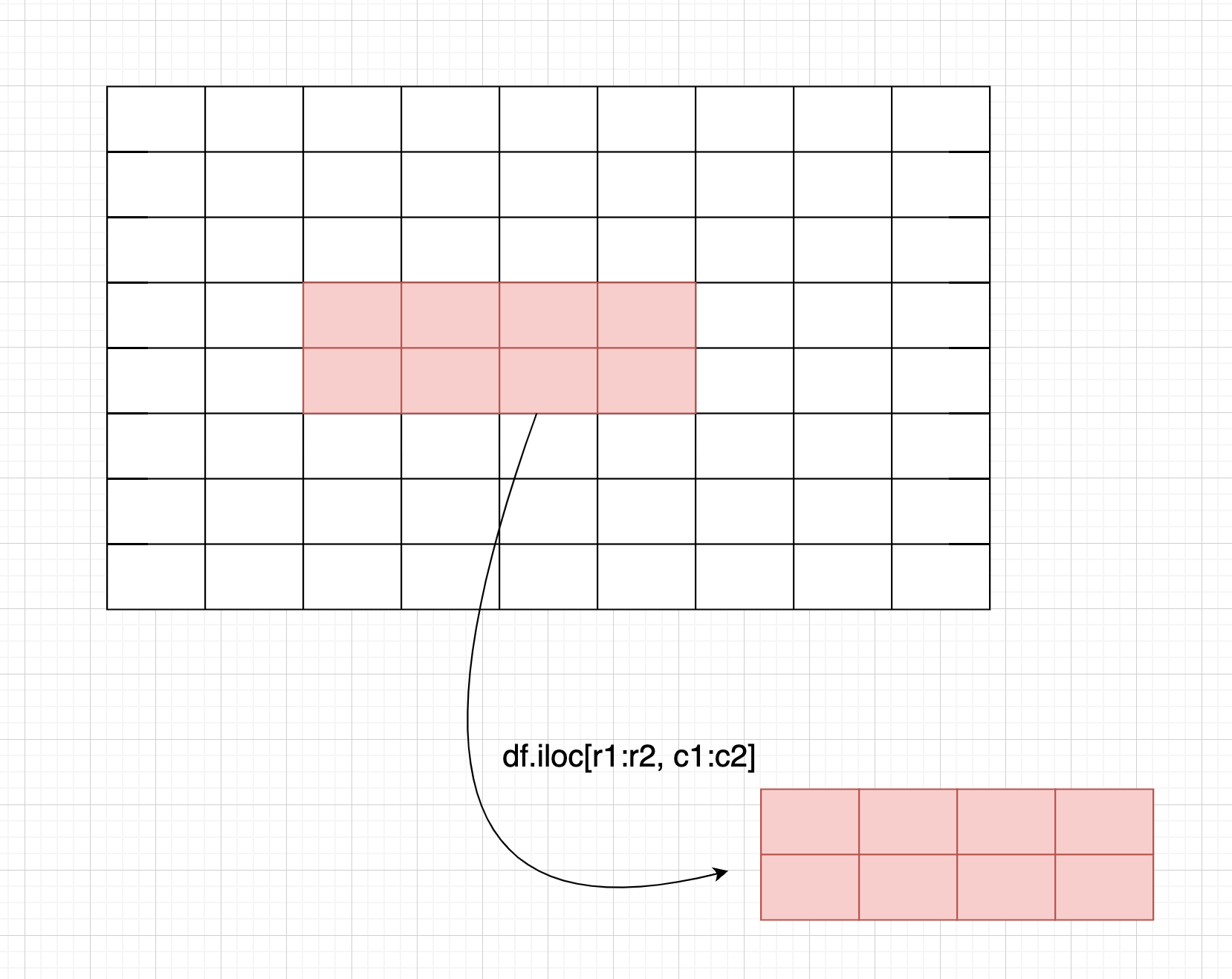
下面会涉及到这些写法:
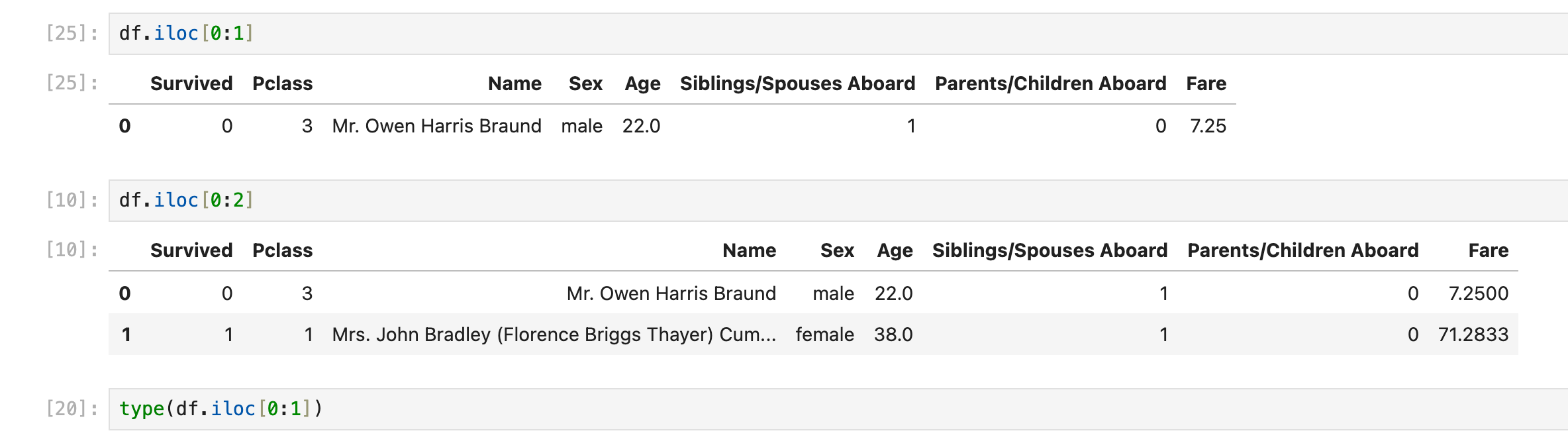
df.iloc[0],等价于df.iloc[0, :]
df.iloc[0:0],等价于df.iloc[0:0, :]
df.iloc[0:1],等价于df.iloc[0:1, :]
df.iloc[0, :]
df.iloc[0:1, :]
df.iloc[:, 1]
df.iloc[:, 1:2]
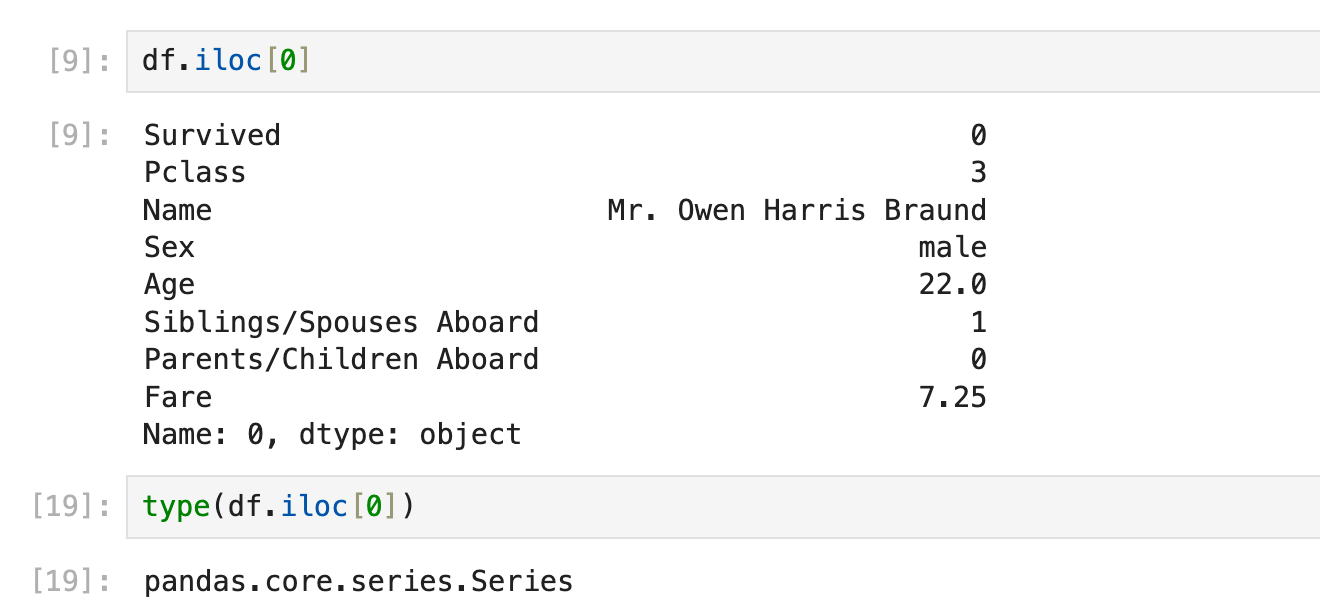
df.iloc[1, 2],直接获取物理意义上的数值获取一行(pandas series)
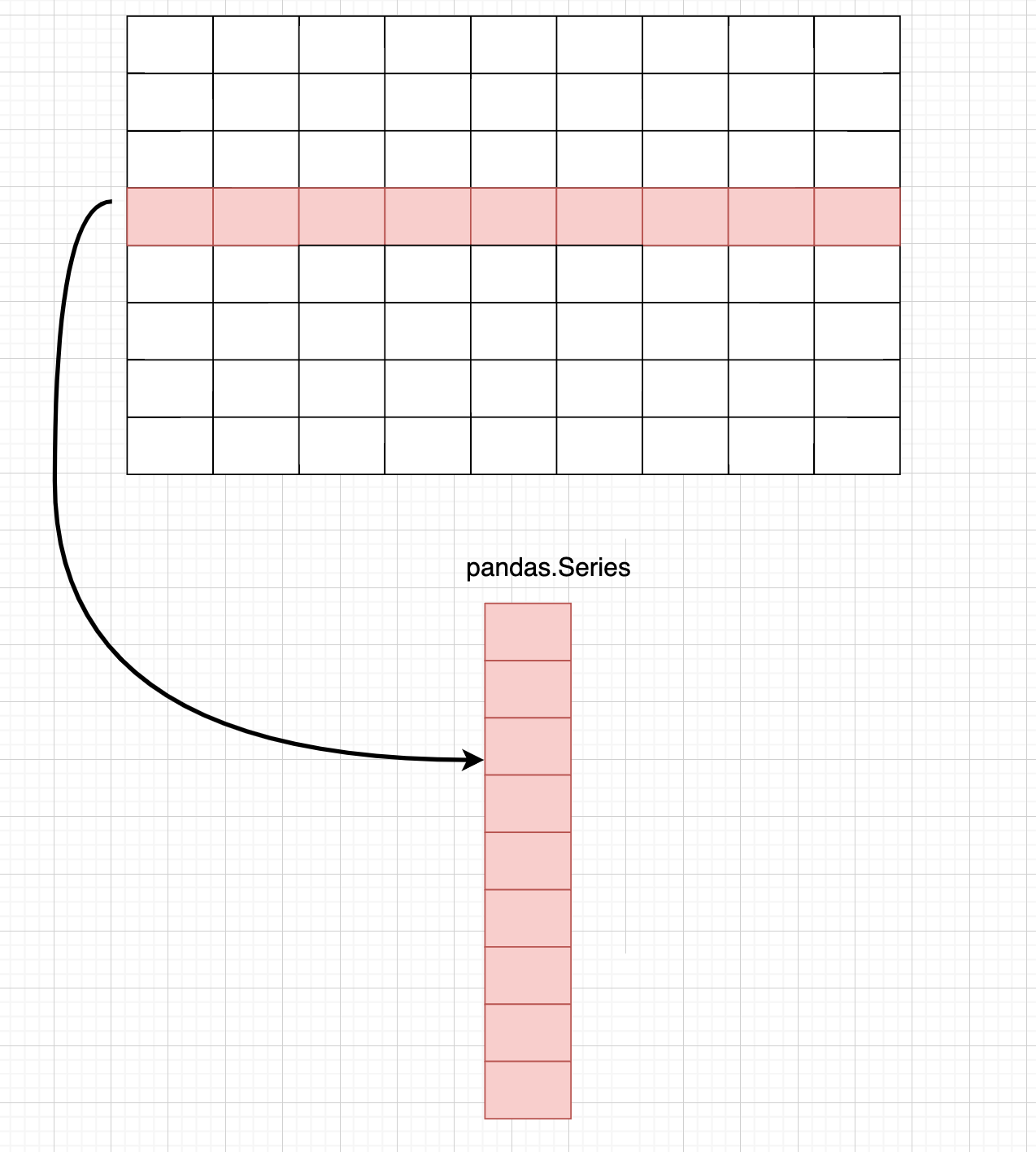
df.iloc[x] 获取第x行,这里返回的是pandas.series
完整地写应该写成df.iloc[x, :]
一旦获取了series类型的数据,它的形态就会发生改变,不再是”一行“的样子了,而是“一列”(这里涉及到后面的内容:合并多行)
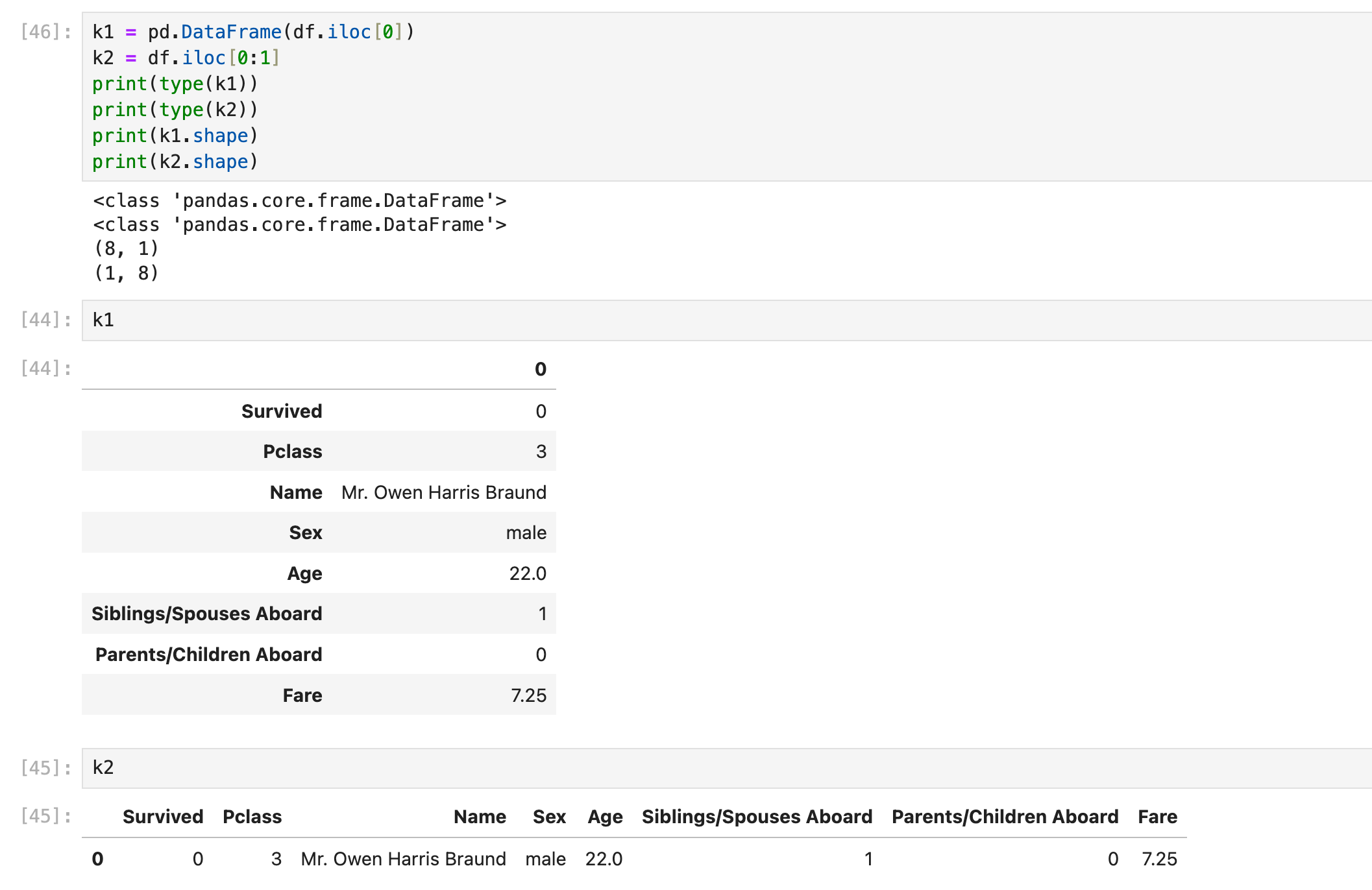
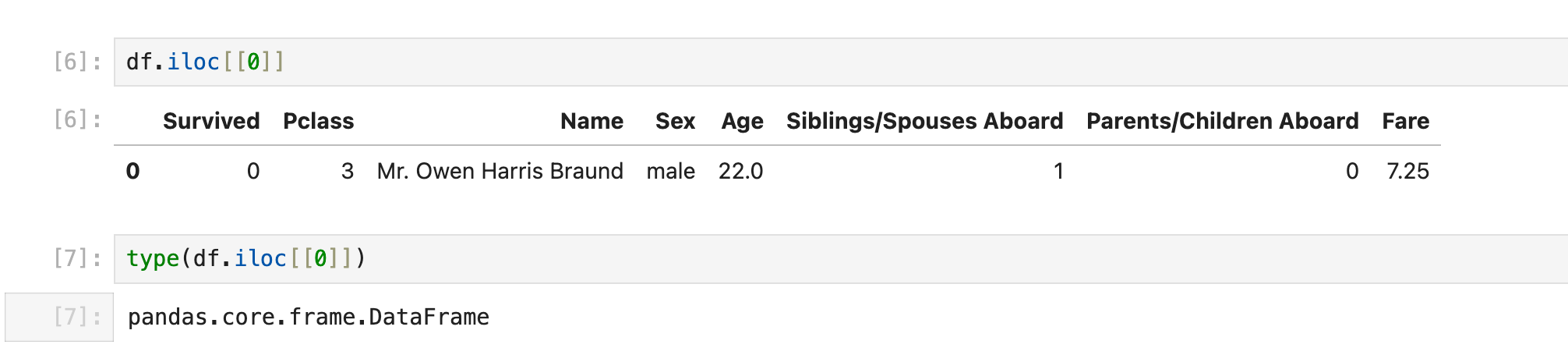
获取一行(dataframe)

df.iloc[[x]] 获取第x行,这里返回的是pandas.dataframe
完整地写应该写成df.iloc[[x], :]
获取多行(连续)
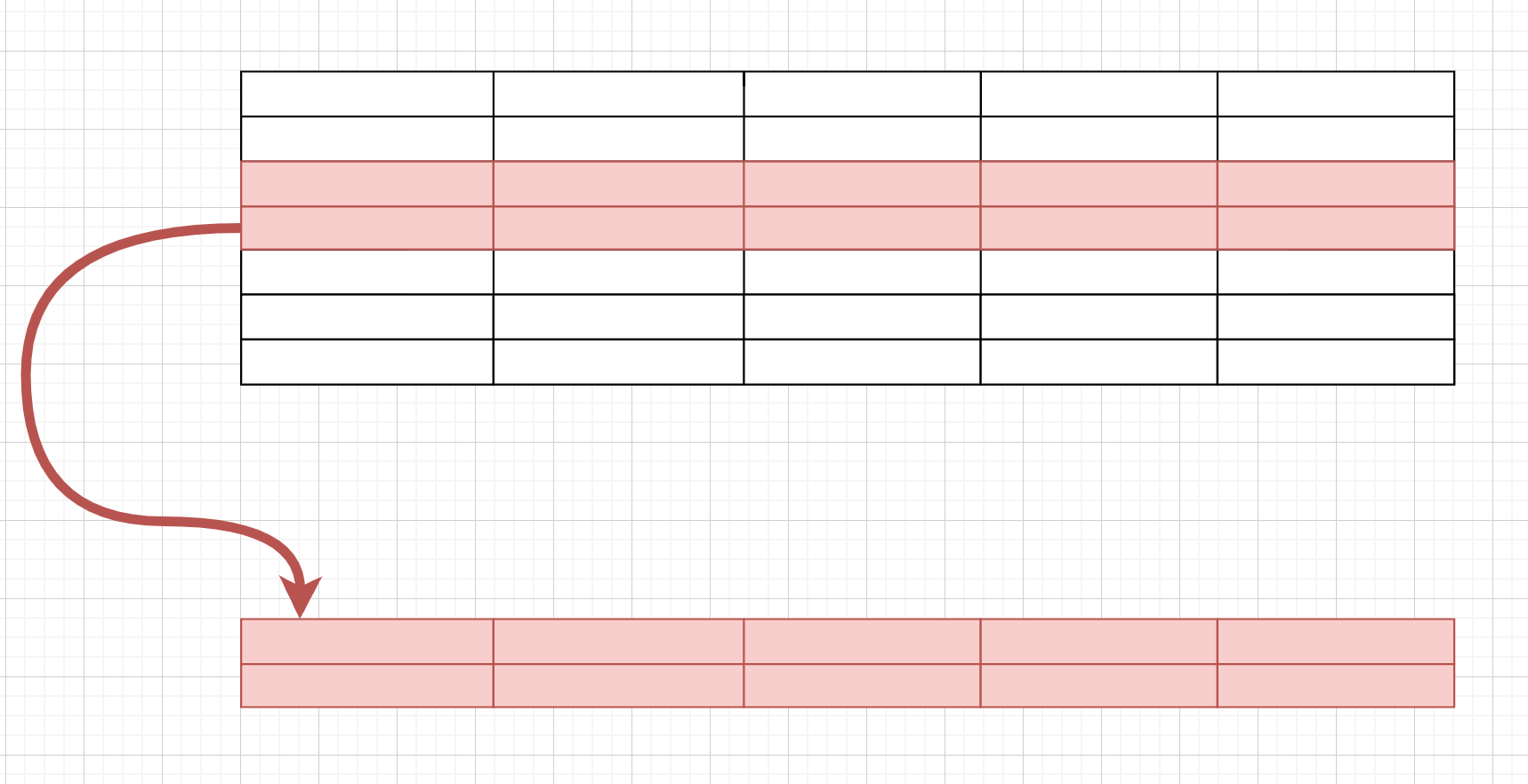
通过df.iloc[x:y]获取的是dataframe,注意df.iloc[0:0], df.iloc[1:1]这样的语句会返回一个空dataframe(和python list slice逻辑一样)
获取多行(离散)
通过df.iloc[[x, y, z], :]获取多行,返回一个x, y, z拼起来的dataframe
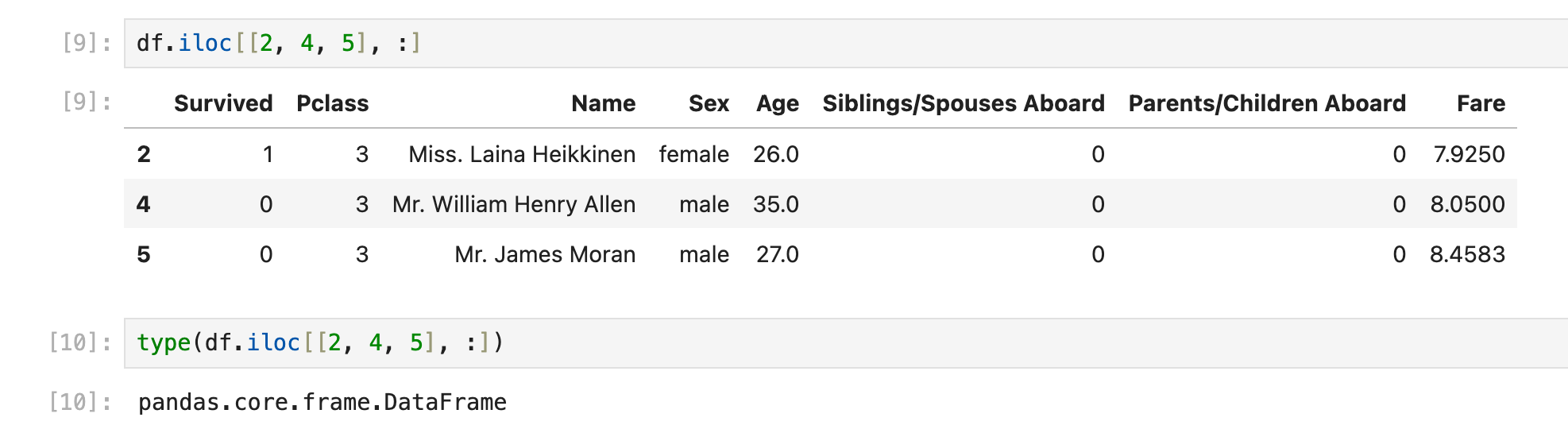
在实战中很有作用,在for循环中先收集要保留的rows对应的索引,然后一次性df.iloc[incides],这样比一行一行append/concat效率要高:

获取一列/多列
iloc的列操作其实不常见,因为平时写列操作用的基本上是列名(column name),很少用index来表示第几列
df.iloc[:, -1]可能有点用,可以在构建动态dataframe的过程中始终拿取最后一列
逻辑上和iloc获取一行/多行基本一致,只是换了个地方放置index
同样也要注意到返回series和dataframe的区别
df.iloc[:, 2] # 一列,返回series
df.iloc[:, [2]] # 一列,返回dataframe
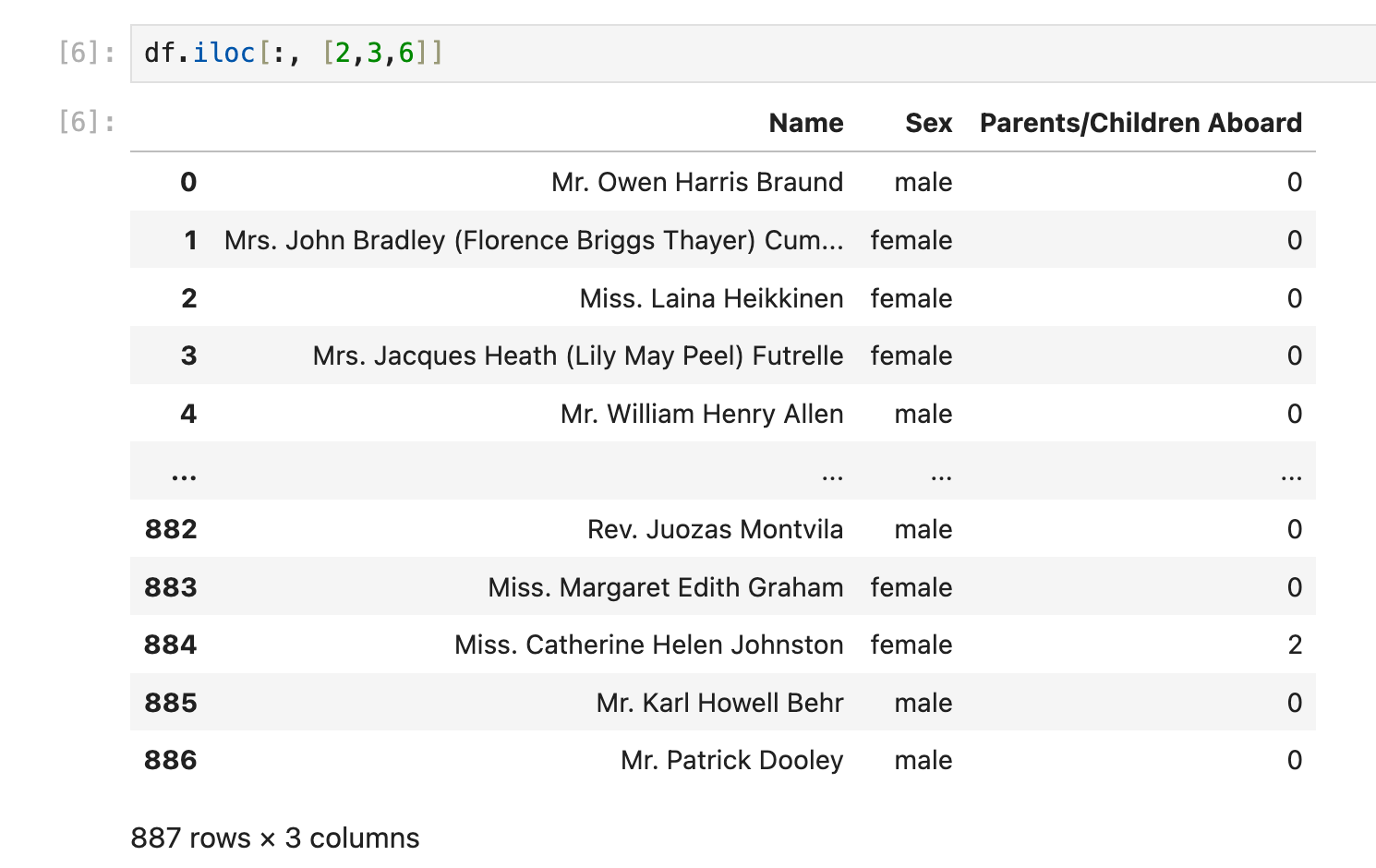
df.iloc[:, [2,3,6]] # 多个离散的列拼成的dataframe
df.iloc[:, 0:2] # 连续的列拼成的dataframe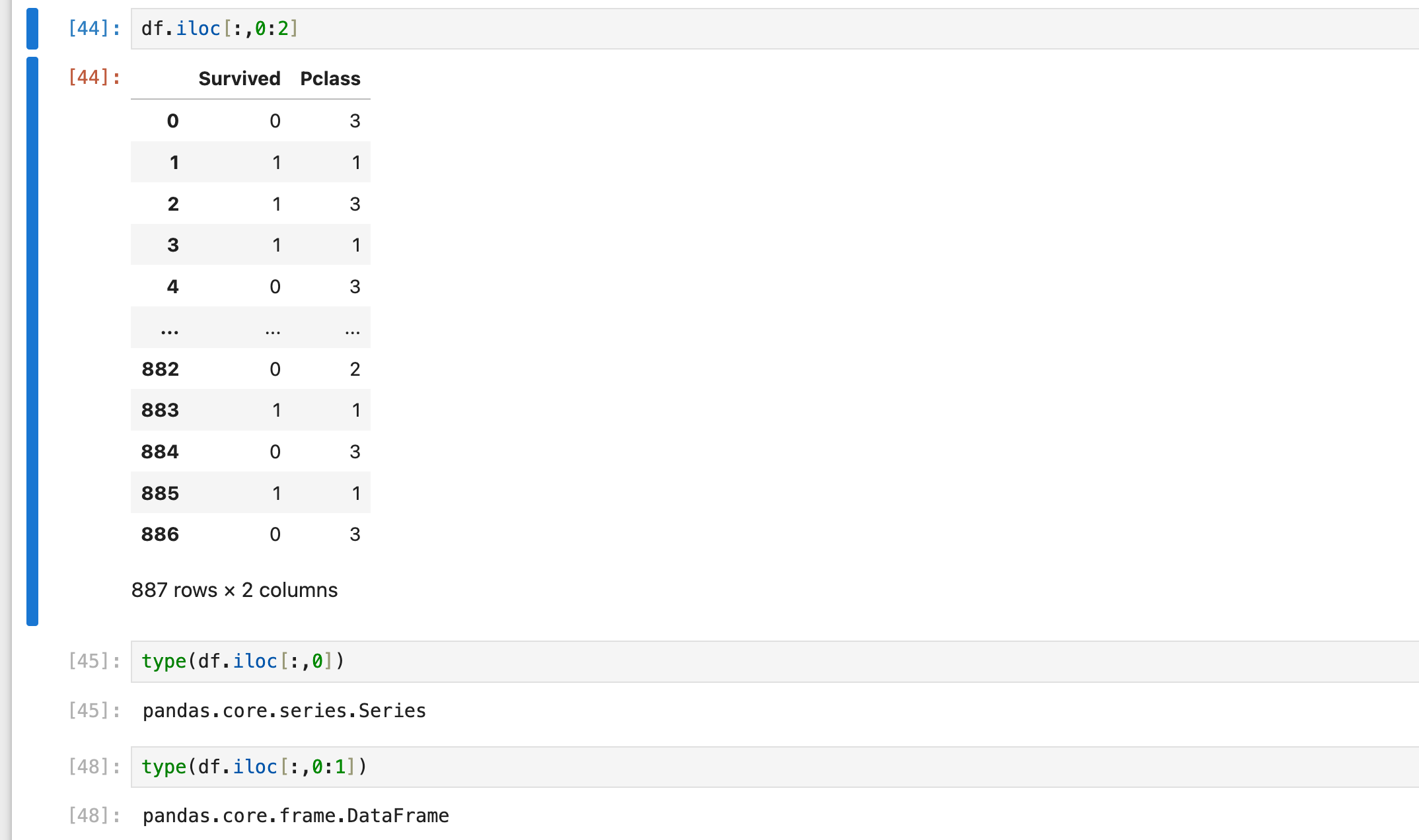
获取/修改一个数值
于2025-07-02补充,过去一年了我才学到这个写法。
df.iloc[i, j] # 直接定位第i行,第j列的元素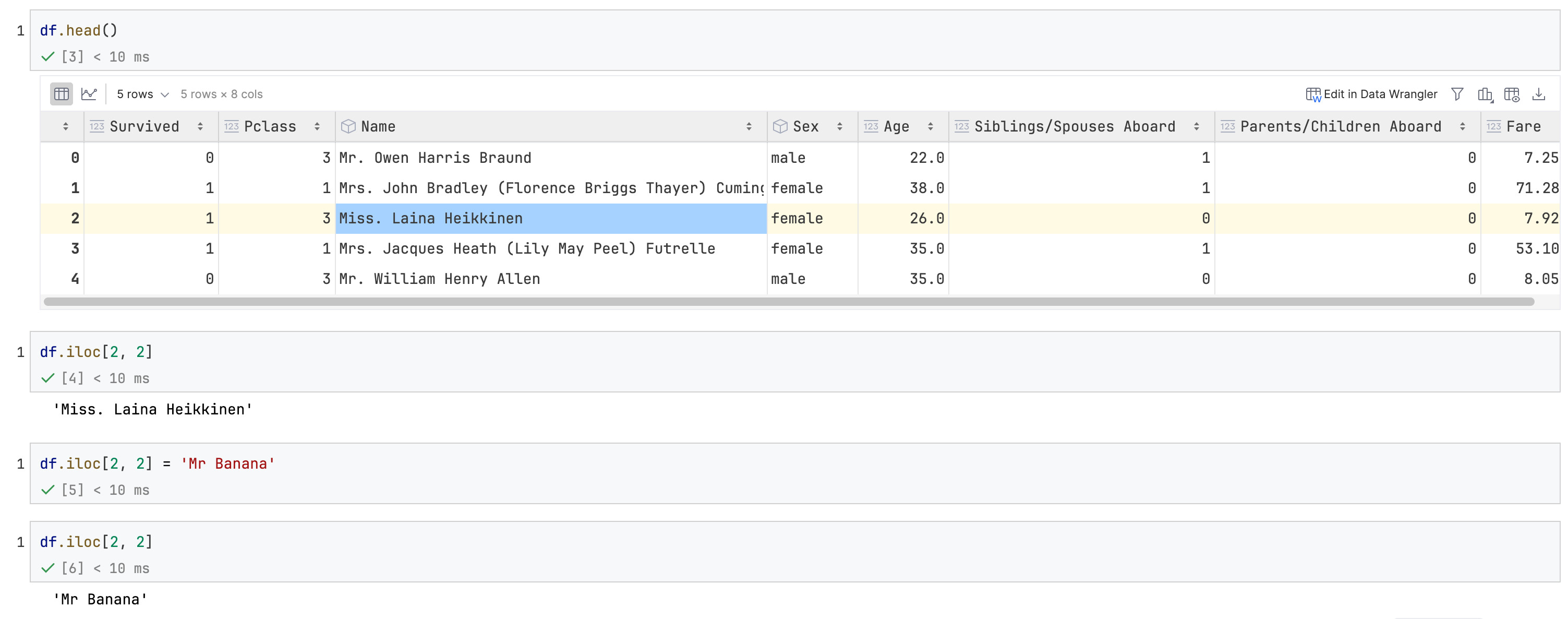
这个写法有个很重要的用途就是它既可以获取数值也可以修改数值,同时规避SettingWithCopyWarning问题,很适合我这种喜欢iloc操作的人。
在本篇笔记里面搜索SettingWithCopyWarning获取更多信息。
非iloc操作
使用列名获取一列或多列
获取多列:
使用loc获得一列或多列
实际上loc能获取行,但这里暂时不用管它,目前涉及到的所有dataframe都是用auto increment int作为索引下标的。
错误写法:

正确写法:
获得/更改 第x行yyy列的数值
这里的“第x行”容易引起歧义,可以被解释为row index,还可以被解释为物理意义上/iloc意义上的index:
row index
常用
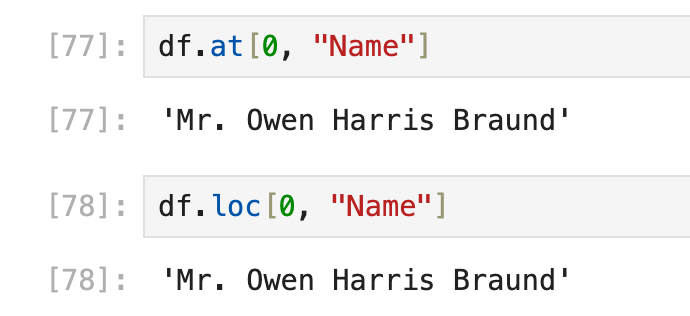
目前2种方法:使用df.loc(实际上可以选择多行、多列的多个元素),或者使用df.at(只能选择一个元素),两者在“选择单个元素”这方面的用法相同:
df.loc[row_index, "column_name"],以及df.at[row_index, "column_name"]
比如要获取第0行,"name"列的数值
需要更改数值的时候直接写在df.at/df.loc后面即可:
df.at[row_index, "column_name"] = (value)
df.loc[row_index, "column_name"] = (value)物理意义的index
如前面的笔记【来自iloc, loc和at的问题】所述,需要先用iloc,再用column name获取:
(下面的图片来自前面目录【来自iloc, loc和at的问题】的笔记)
其他loc/iloc用法
loc和iloc差不多就学到这里,其他用法以后需要了再补:
SettingWithCopyWarning与iloc, loc, at的用法
case1
来自iloc的错误使用
见下面的代码:
df['calculate_t'] = pd.Series()
for i in range(0, len(df)):
row = df.iloc[i]
calculate_t = row['distance'] / row['speed']
row['calculate_t'] = calculate_t # 错误的,这样做对df不会有任何效果,因为row = df.iloc[i]本质上是复制了df的第i列,所以后续修改都是在复制出来的第i列上进行
row.iloc[i]['calculate_t'] = calculate_t # 所以这种写法也是错误的
# 如果df的索引是完全自然数的形式,那么这种写法虽然设计思路不正确,但也不是不行
df.at[i, 'calculate_t'] = calculate_t
# 如果df的索引是完全自然数的形式,那么这种写法虽然设计思路不正确,但也不是不行
df.loc[i, 'calculate_t'] = calculate_t
# 如果一定要使用location-based index(physical index)
df.iloc[i, df.columns.get_loc('calculate_t')] = calculate_tcase2
来自一些操作df复制体的代码:
df_clean = df[['some', 'columns', 'here']]
df_clean.dropna(inplace=True) # 触发警告:SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame
df_clean = df_clean.reset_index(drop=True)上面这段代码的dropna操作并不会对df有什么影响(或者说用at/loc/iloc修改df_clean的内容也不会影响df),但还是因为其他原因(懒得学了,貌似是使用 df_clean['column'][0]=xxx 这样的写法会导致FutureWarning: ChainedAssignmentError)触发这个SettingWithCopyWarning
所以应该这么做:
df_clean = df[['some', 'columns', 'here']].copy() # copy一下
df_clean.dropna(inplace=True)
df_clean = df_clean.reset_index(drop=True)遍历dataframe每一个元素
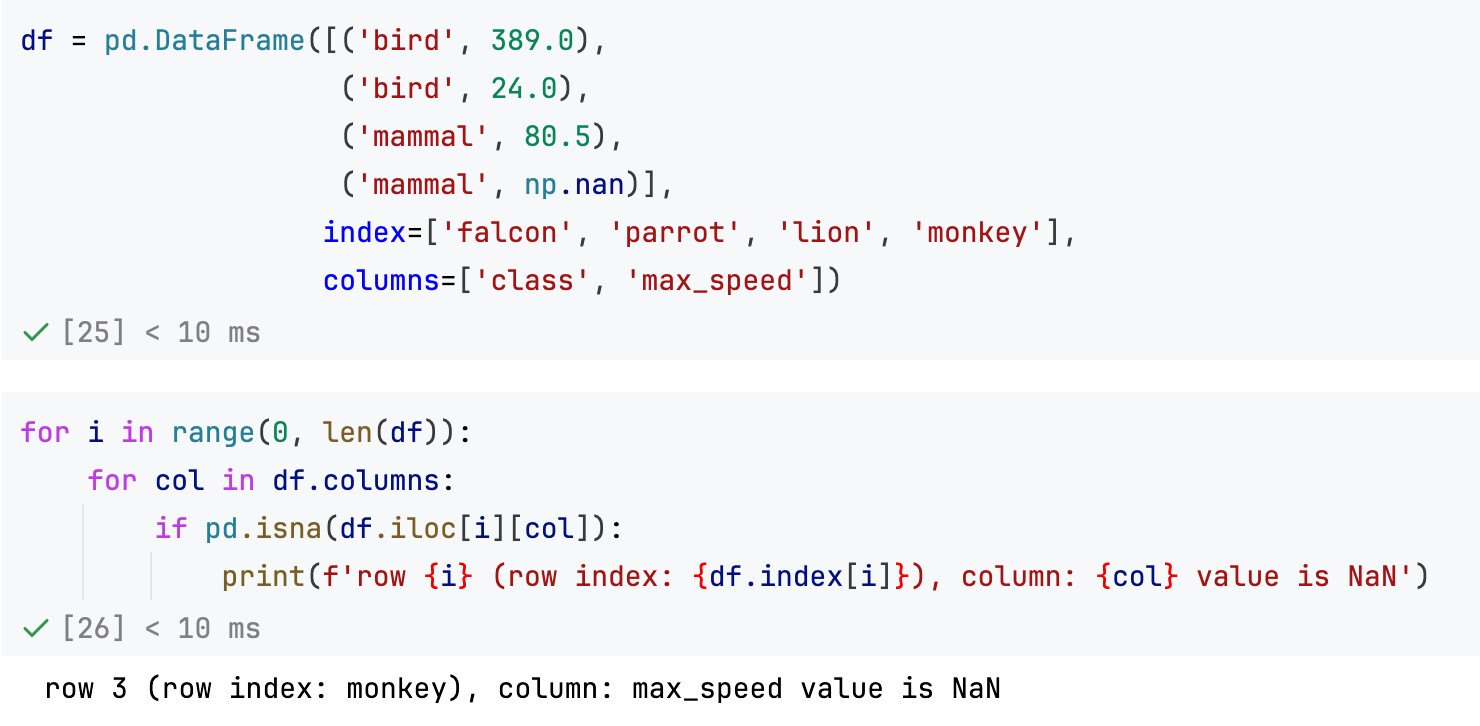
如下:(注意下面的代码无法修改df.iloc[i][col]的数值,只能获取以后用来做别的事,具体搜索SettingWithCopyWarning)

特别注意这里不要用df.at,详见本篇笔记稍早部分的内容:索引(index和positional index)
example:找出所有NaN的数值:

通过concat合并行/列
容易出现的问题
最容易出现的问题就是dataframe/series混在一起/分不清导致的结构混乱。尤其是在试图合并多行的时候,如果混入了pandas.series类型的数据,整个合并就会直接变成失败的类型。
合并多行(dataframe)
合并多行(按行合并多个结构相同的dataframe)
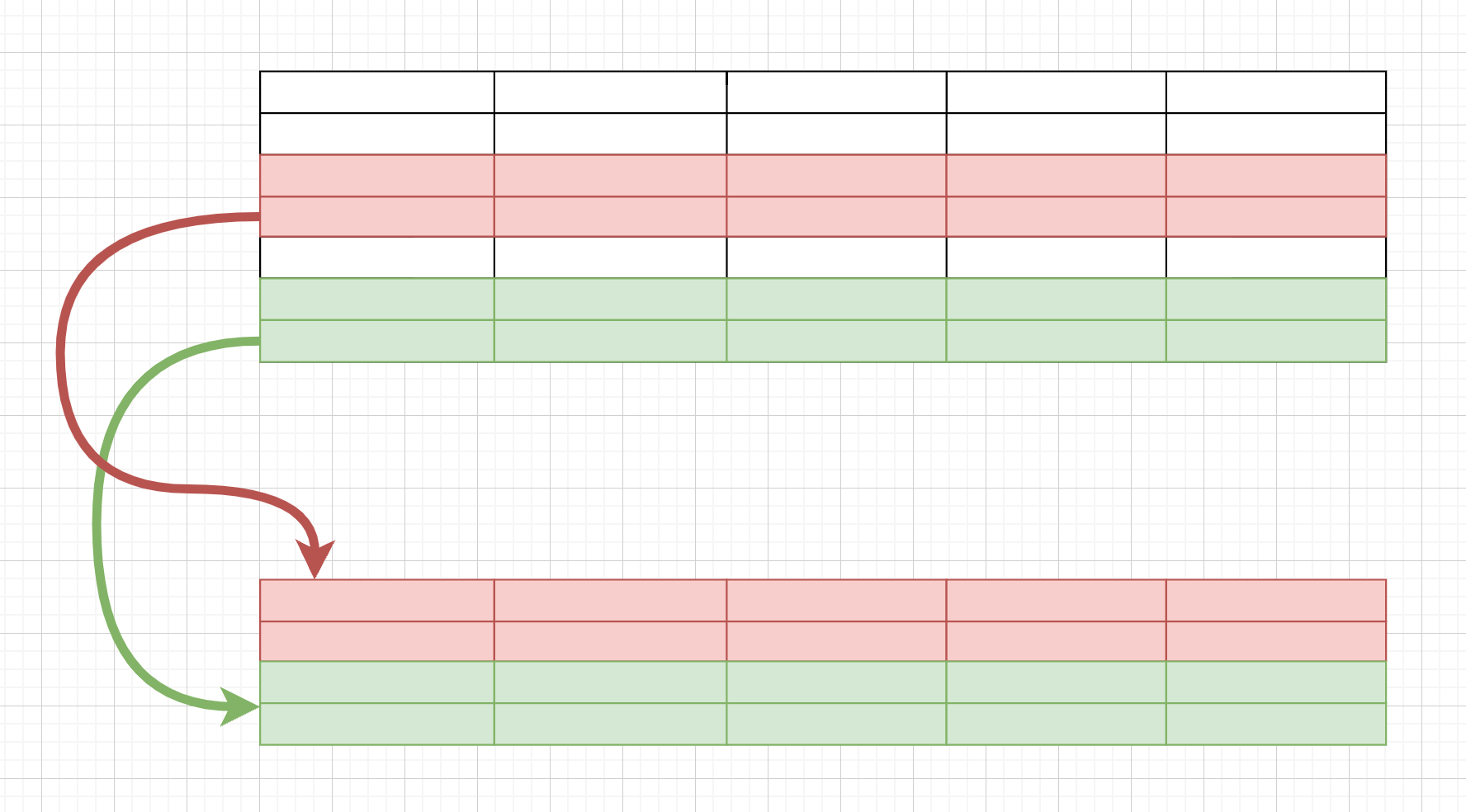
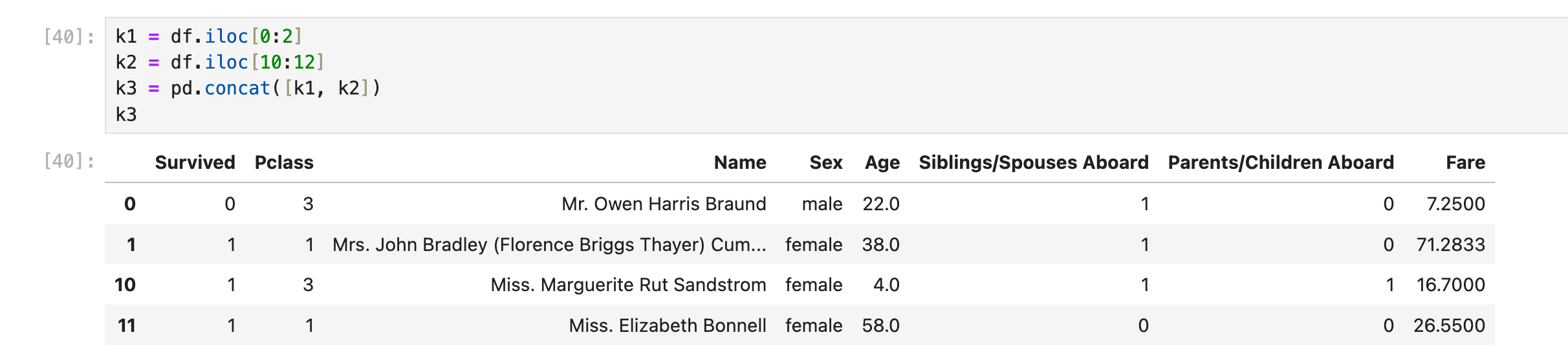
使用pd.concat([row_df1, row_df2, row_df3, ...]),这里row_df1, row_df2, ...是pandas.dataframe类型的数据
合并多行(series和dataframe)
首先要明确一点,就是:pd.concat([r1, r2, ...])的时候,r1一定要是dataframe类型的一行,而不能是series类型的一行。
错误示范
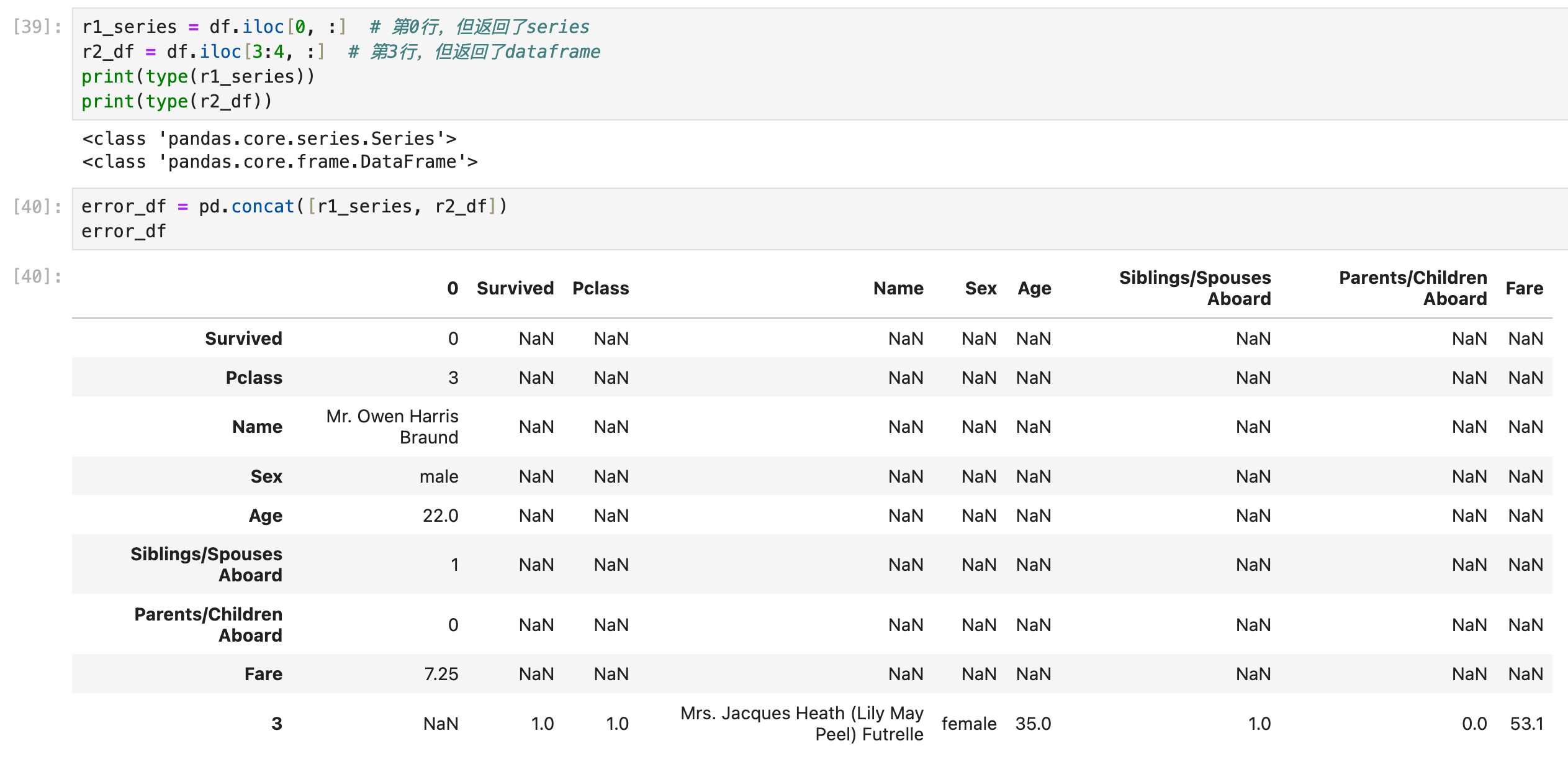
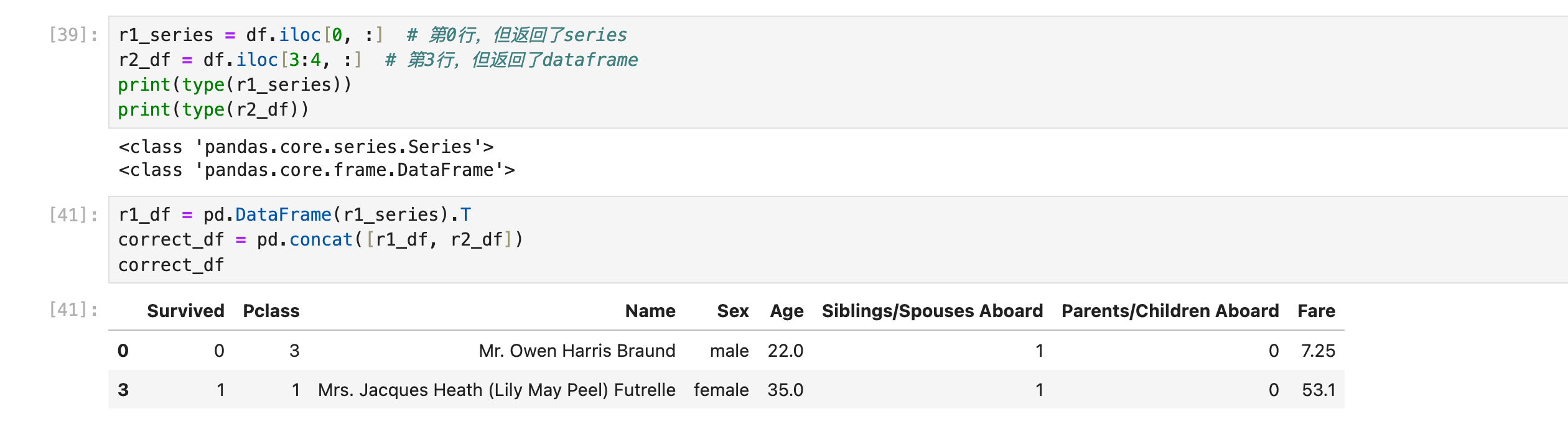
正确方法之一:把所有series变成dataframe(一行),然后再参与多行的concat
合并多列(dataframe和series)
注意:这部分内容和下面的目录【Dataframe合并List,List作为新的一行】本质上是在解决相同的问题
上面有关行合并的例子里,series和dataframe数据是不能混合在一起进行concat行合并的,但列合并就没有这些限制了:
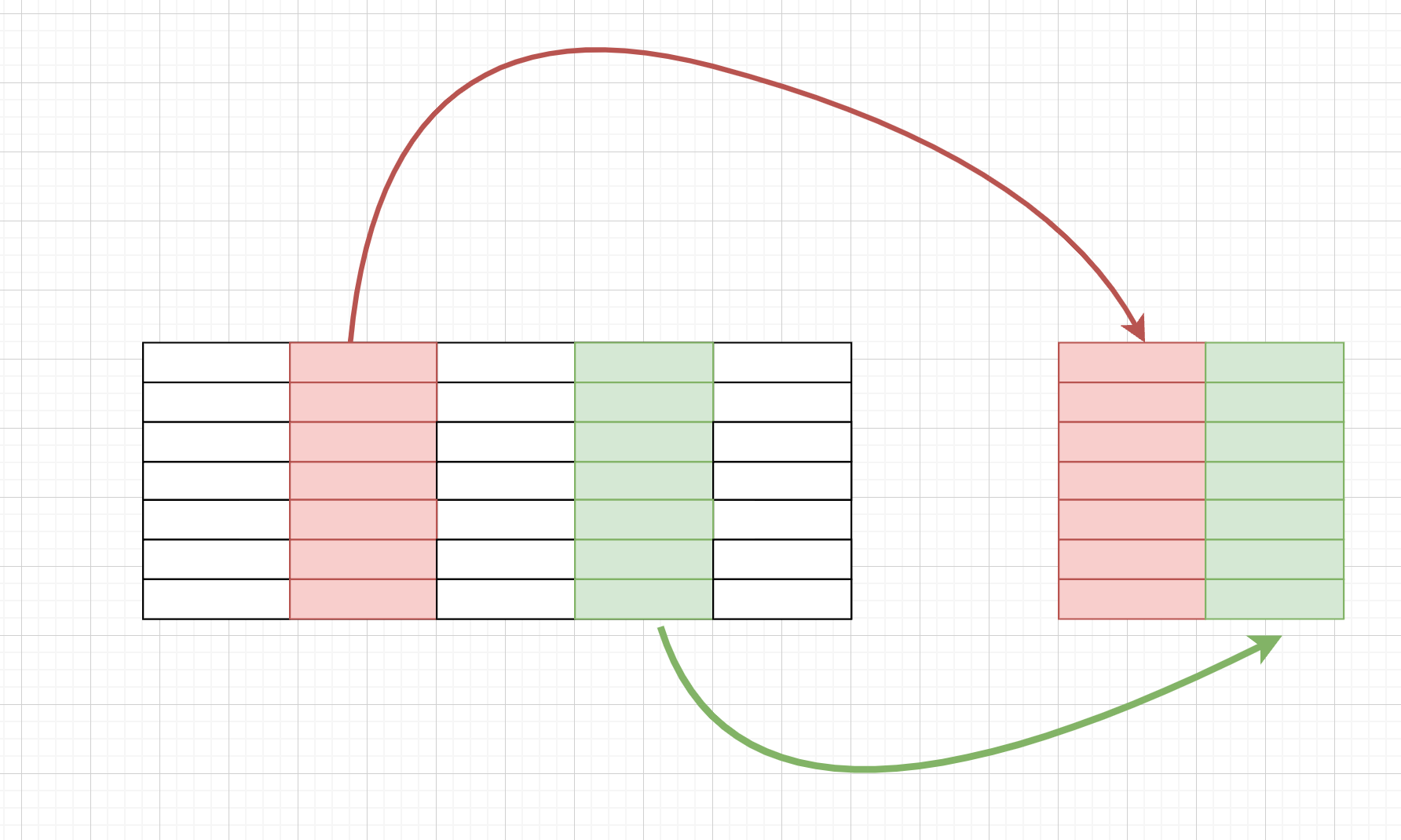
使用pd.concat([col1, col2, col3, ...], axis=1),col1, col2, ... 既可以是series,也可以是dataframe
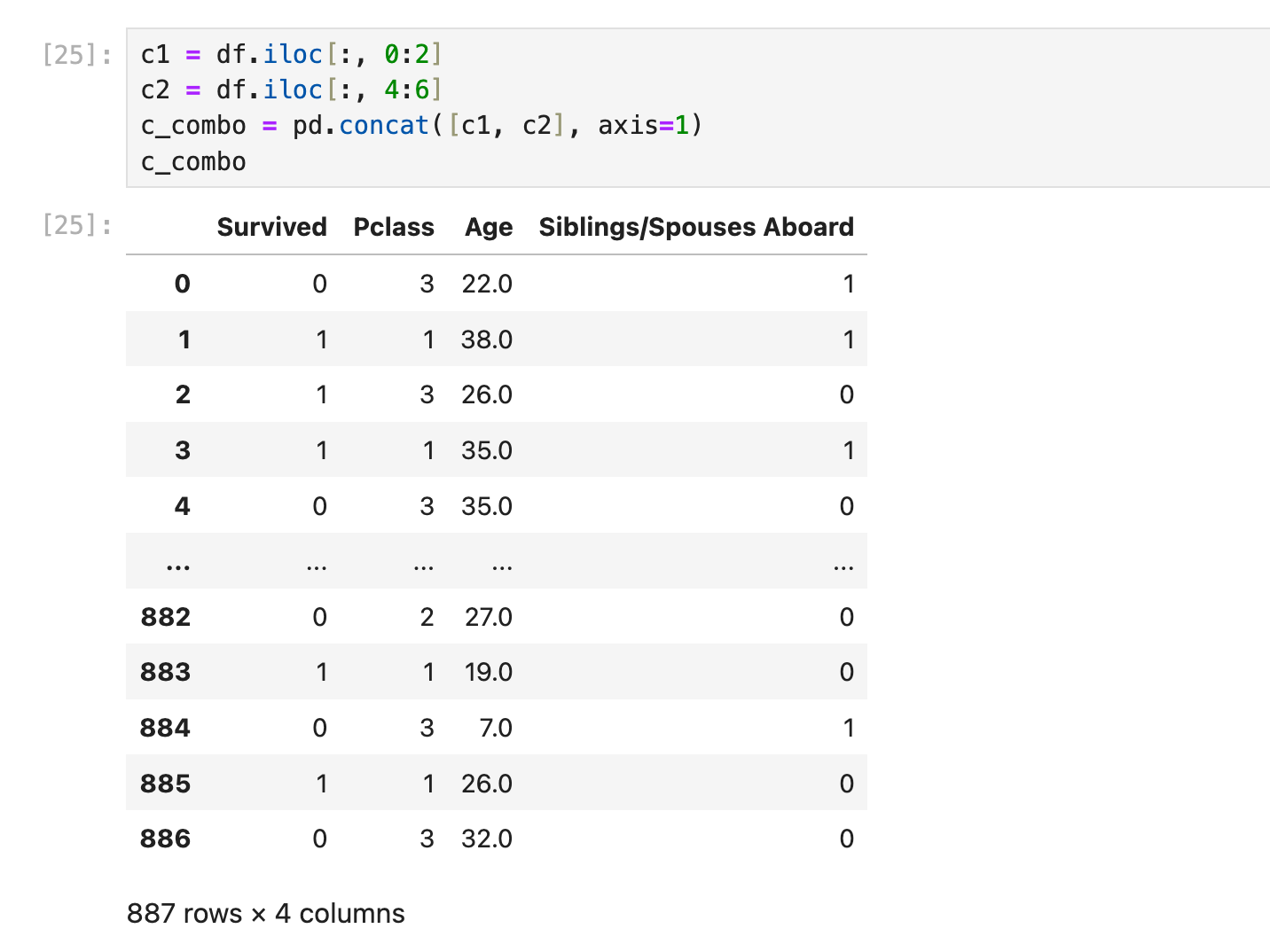
example:合并2列(2个dataframe)
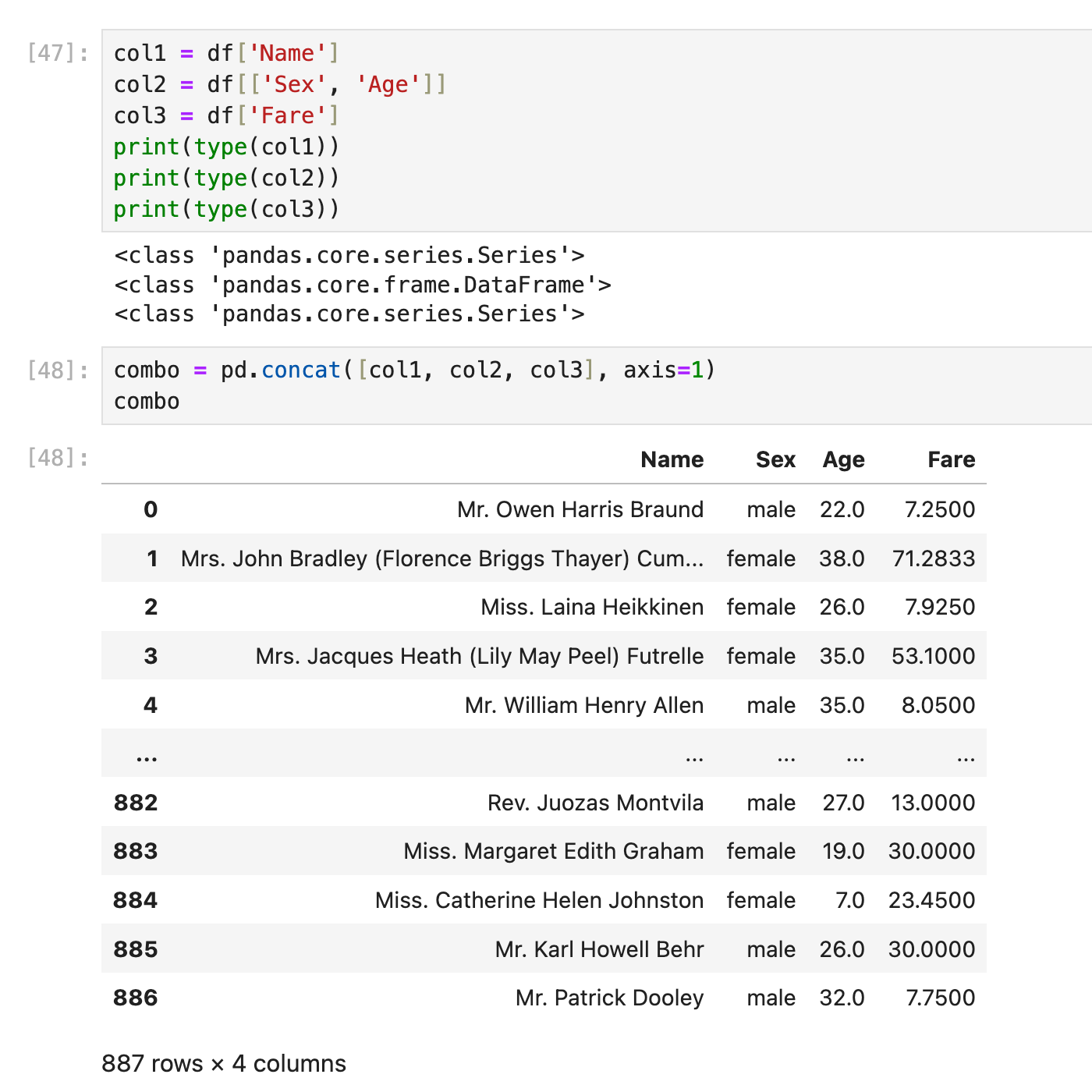
example:合并3列(dataframe+series的混合)
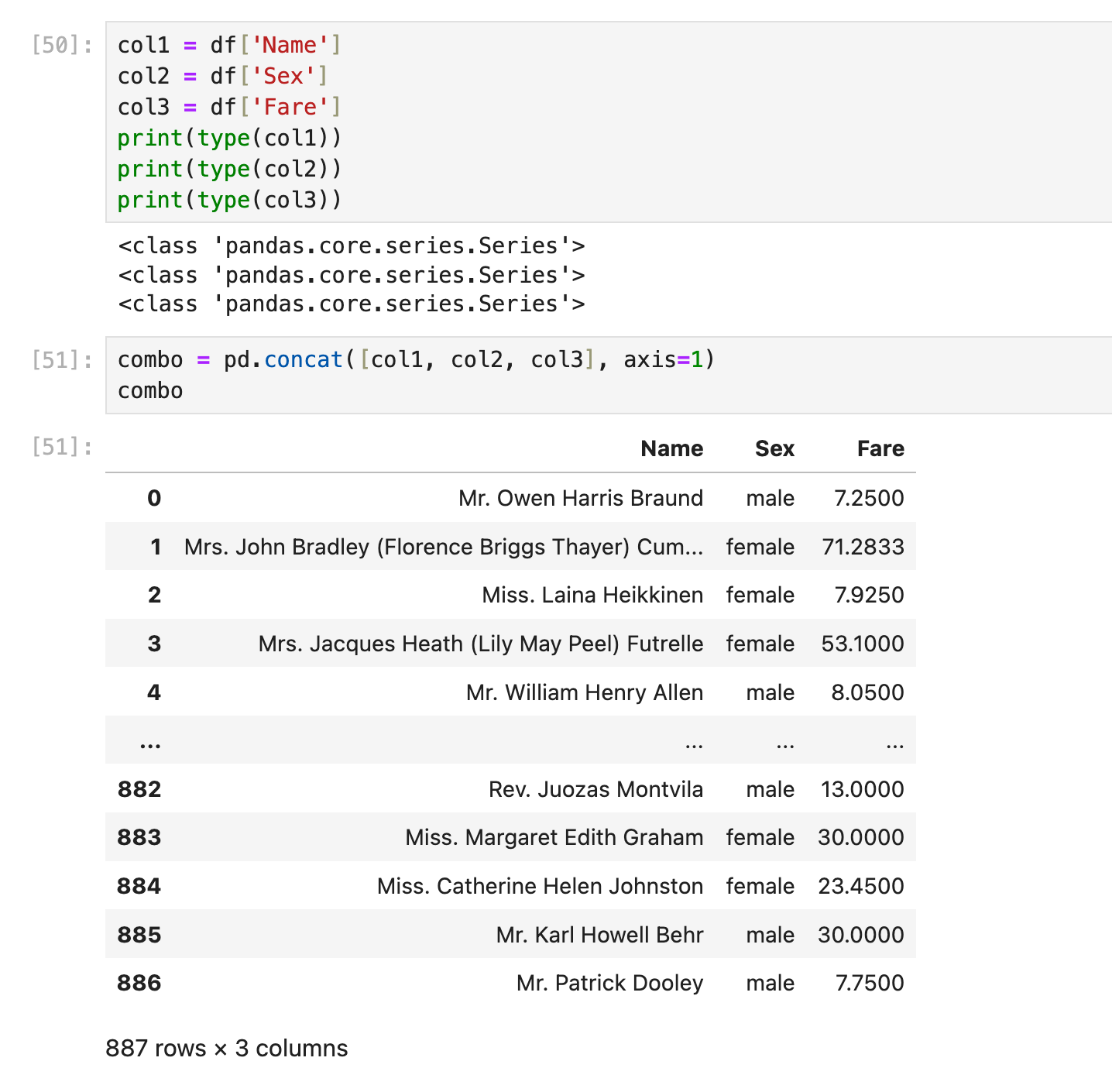
example: 合并3列(全部都是series)
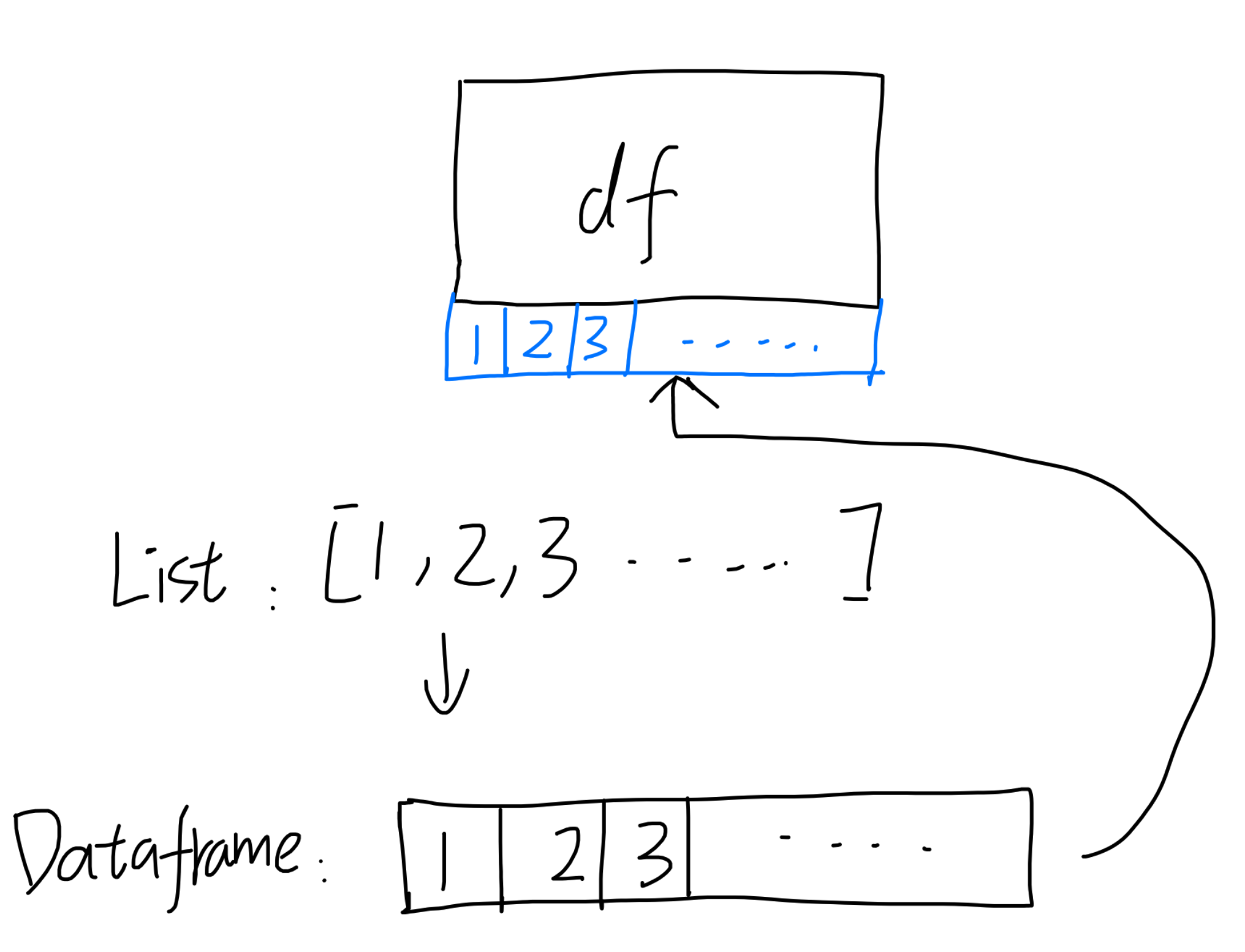
往df加List,List作为新的一列
如果前面有关【合并多行/多列/dataframe/series】的限制搞懂了,现在应该是可以很容易把python List(或者numpy array)类型的数据结构糊上来的。要注意,生成Series的时候最好指定name,这样合并以后就直接有column name了:
往df加List,List作为新的一行
常见错误
新的一行则要难一些,因为涉及到了很多新的内容,比如“列名指定问题”,首先,由一个List直接变为“一行dataframe”而不经过任何column name命名,这样的dataframe是无法正确合并到原本的df里面去的:
错误的方法
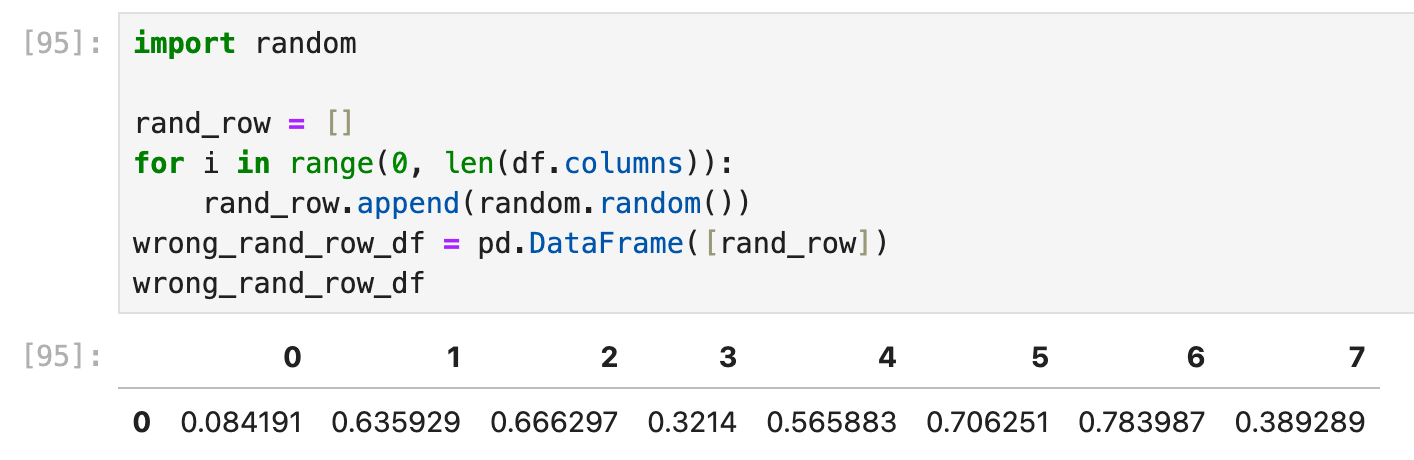
强行合并会带来这样的df:

正确方法1:指定dataframe column name
路线:List -> dataframe(指定dataframe column name) -> concat
正确的方法:使用list创建dataframe(一行)的时候指定column names,且与原本的dataframe保持一致:(这里有columns=df.columns的方法,可以直接指定所有列名,不需要一个一个自己去定义)
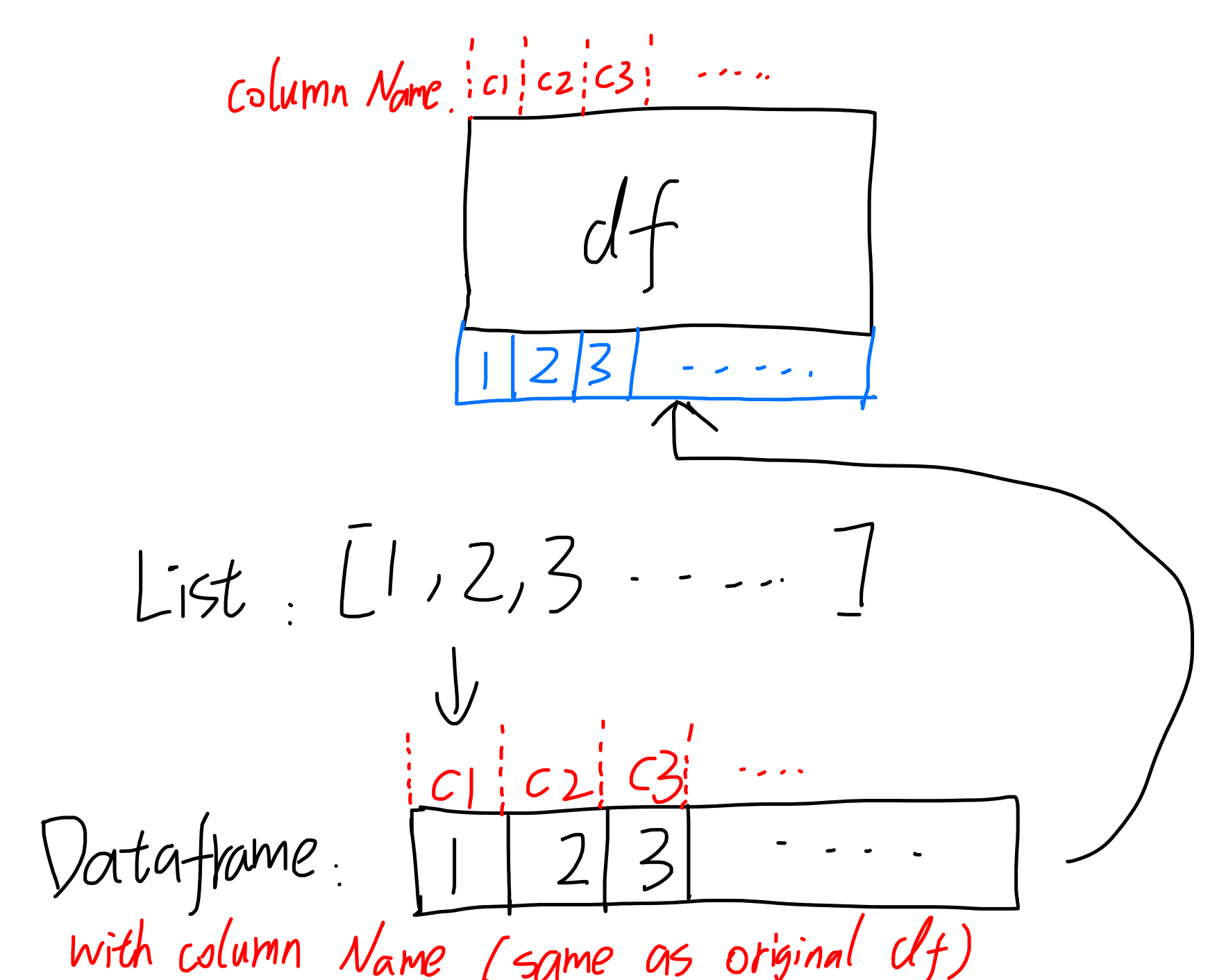
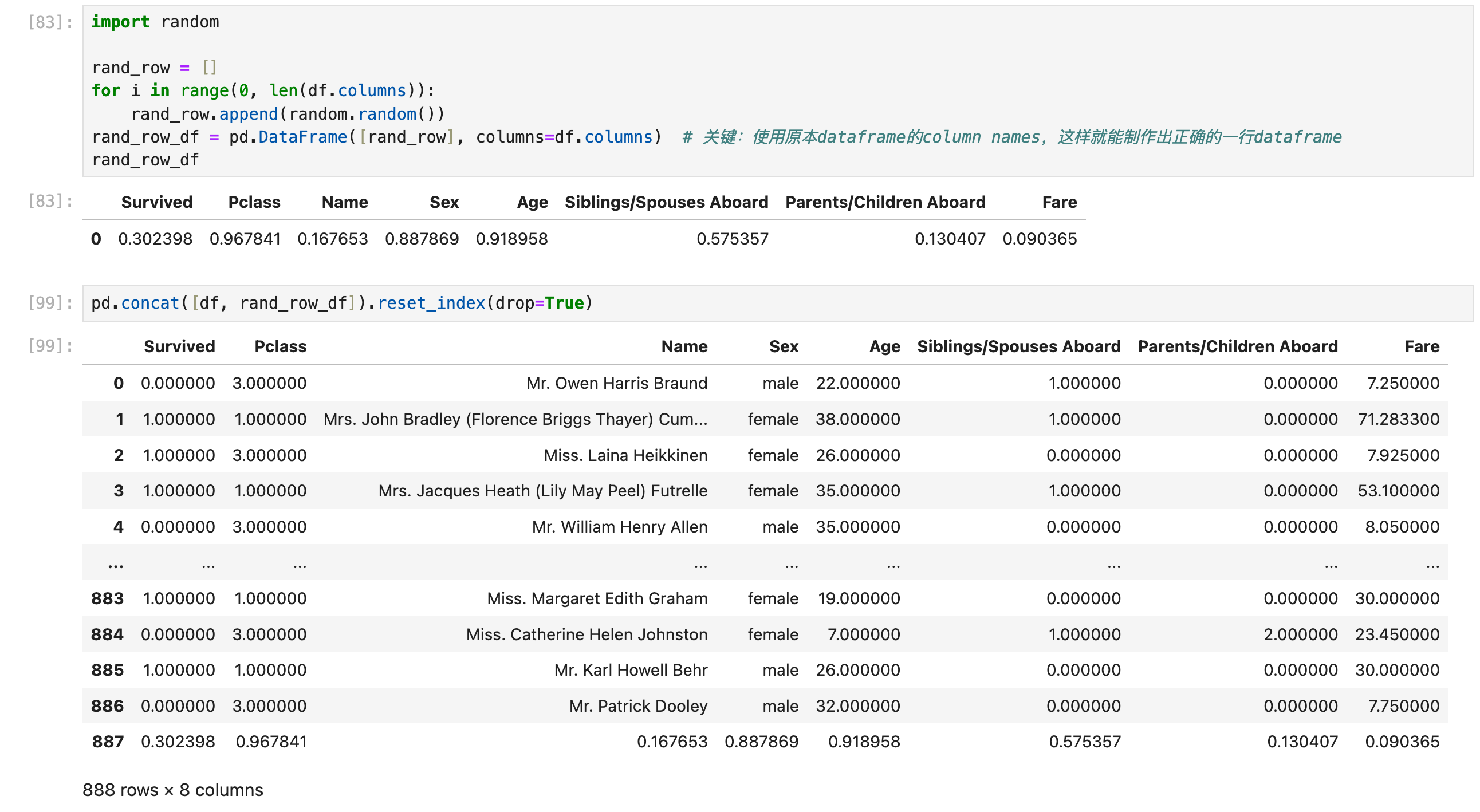
正确方法2:指定Series index
路线:List -> Series(指定Series index) -> Dataframe -> concat
pd.Series([v1, v2, v3, v4], index = ['A', 'B', 'C', 'D'])其实相对于上面的方法(指定dataframe column names)还多了一层,使用的也是df.columns,所以一般不用这种方法
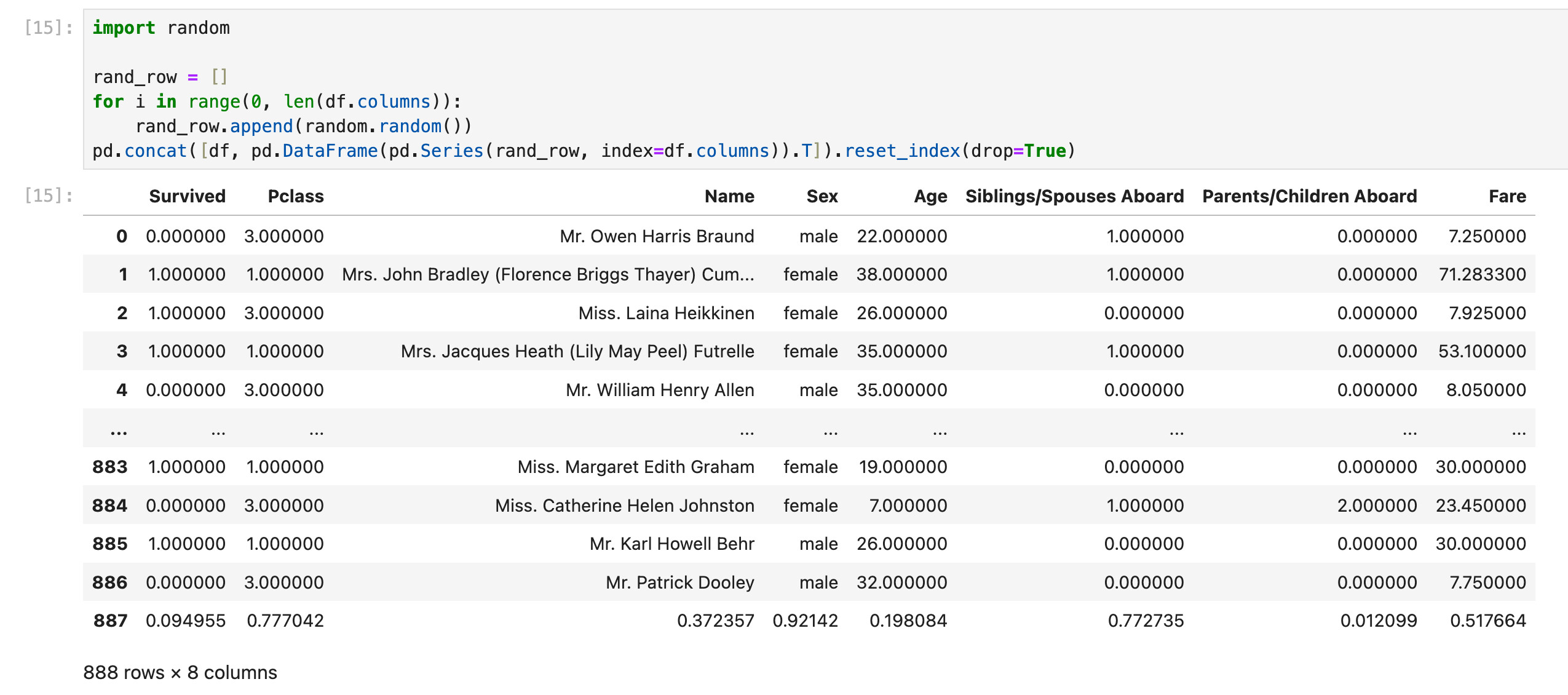
更高效的方法
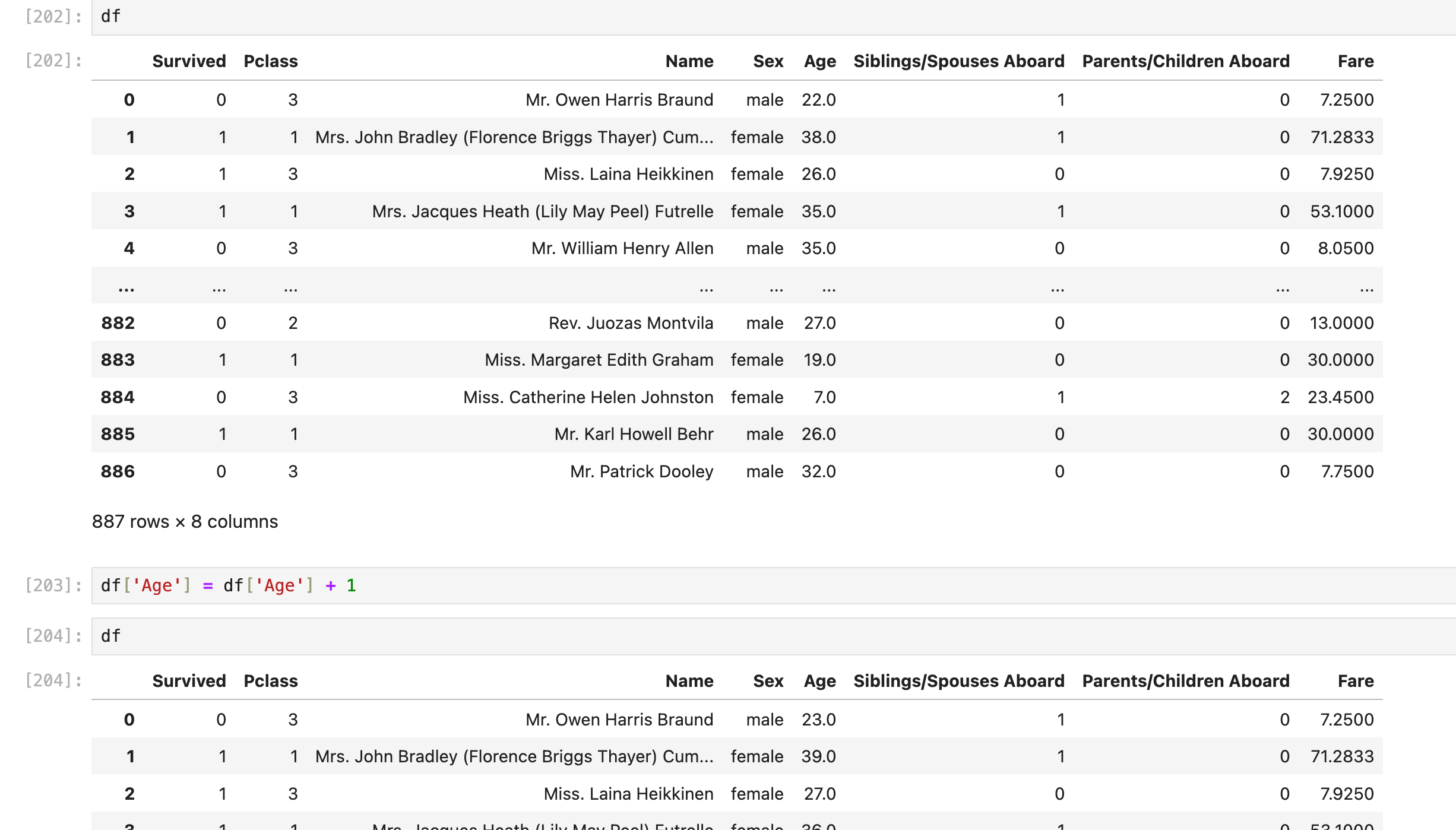
见本篇笔记补充的内容(补充在前面)

合并/过滤大量的列
假设我事先存好了一个List of column names,格式如下:
col_lst = ['Pclass', 'Name', 'Sex', 'Age']现在我要基于这个col_lst过滤出一个仅包含这些column names的dataframe。
方法1:直接暴力for循环 + concat:先构建一个空df,然后一列一列地往上面糊
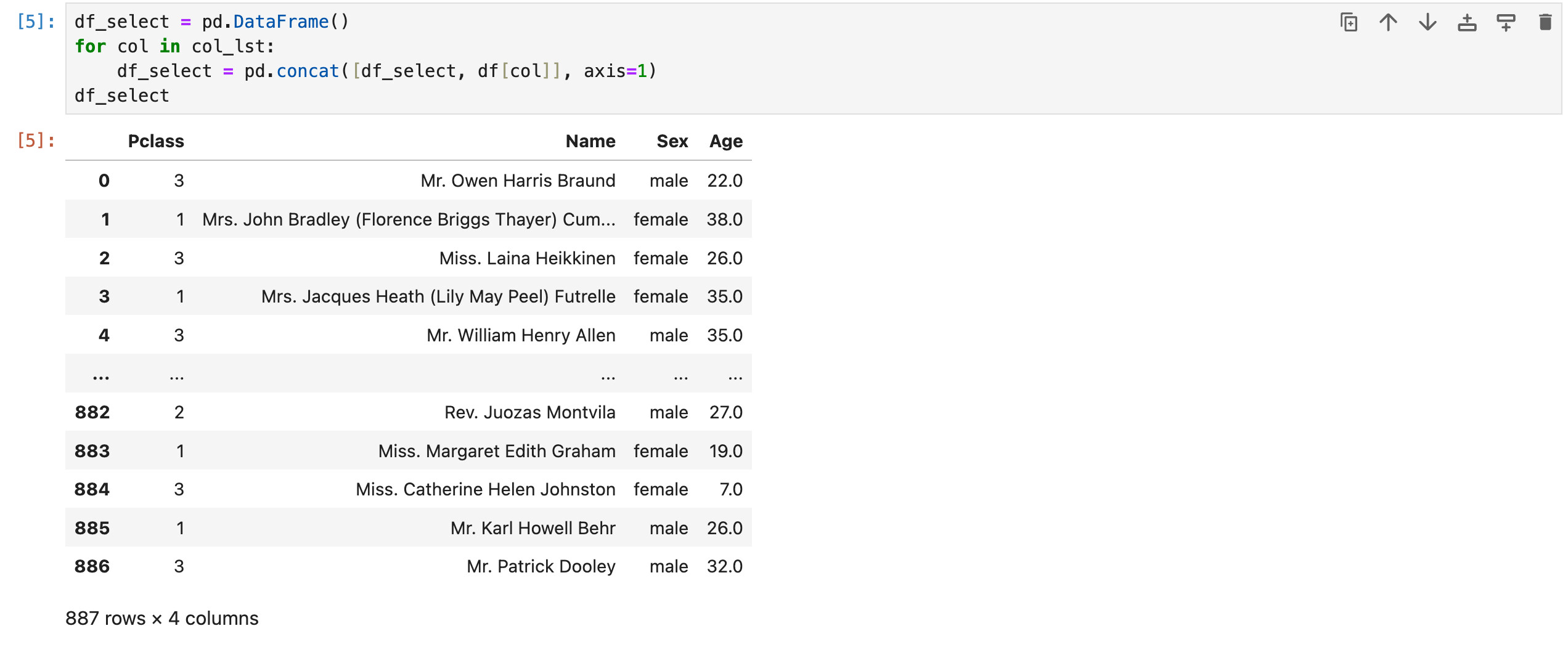
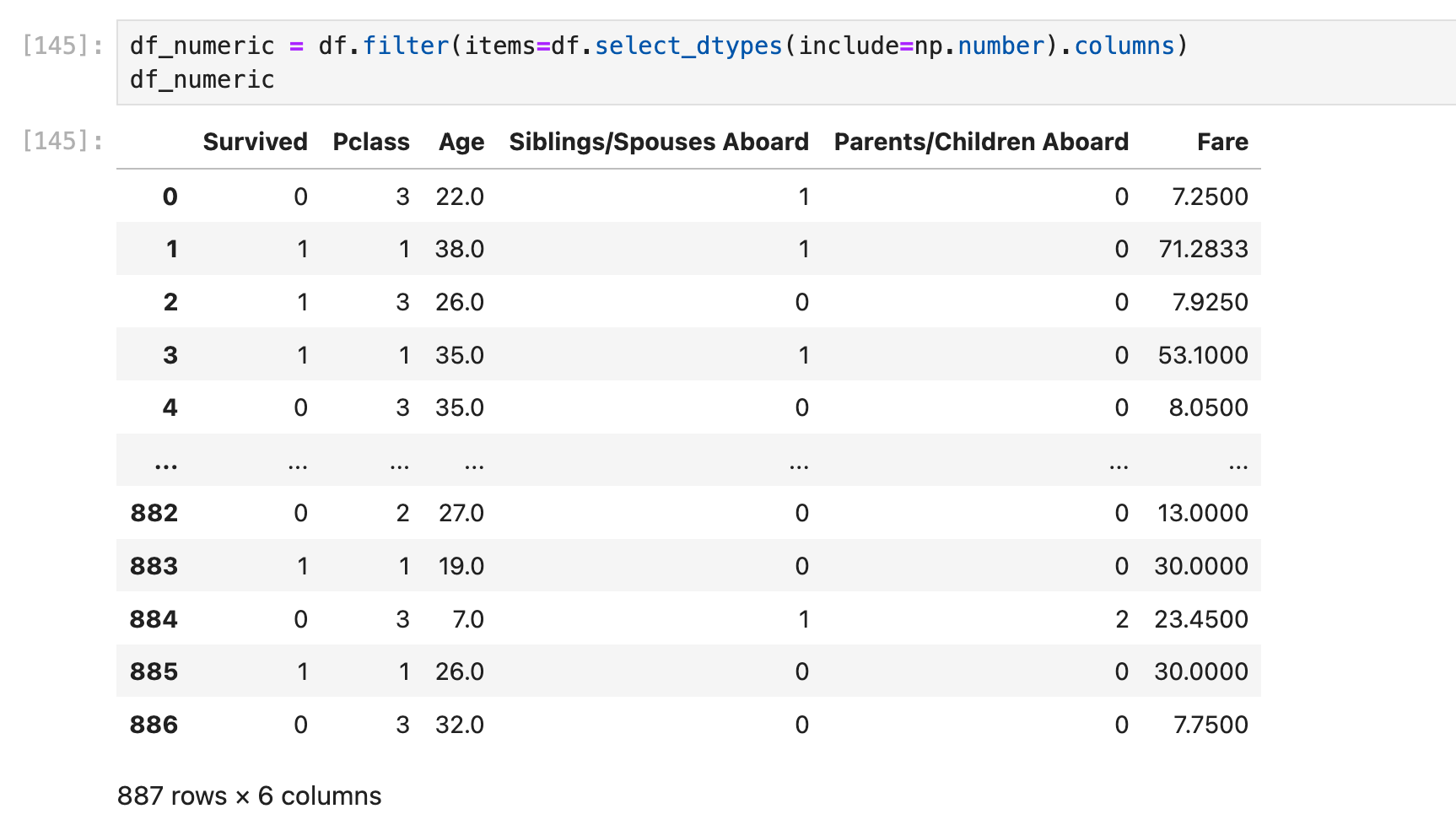
方法2:使用df.filter()
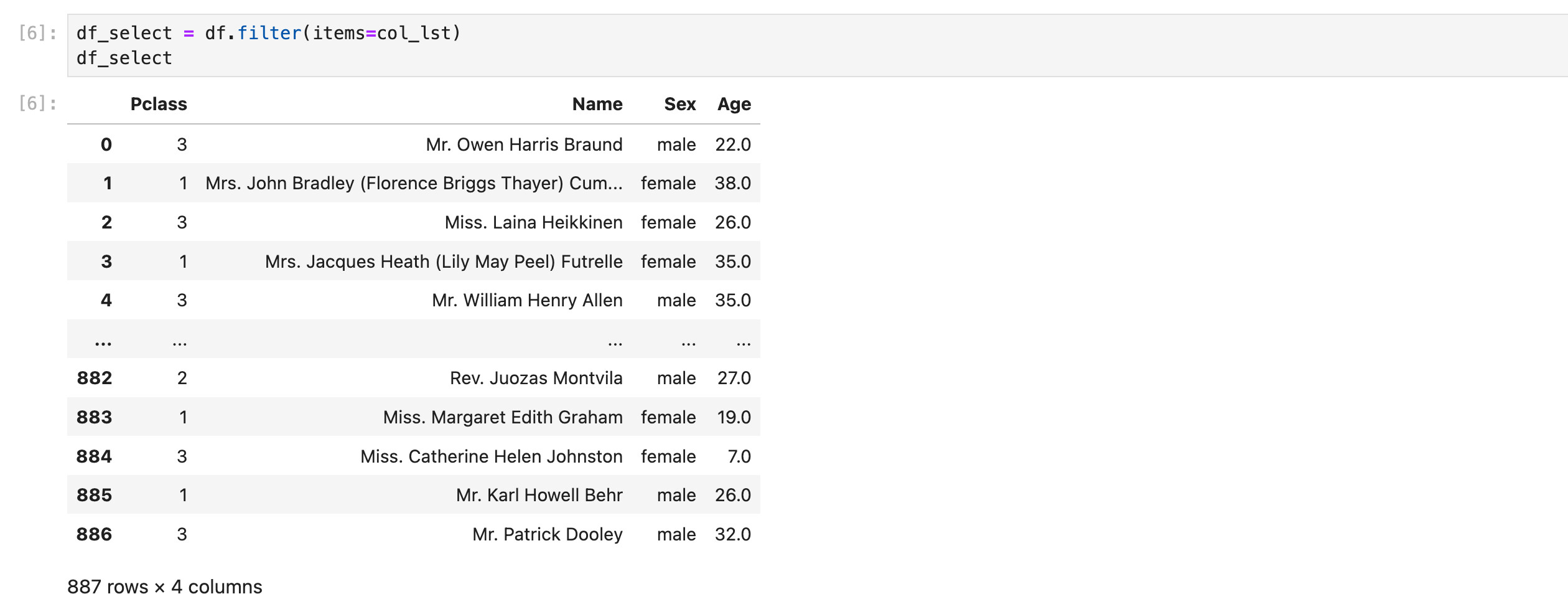
再来一个例子:
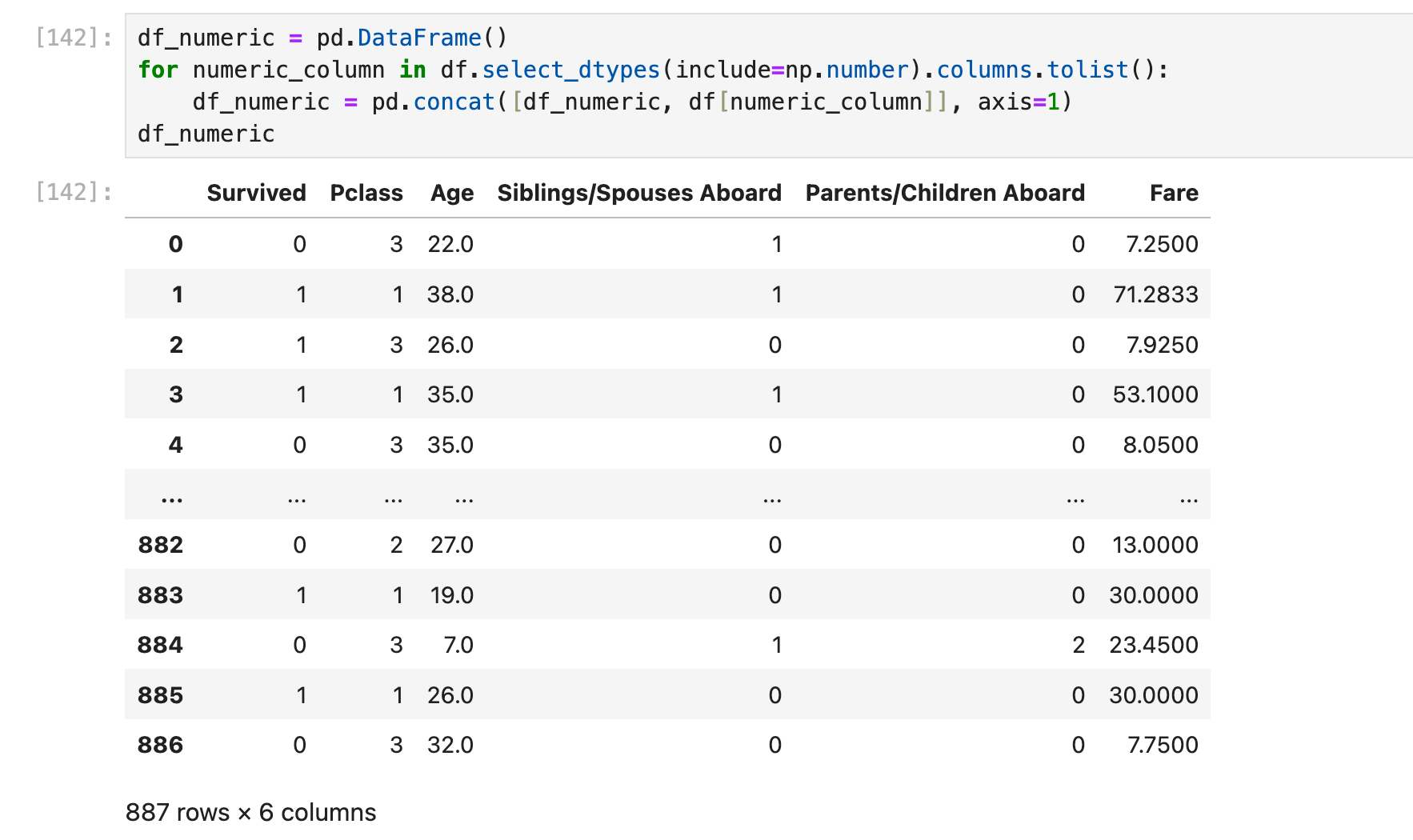
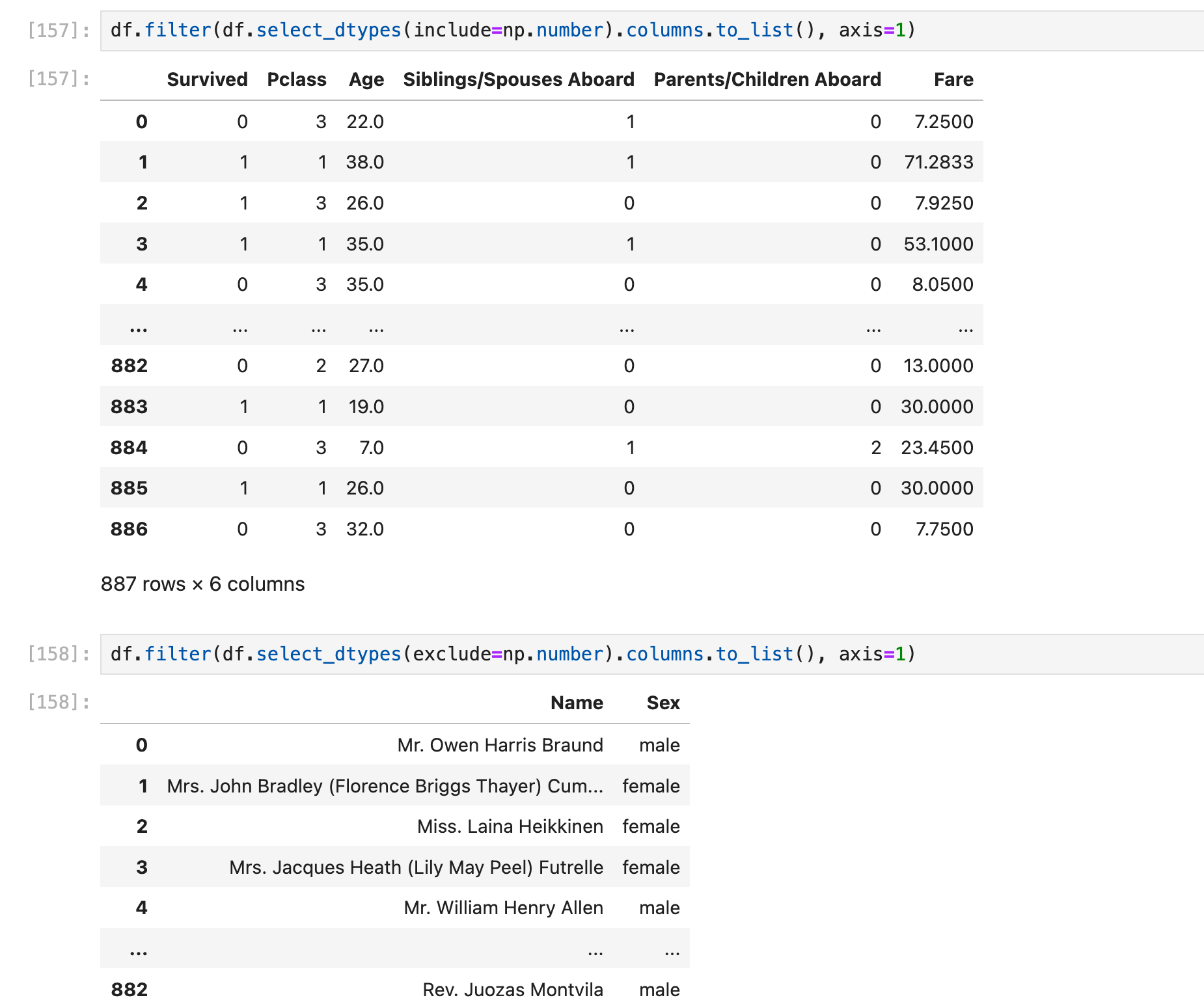
场景:把所有numeric columns抽出来单独组成一个dataframe:
方法1:
步骤是,先构建一个空df,然后一列一列地往上面糊:
当然df.filter()可以更简单:
NaN
判断:
鉴于这部分内容经常容易写错,特意放在前面
(单个数值判断)使用pd.isna(object)
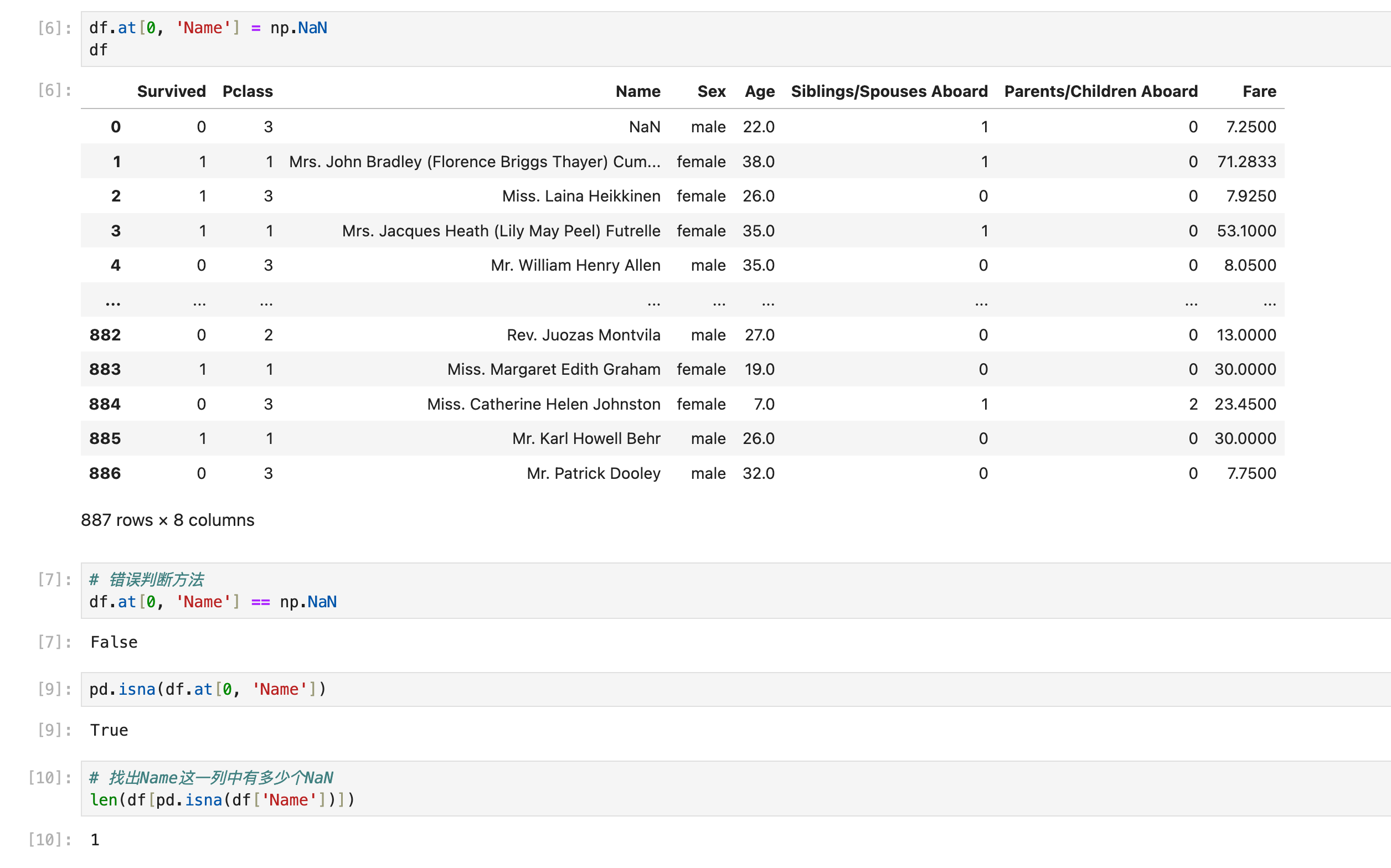
移除:
df.dropna():有很多用法,但最常用的就是直接用(只要这一行带有NaN,那就去掉这一行):

还可以用来判断df里面是否含有NaN:

如果要计算某一列/某几列或者整个df的NaN个数:针对一列(Series)使用isna().sum(), 针对多列(dataframe)使用isna().sum().sum():
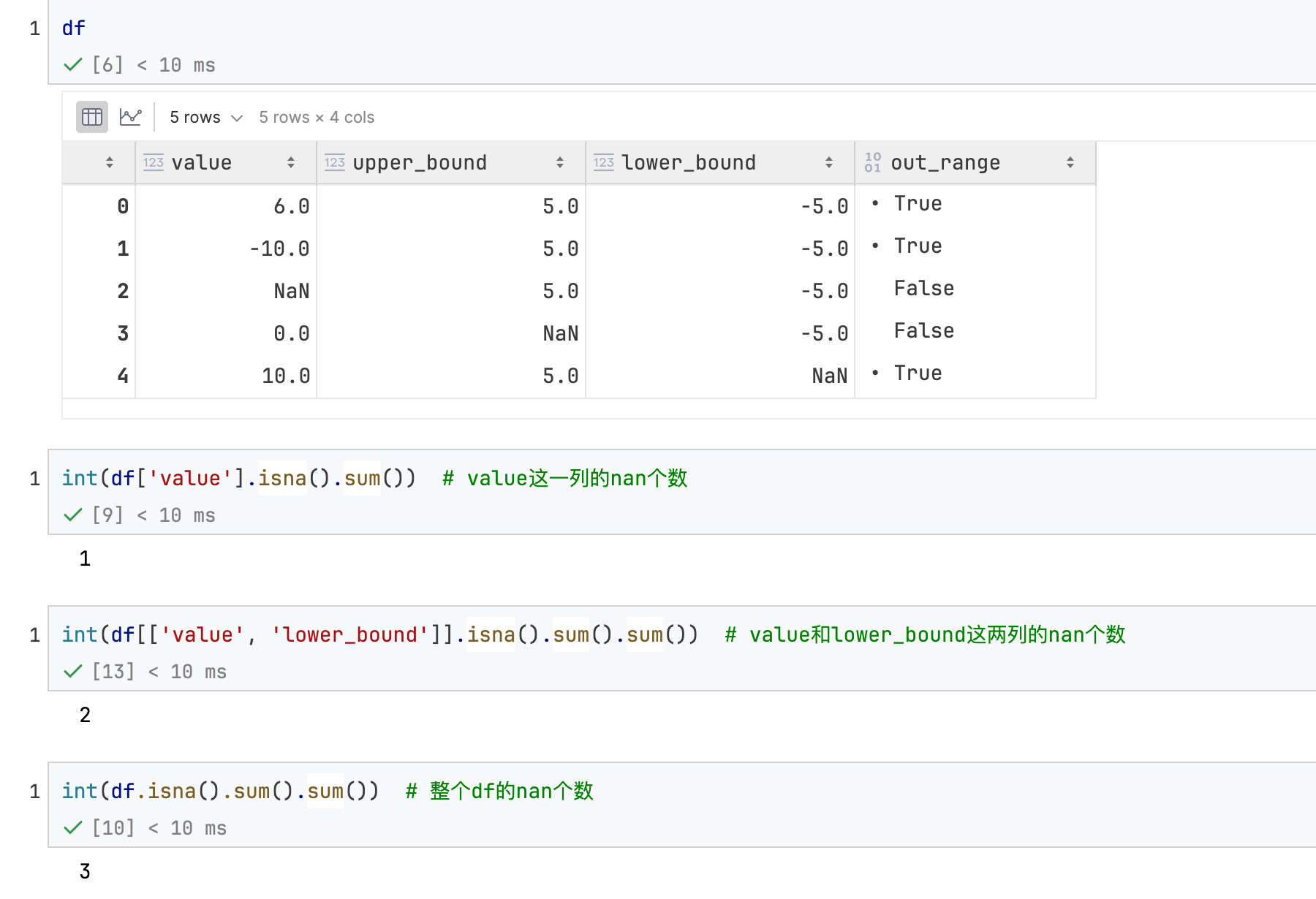
NaN在数值大小的判断中表现如下:

体现NaN作用的额外代码:
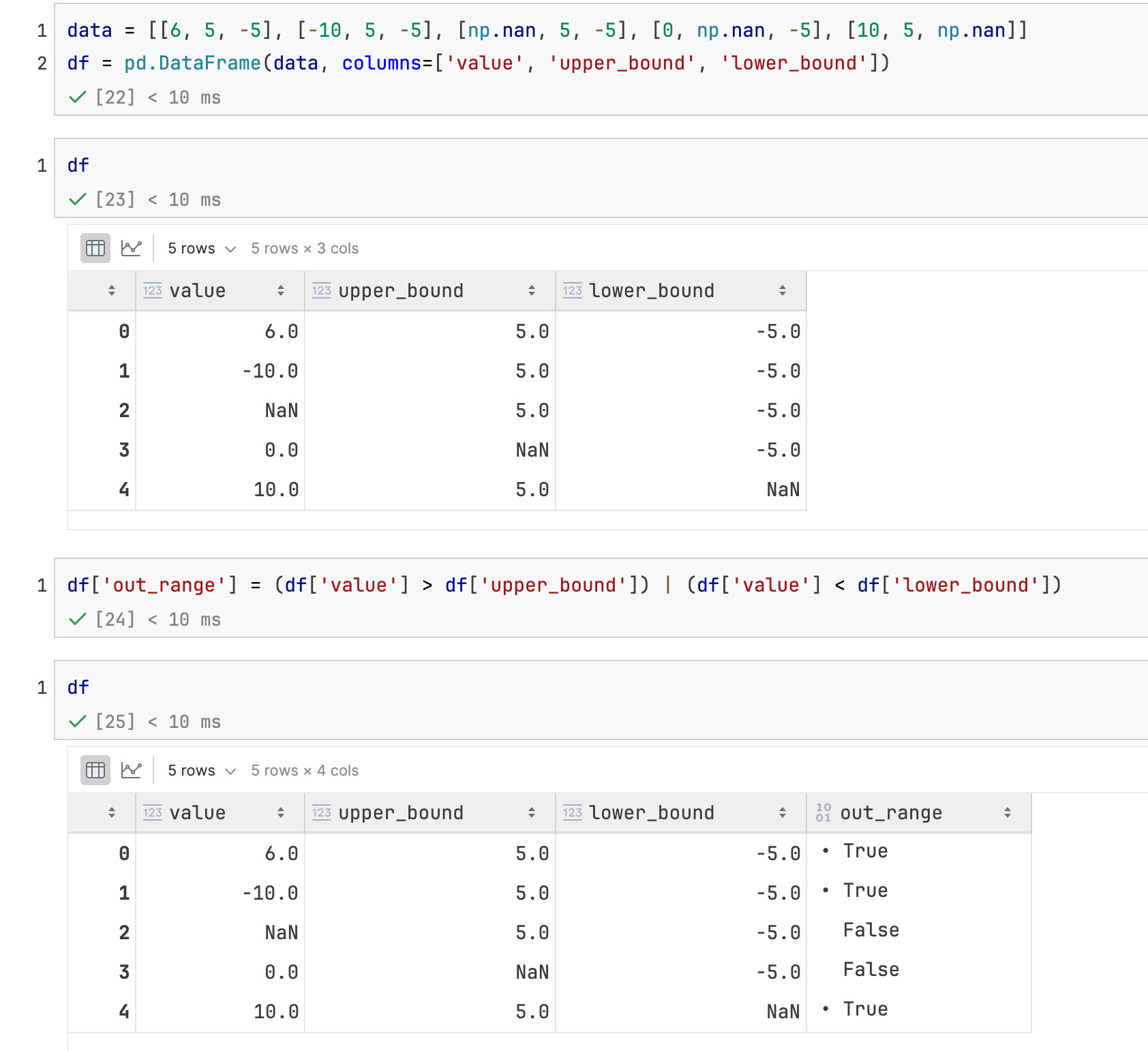
类SQL查询操作
pandas逻辑符号

select * where
select * from df_table where Sex='female' and Age>=48;
df[(df['Sex'] == 'female') & (df['Age'] >=48)]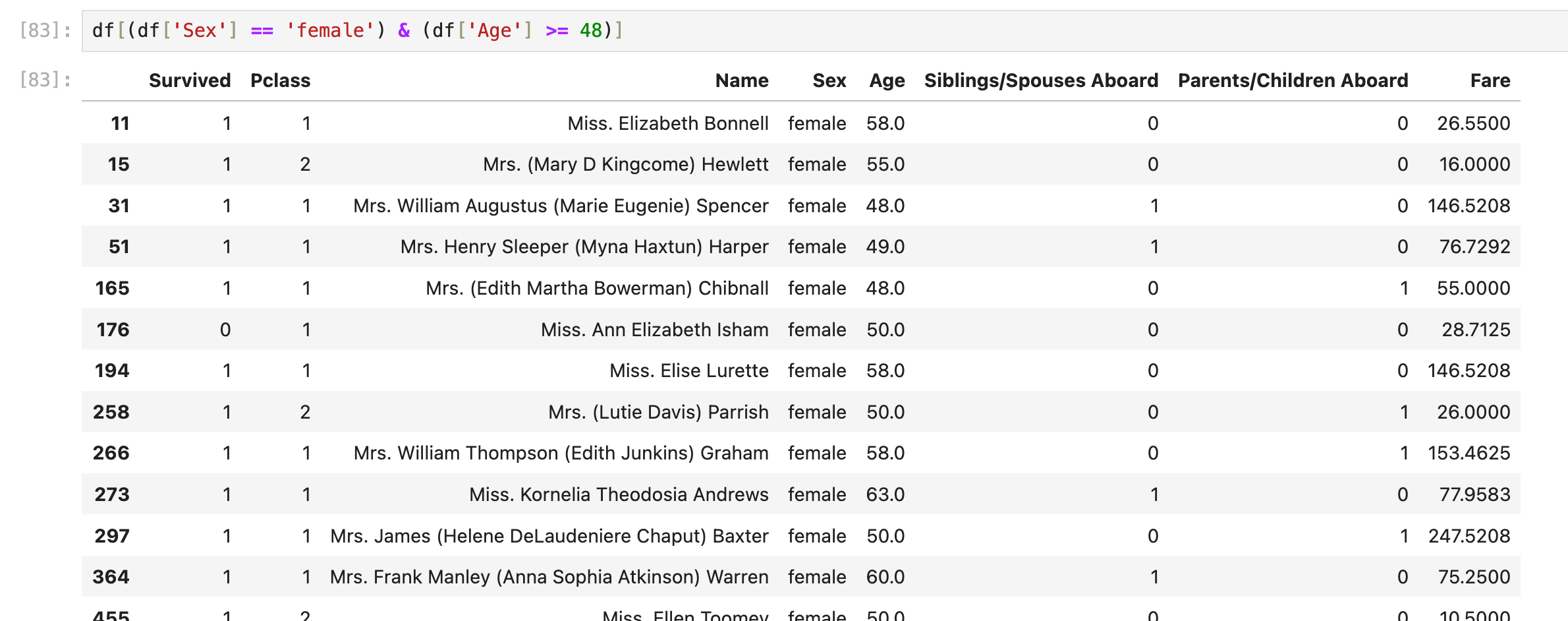
如果是OR逻辑:
select * from df_table where Sex='female' or Age>=48;
df[(df['Sex'] == 'female') | (df['Age'] >=48)]特别注意:使用&或者|逻辑符号时,两边的括号()不能省略!
df[ (df['Sex'] == 'female') | (df['Age'] >=48) ] # 正确
df[df['Sex'] == 'female'| df['Age'] >=48] # 错误还有另一种基于loc的写法:
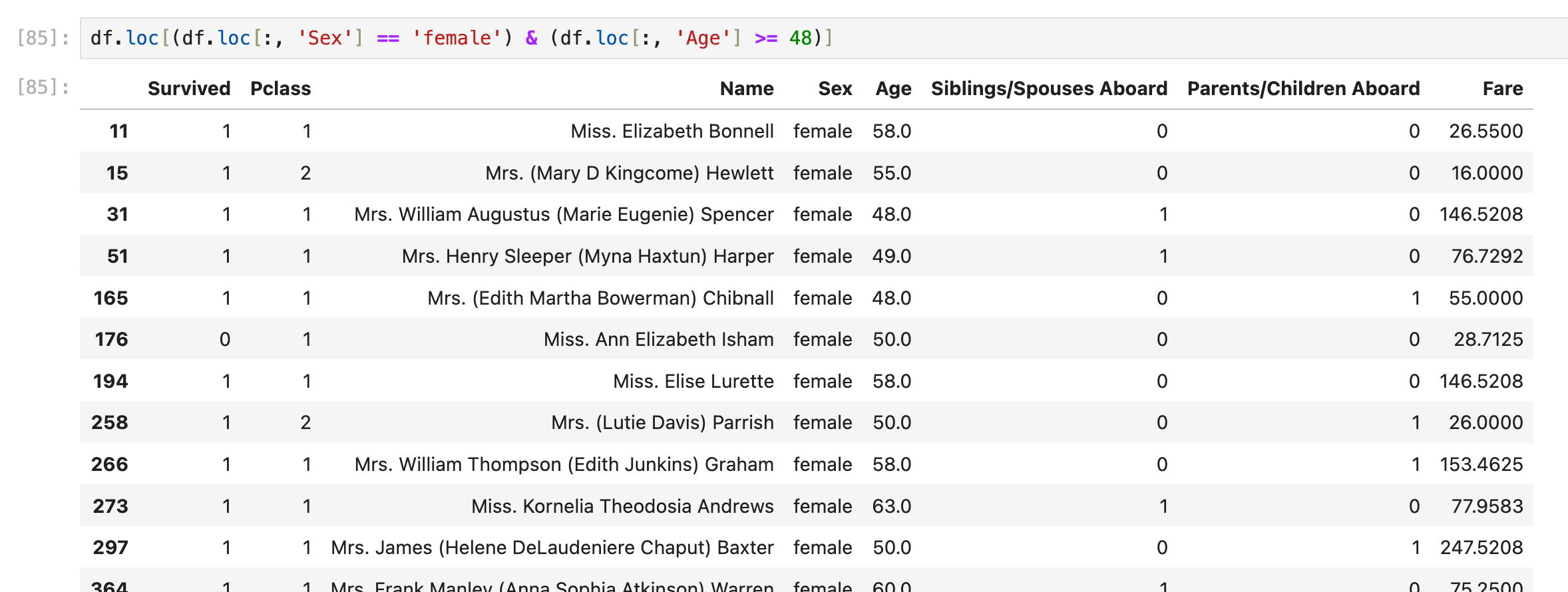
select (column1, column2) where
select Sex, Age from df_table where Sex='female' and Age>=48;其实就是把上一条(select * where)的语句再包装一层column selection:
df[(df['Sex'] == 'female') & (df['Age'] >= 48)][['Sex', 'Age']]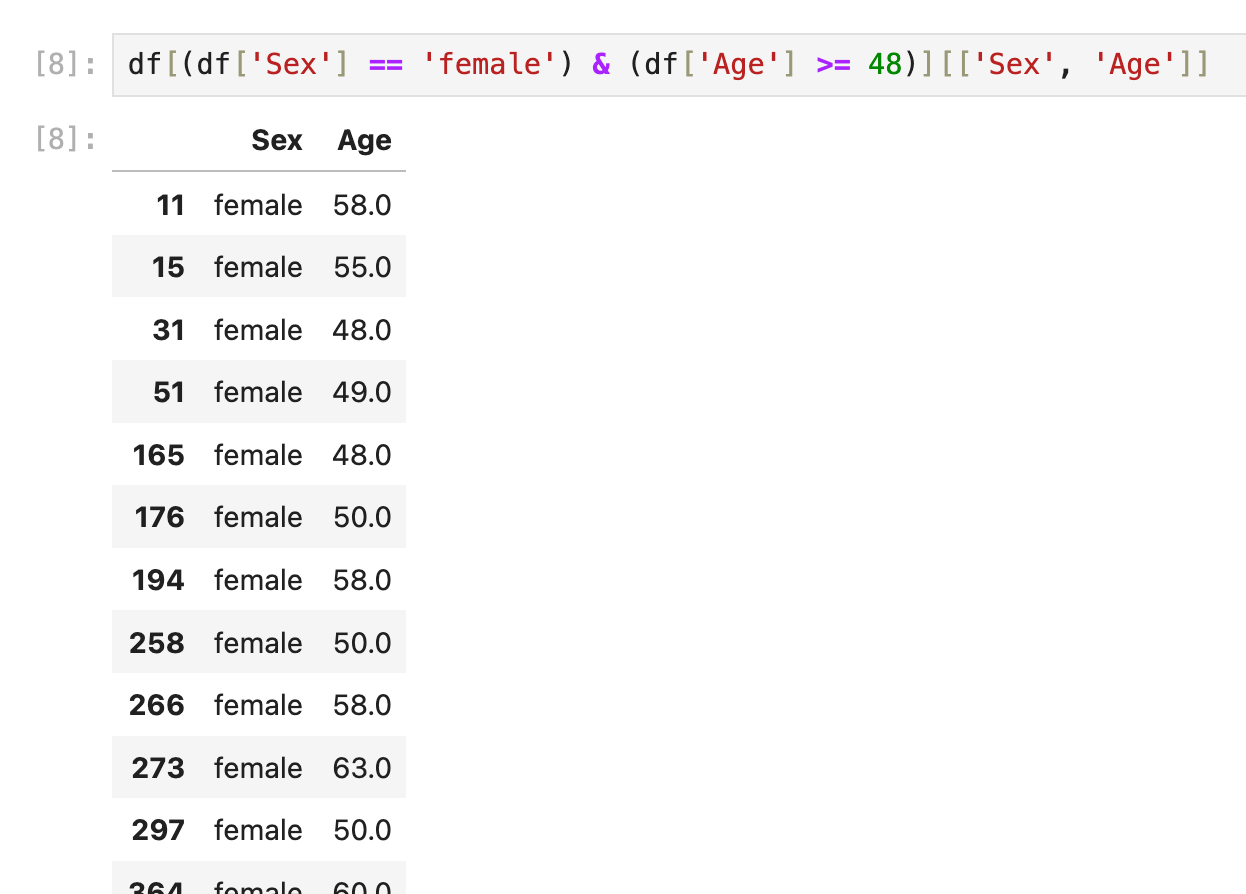
select COUNT(*) where
其实就是把上面select * where的代码最外面包一层len()
len(df[(df['Sex'] == 'female') & (df['Age'] >= 48)])
select distinct(查找一列/多列的不重复元素)
简单统计很有用
使用groupby,但目前暂时不需要复杂的groupby用法,只需要:1,获取distinct values;2,获取COUNT(distinct values)
通过df.groupby(['xxxx']).groups获取的是一个dict,其中key是那些不重复的元素,value是这些元素出现的index


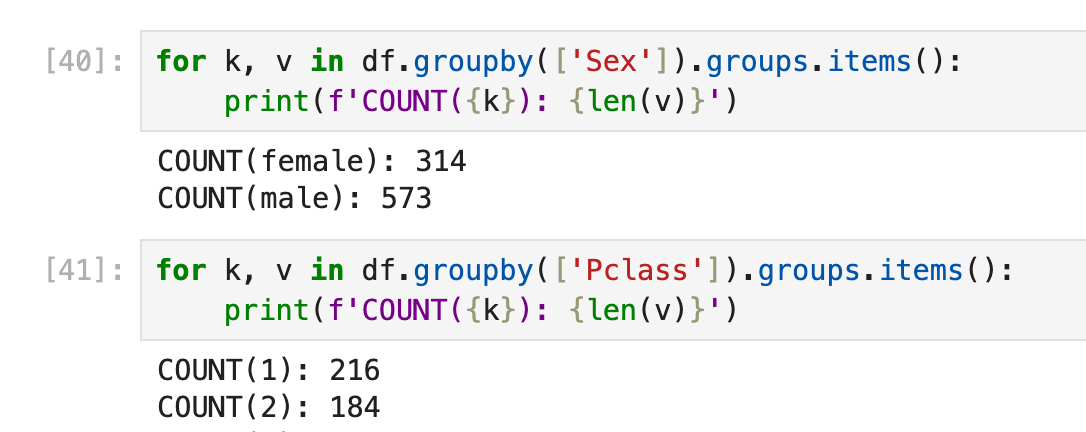
转换成list类型也可以:
[k for k in df.groupby(['Sex']).groups.keys()]
groupby里面可以填入不止一个column name:
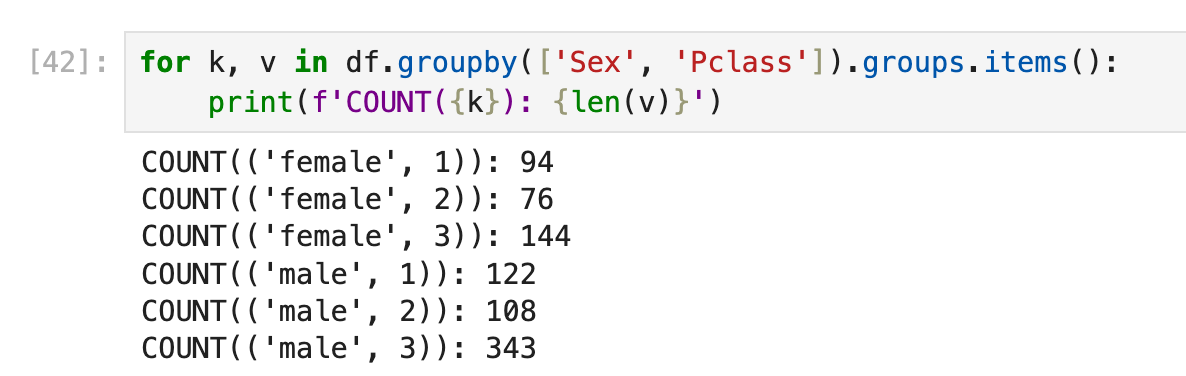
group by
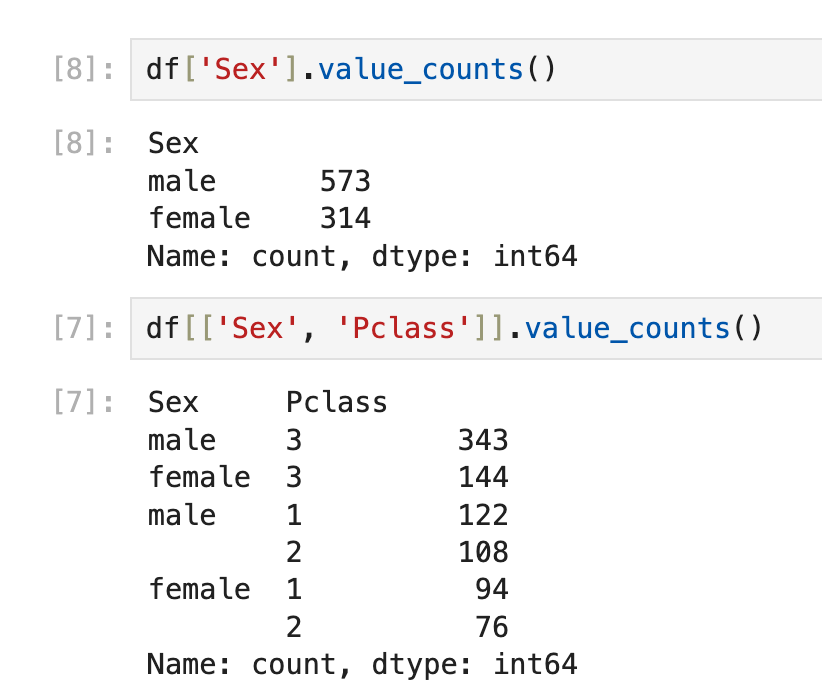
实际上在上一个目录里已经说了使用pandas groupby,如果只是想跑程序的时候中途临时看看结果,也可以使用value_counts():
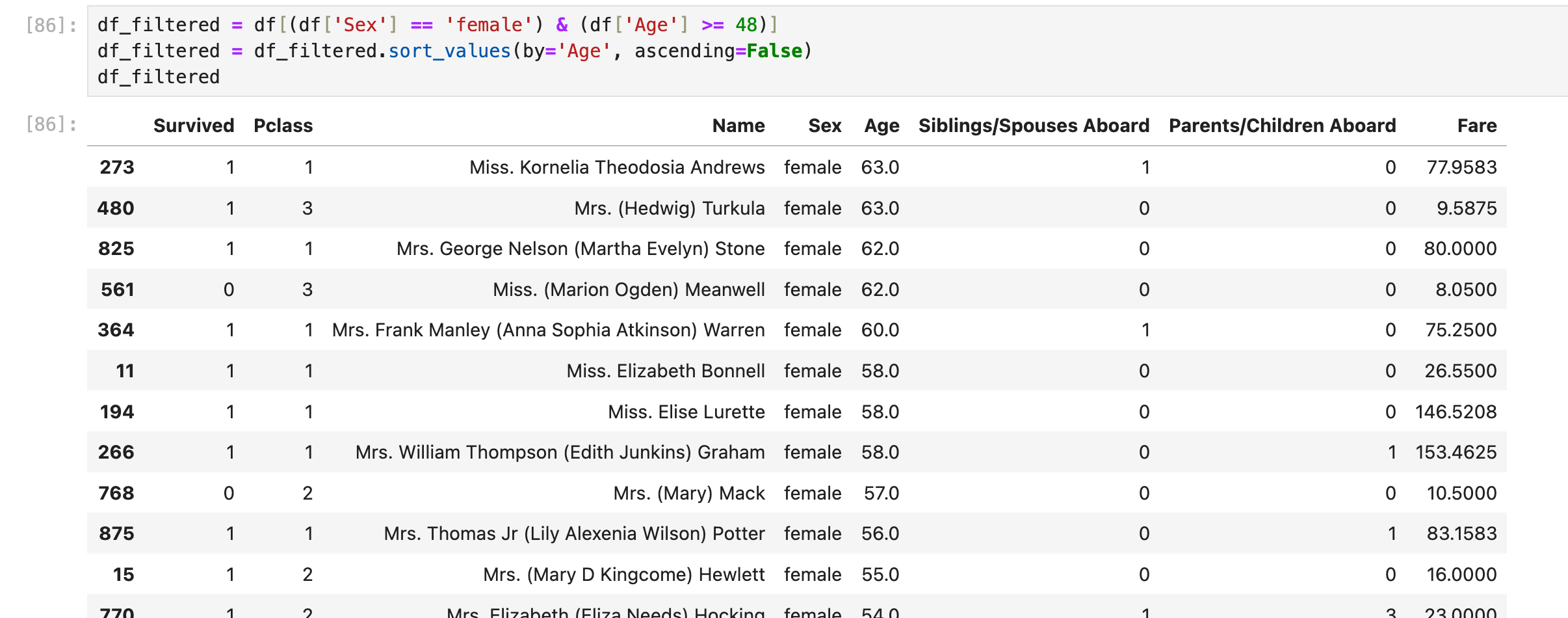
order by
select * from df_table where Sex='female' and Age>=48 order by Age DESC;分了2步骤,第一步和上面的一样,第二步排序需要用到sort_values()
假设我现在手里只有按照Age DESC排序好的df_filtered,我想重新把它按照row index排列:
使用sort_index()即可:
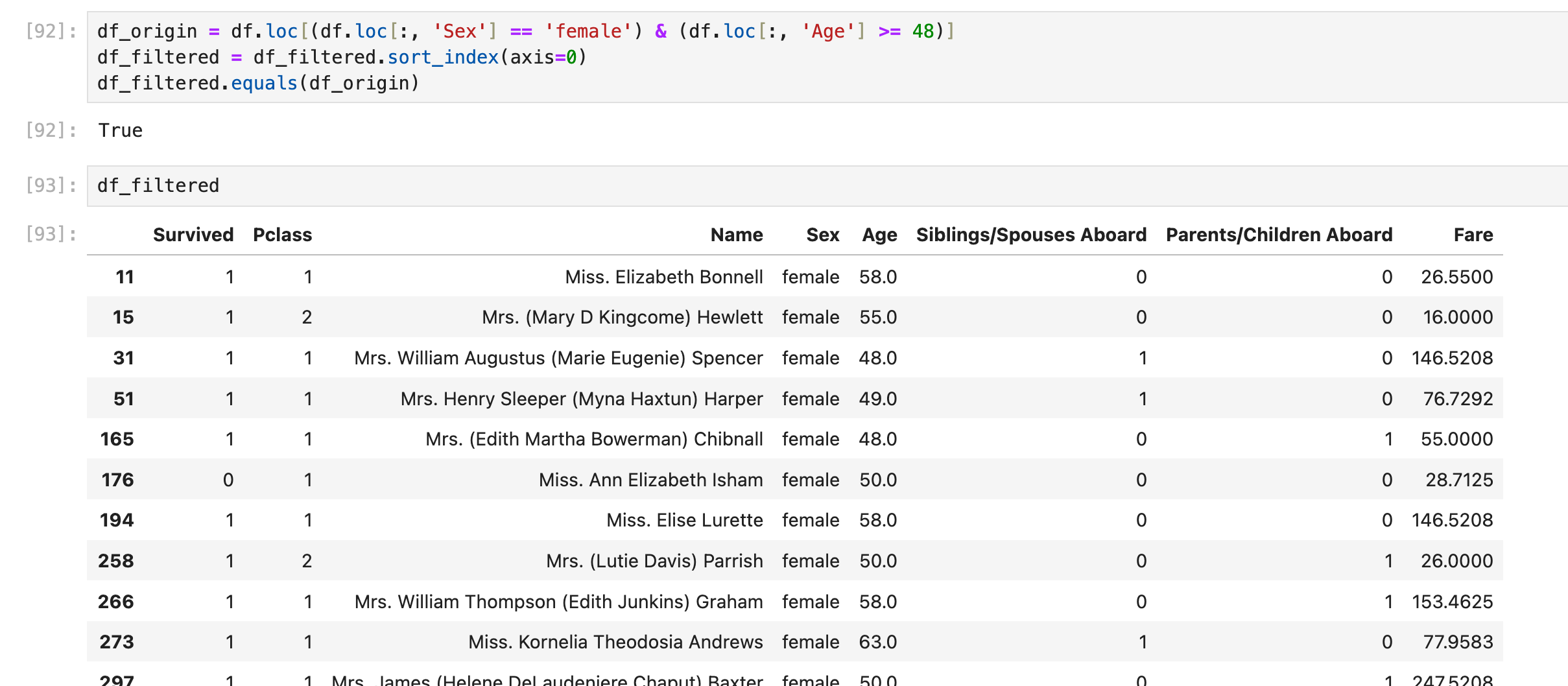
LIKE %xxx% 模糊查询(StringMethods)
select * from df_table where Name like '%James%';使用 .str 把Series数据转换为StringMethods,然后接常见的string判断方法:
如果是判断字符串全等:
df[df['Name'].str.lower().eq('james')]如果是判断字符串 不 包含/ 不 相等:
使用 ~ 逻辑符号:
df[~df['Name'].str.lower().eq('james')]LIKE %xxx% 模糊查询(apply lambda)
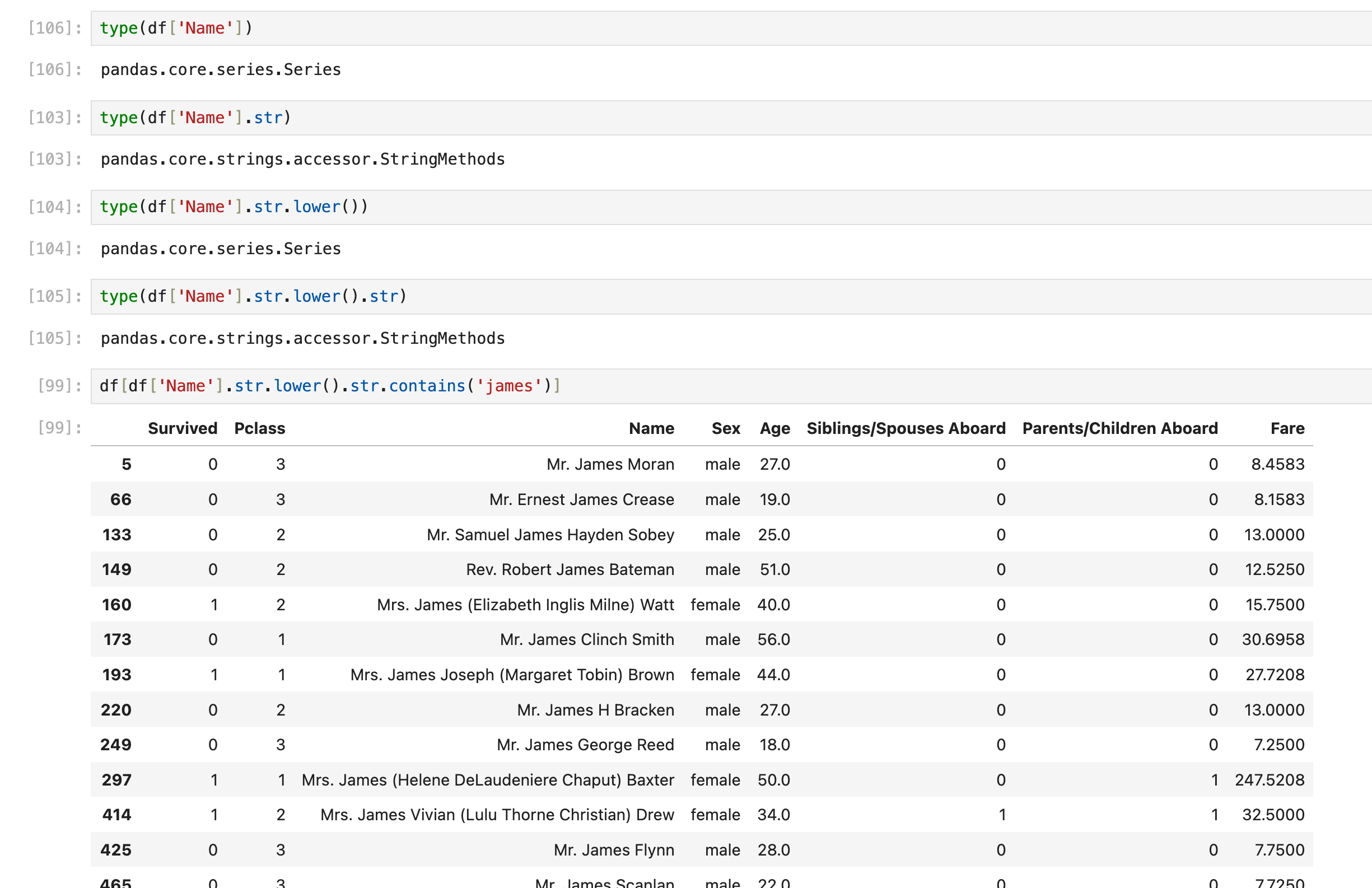
这里其实提前用到了apply lambda方法,但实际上这不是apply lambda最常见的使用场景。更常见的使用场景在后面(使用lambda批量处理行/列的元素)
lambda方法:对每一行的指定列元素进行筛选:
还是上面的sql
select * from df_table where Name like '%James%';这里用到了df.apply
axis=1看起来有点反直觉,目前只能强行记忆这个写法
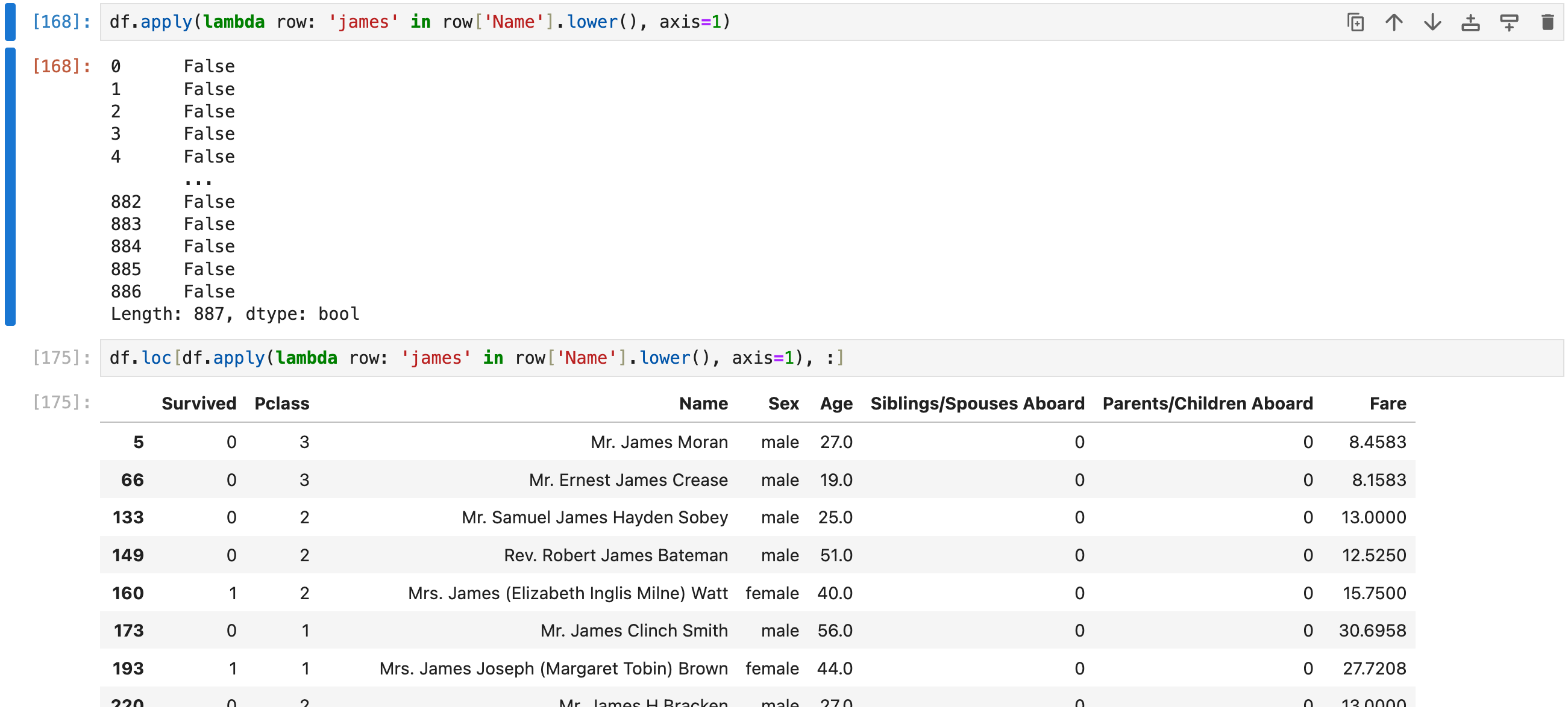
还能用lambda实现前面的多重where AND查询:
select * from df_table where Sex='female' and Age>=48 order by Age DESC;
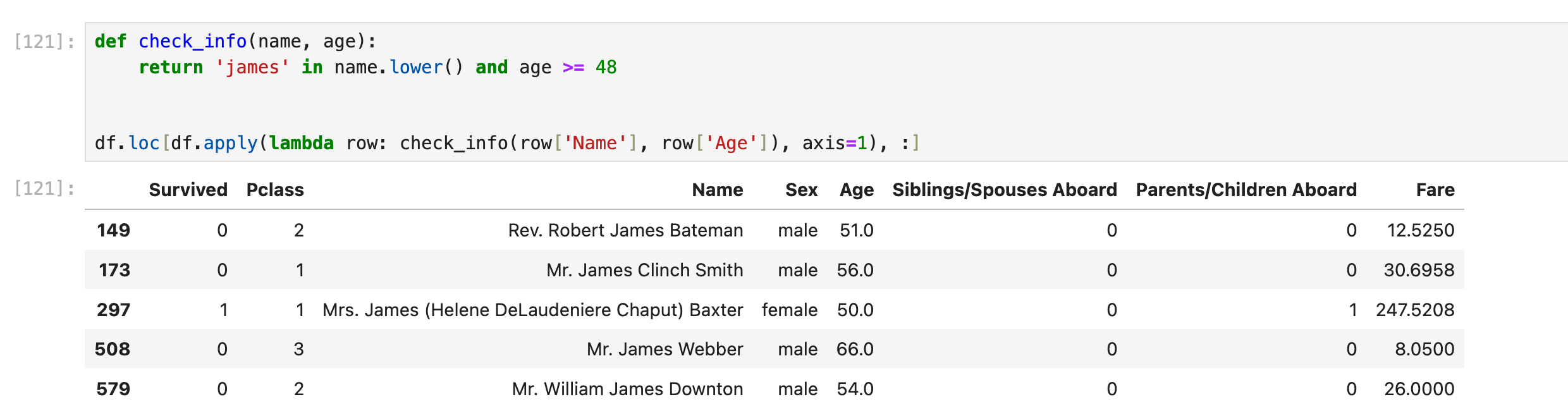
如果过滤的机制比较复杂,可以单独拿到一个function里面去写:
统计
统计某一列的平均/最大/最小
如果要用已经掌握的知识,可以用df->series->numpy array->np.average(), np.sum(), np.max(), np.min()等方法进行统计
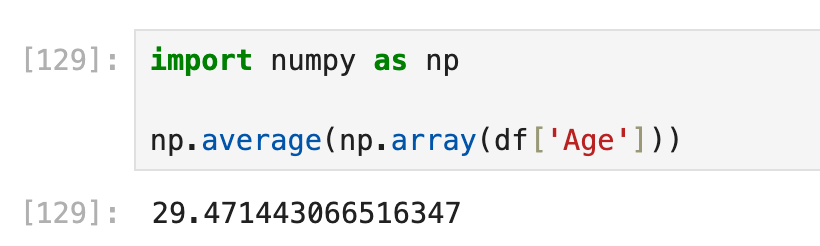
统计整张表的所有列各自的平均数
使用df.mean或np.average
统计整张表的所有列各自的平均数(前提是此列为数字列)
统计每行也可以,但绝大部分场景下并没有什么用
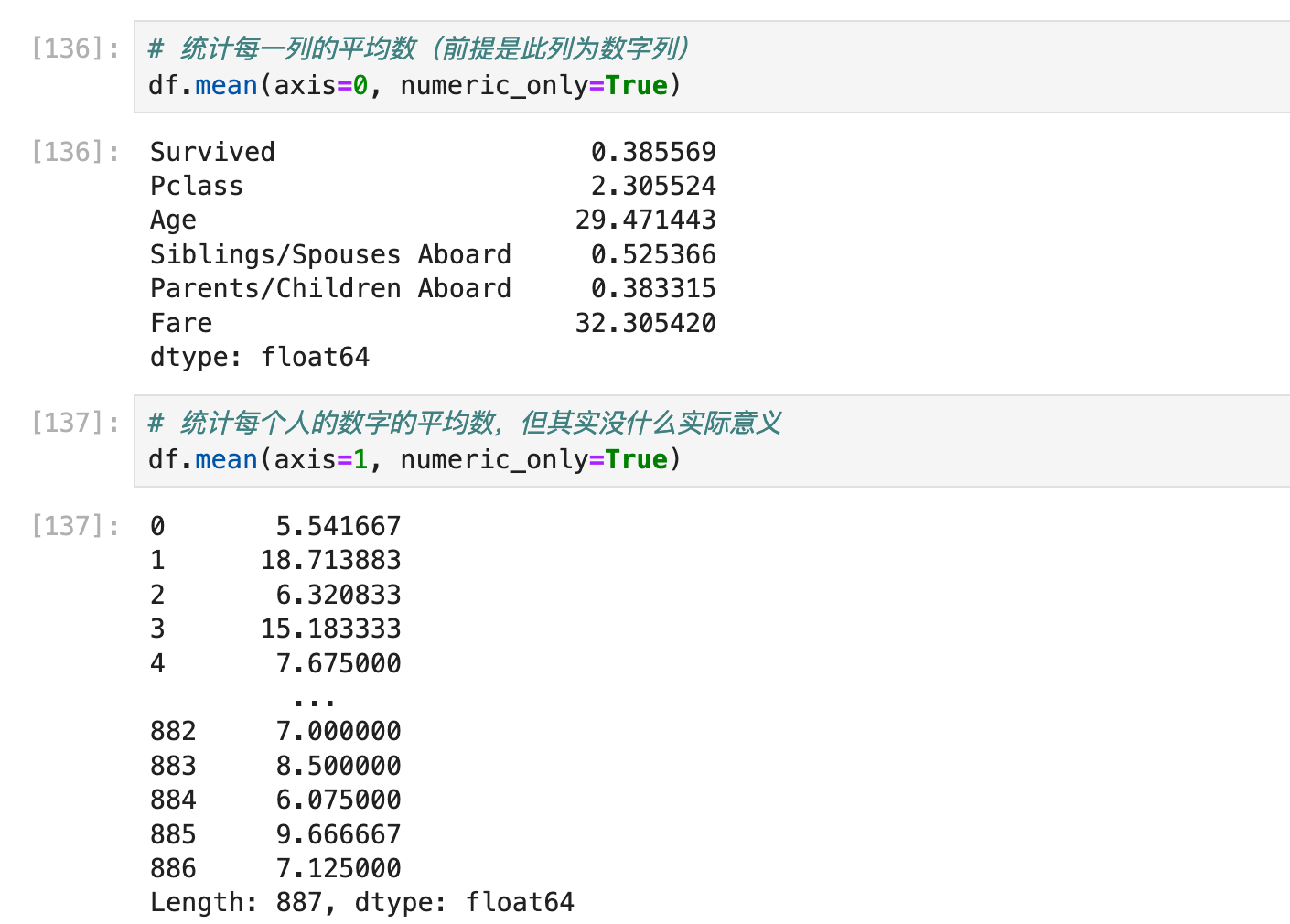
当然我们也想用自动化的方法把这些数字列都抽出来给numpy进行进一步的统计,而不是用df.mean():
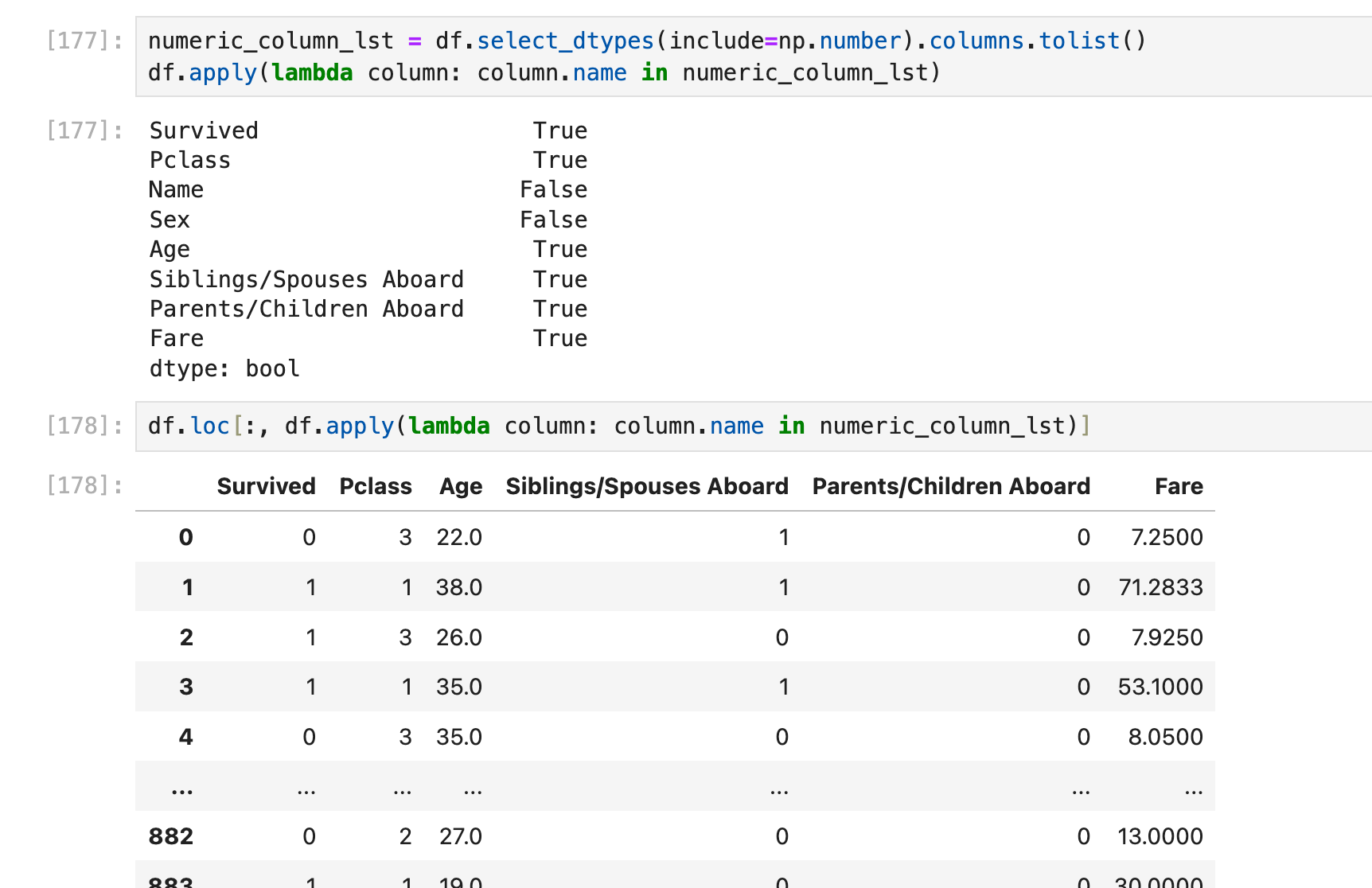
这里参考了🔗 [python - How do I find numeric columns in Pandas? - Stack Overflow] https://stackoverflow.com/questions/25039626/how-do-i-find-numeric-columns-in-pandas
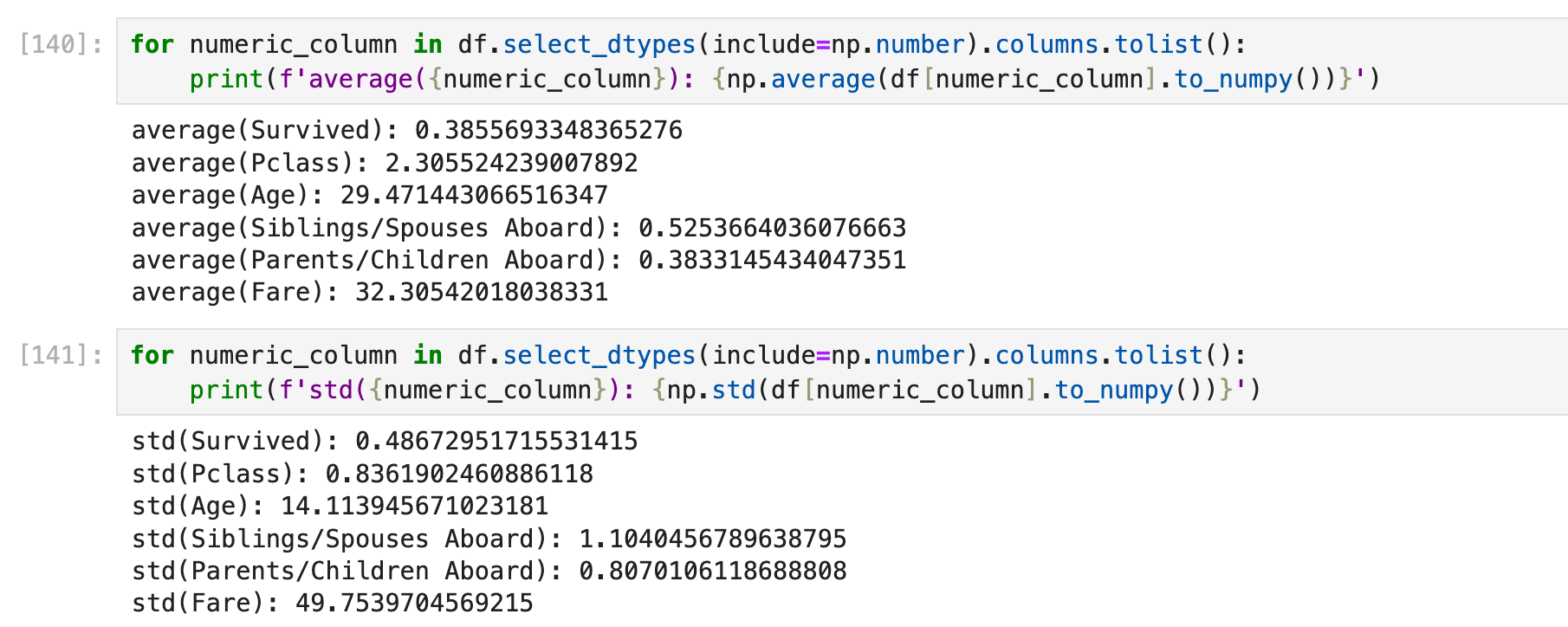
针对特殊类型
有的时候我们可能会读到这样的csv:
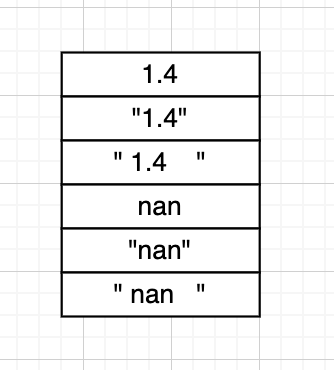
这种情况下df.mean会直接跳过这一列。目前看来唯一的解决方案是:写一个自定义函数,一个一个cell去读。
下面的代码仅仅是一个例子,并不怎么通用,因为有的时候还要判断更多东西,有的时候可能不需要这么复杂,总之遇到问题可以先debug,看看是什么奇怪的数值导致程序出问题了,然后根据这个特殊的数值单独加入特殊的判断代码。只要能跑出结果就行。实在不放心可以用一个正常的csv测试一下(看看这个函数处理正常的float64 column是否和df.mean结果一样):
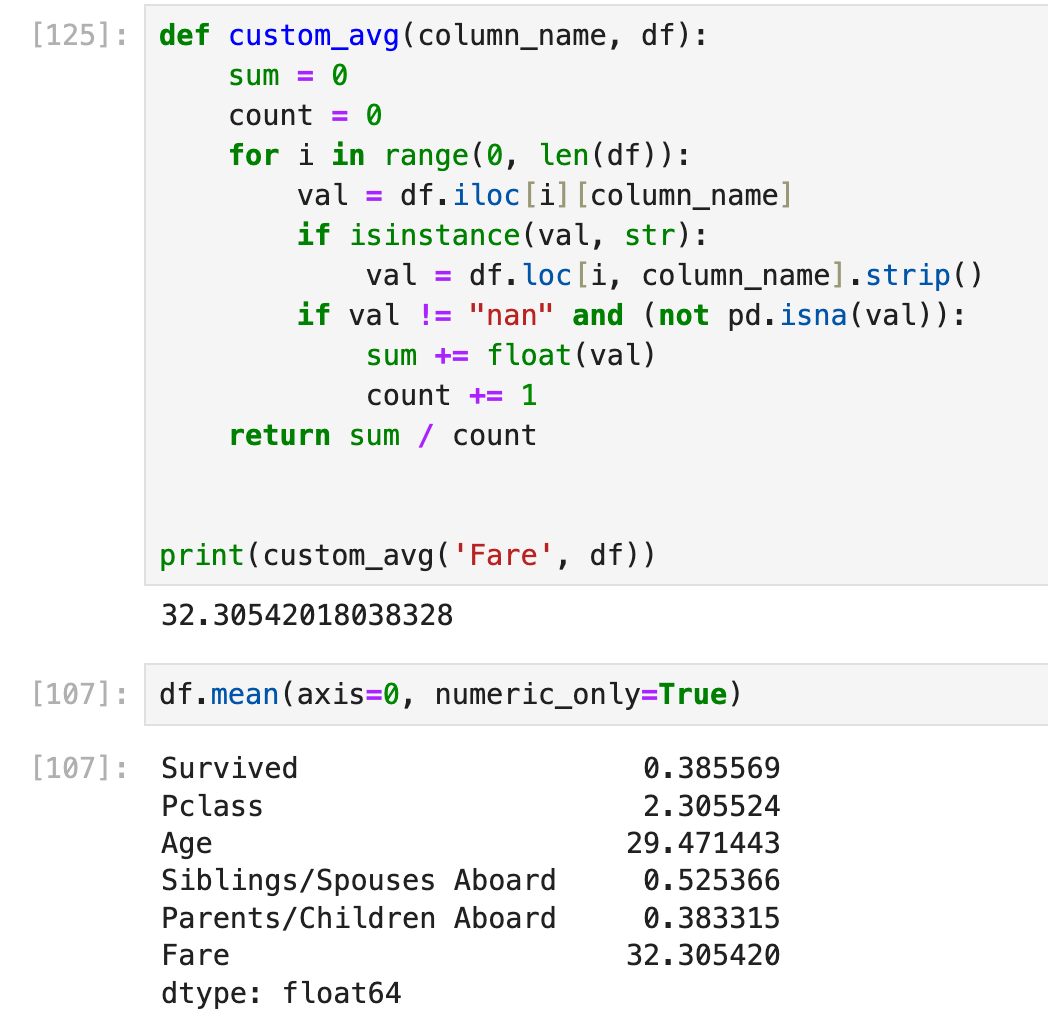
column dtype判断
介绍
在上面统计每列各自平均数的笔迹当中,为了找出所有的numeric columns而使用了df.select_dtypes()方法,这里还是有必要再补充一点对column dtype的判断方法
在本篇笔记稍早一些的地方(series转dict的那部分)学到了用dict(df.dtypes)存储每列的dtype:
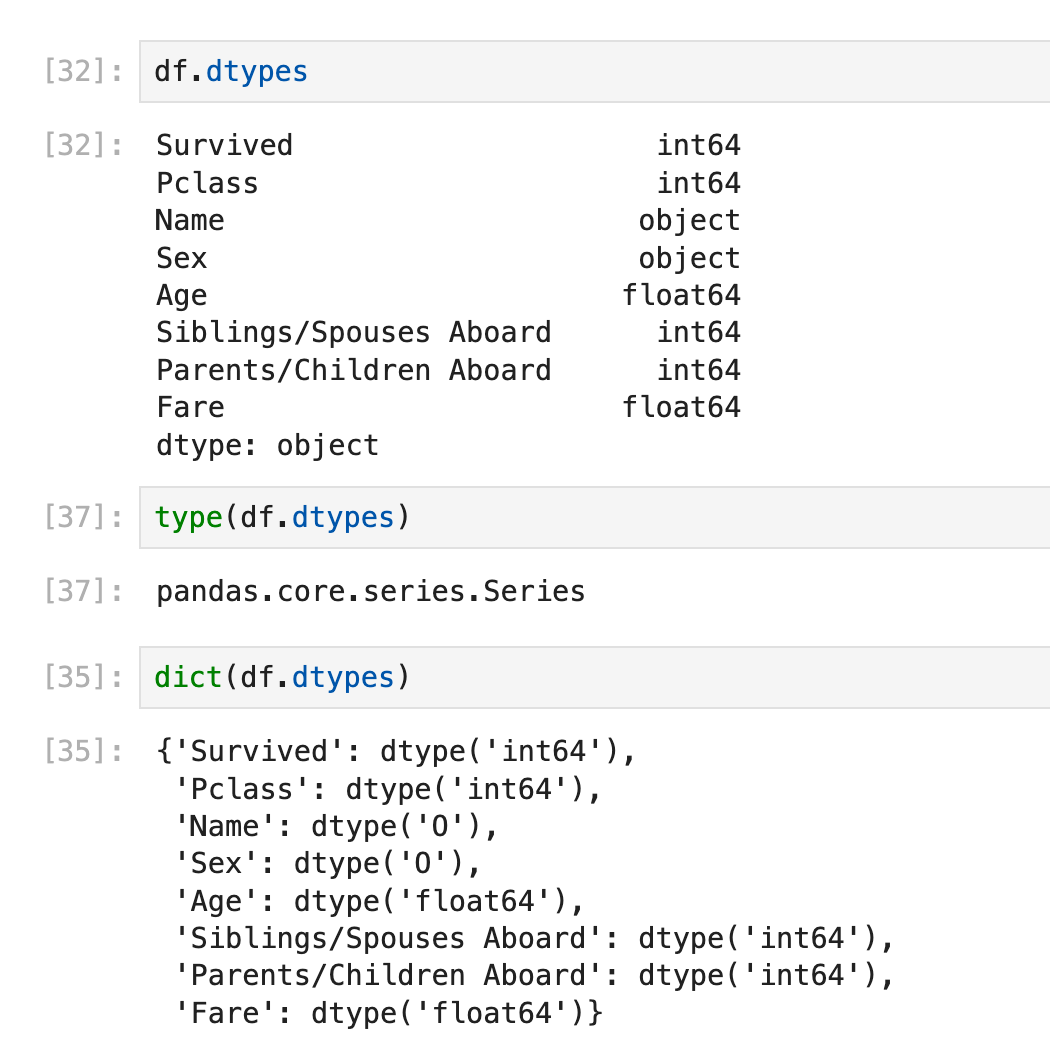
现在我们要对这个dict的key/value进行dtype判断:
方法1:pandas.api.types
方法1:使用pandas.api.types.is_xxxx进行判断:🔗 [pandas.api.types.is_object_dtype — pandas 2.2.2 documentation] https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.api.types.is_object_dtype.html
优点:对大部分场景都省事省力(比如is_string_dtype会帮你检查这一列的objects是否全都是string类型):
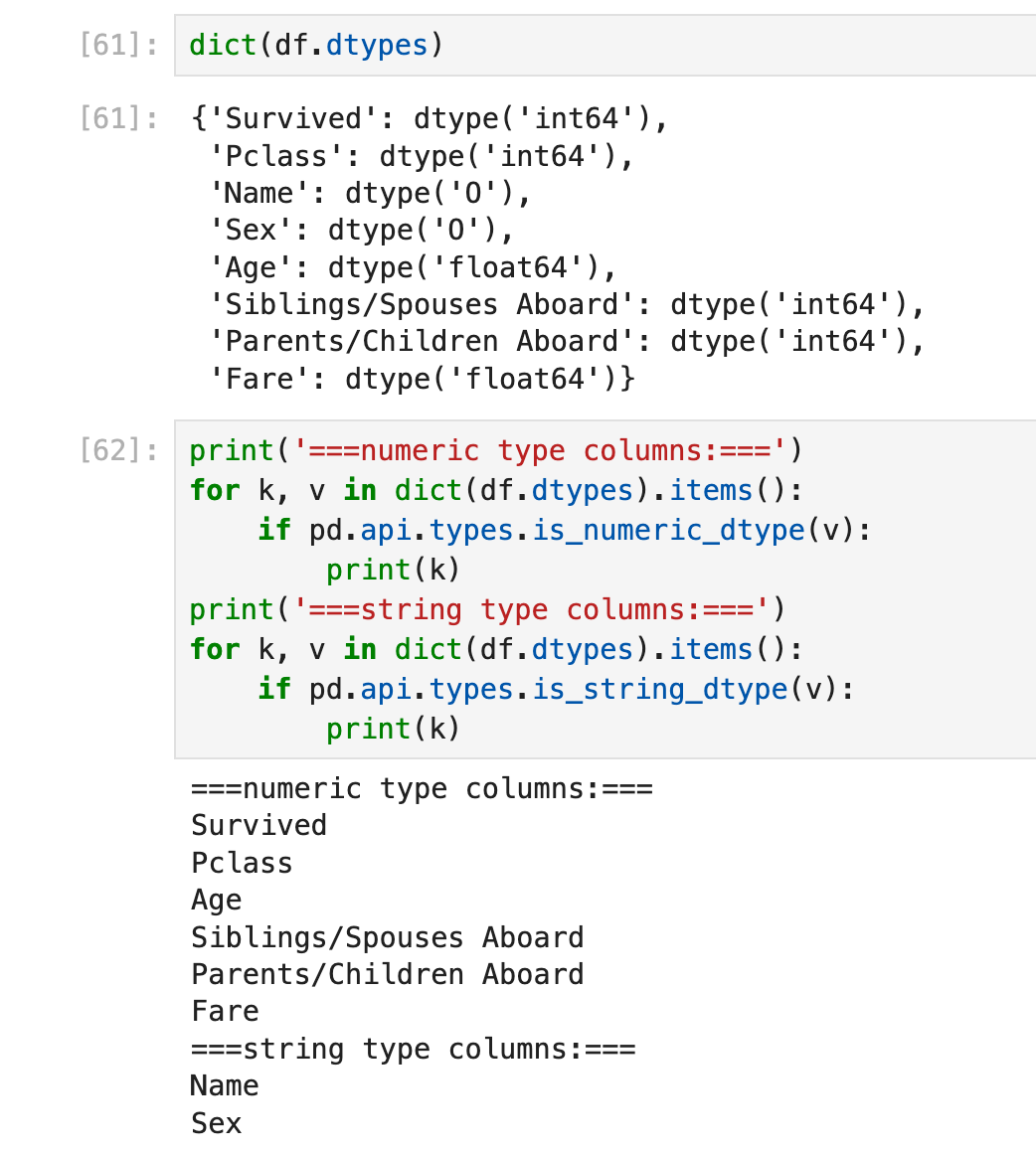
方法2:dtype==np.xxx
方法2:使用dtype==np.int64(等)进行判断,其中object(也就是dtype('0'))需要用np.object_进行判断:
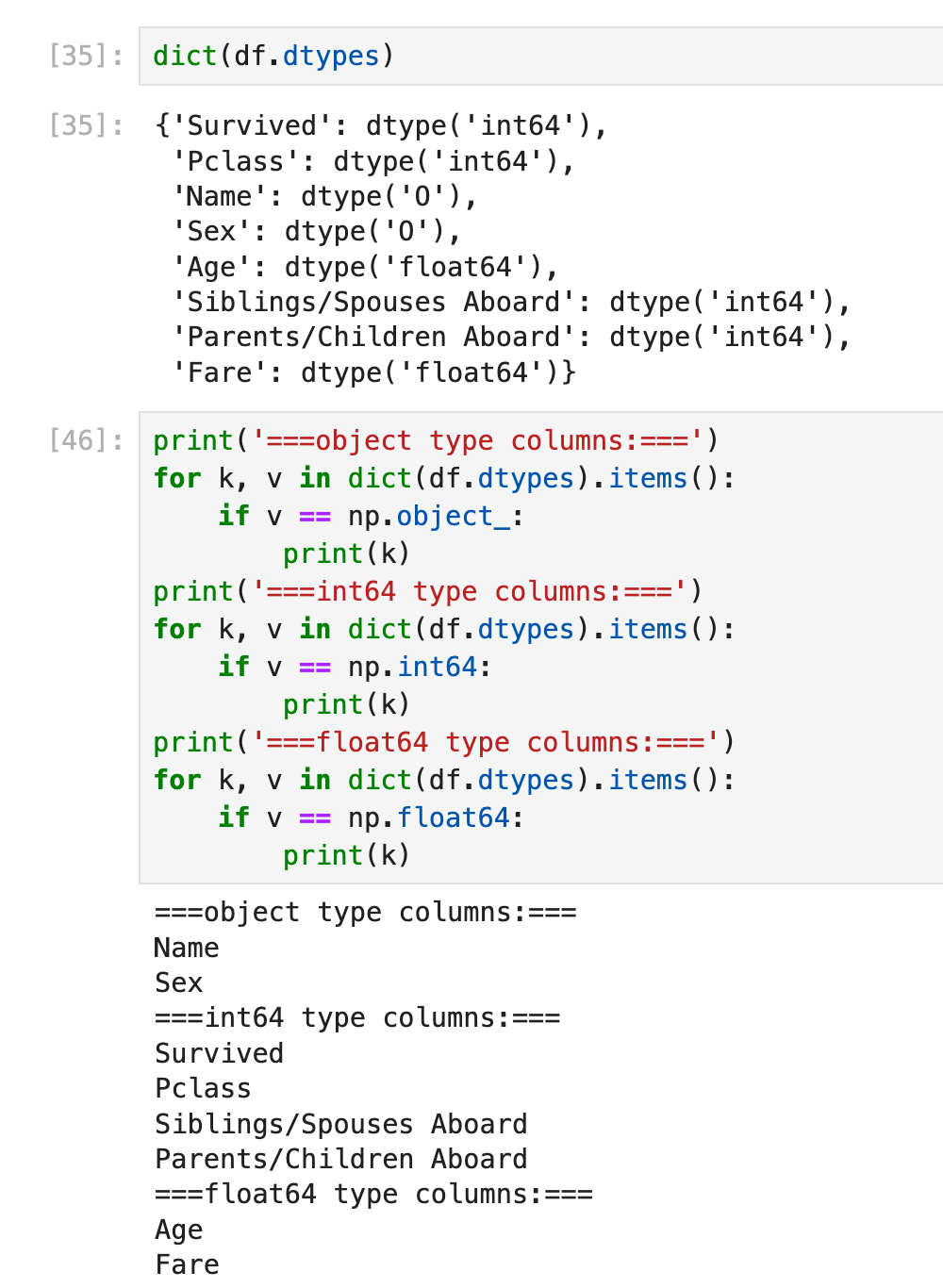
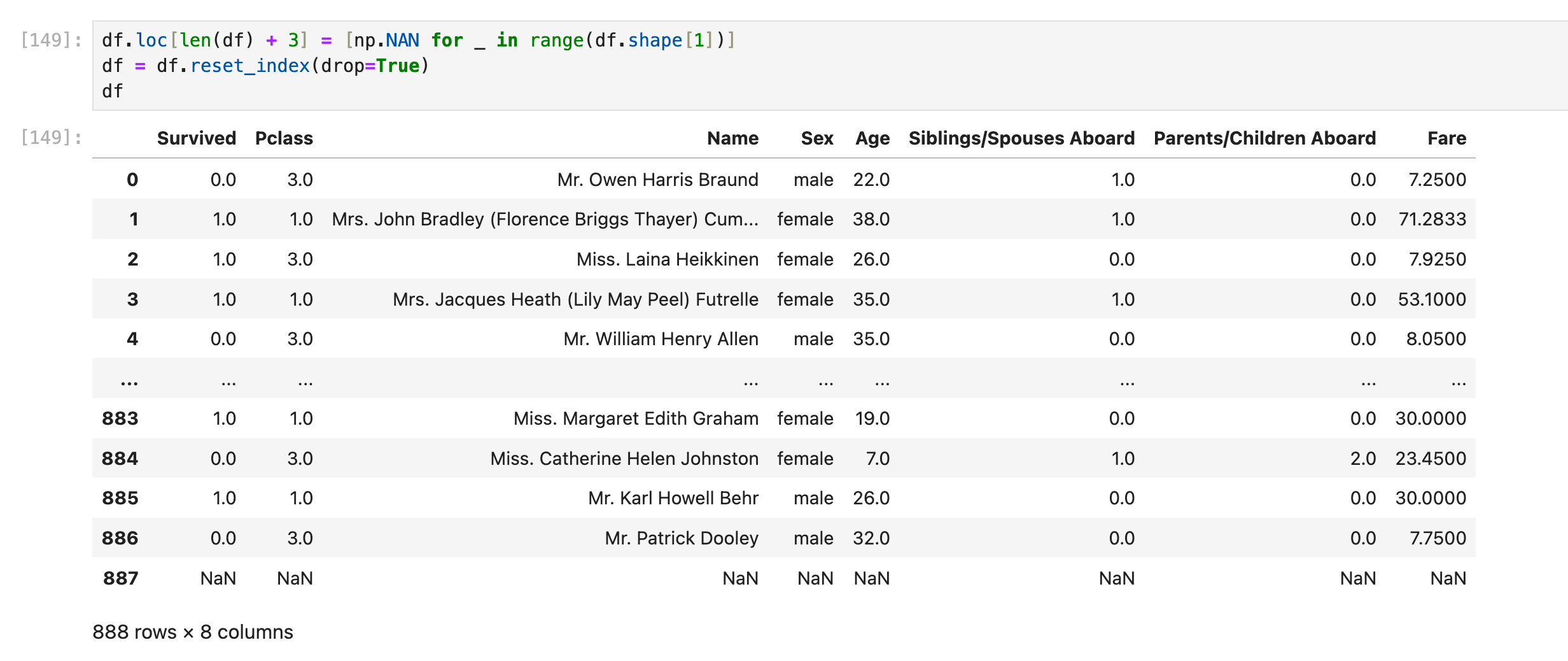
增加(空白的)一行/一列
新增一列(空列)
目前用这个就行:
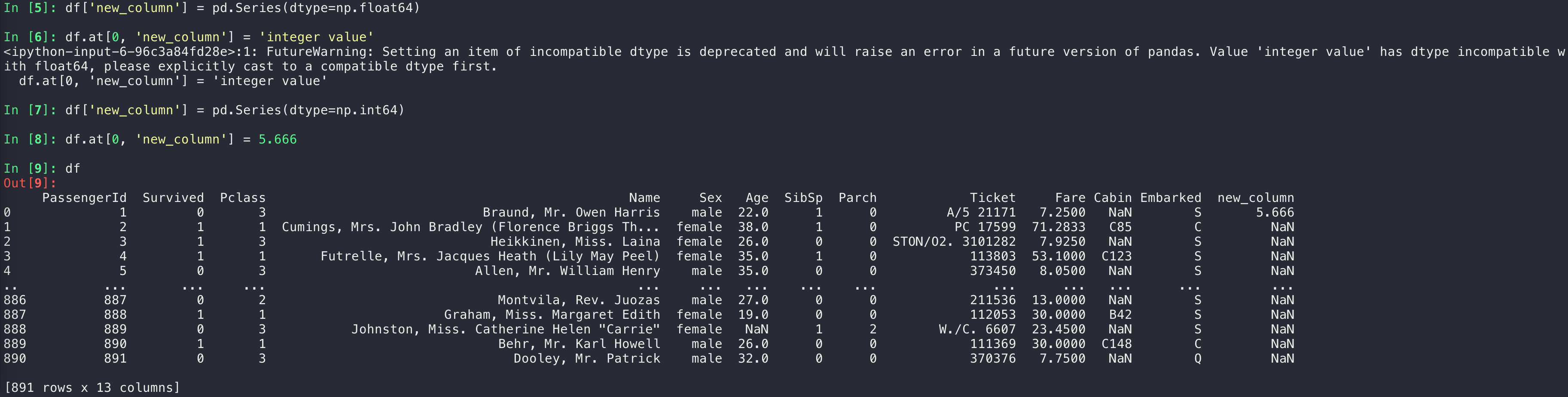
df['new_column'] = pd.Series() # 可以限制dtype,见稍后的内容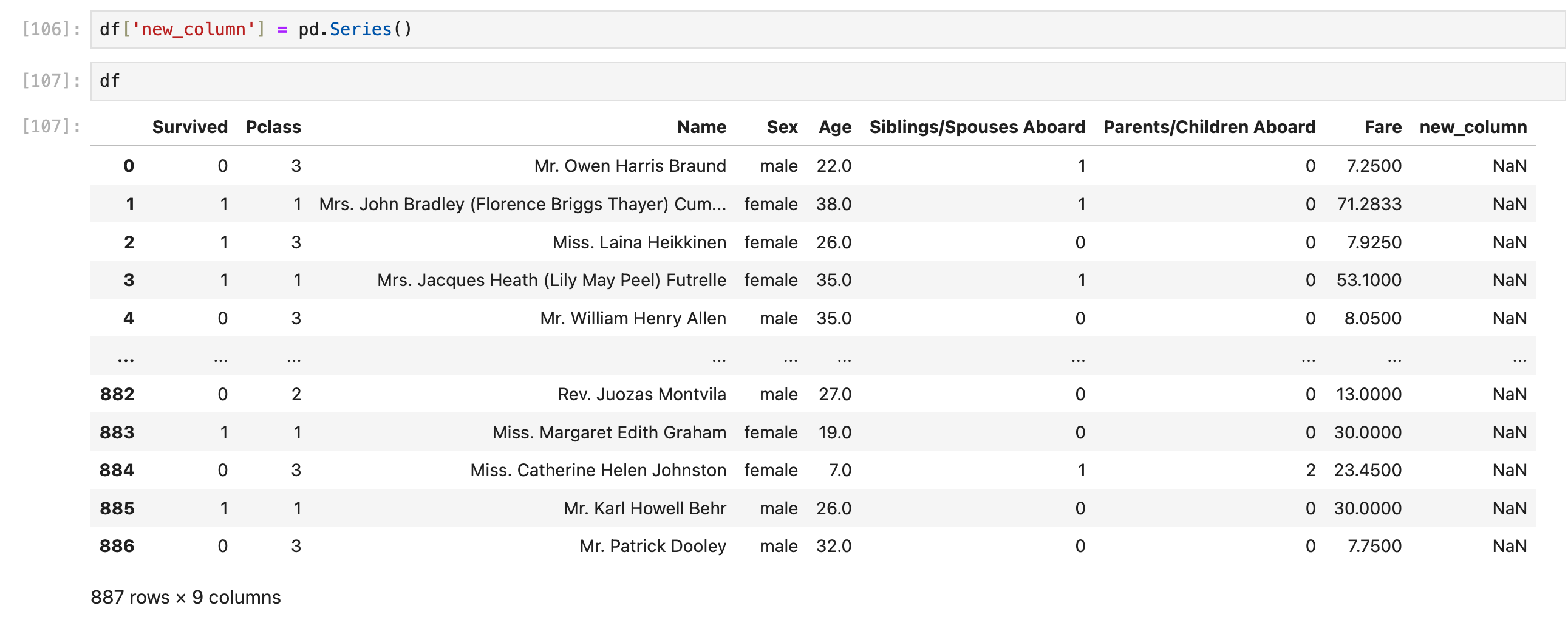
限制dtype有的时候有作用(比如声明了dtype=float64,然后往里面插string就会警告/以后会报错),有的时候没作用(声明了dtype=int64以后依然可以往里面插float数值,而且插入的float数值不会变成int)
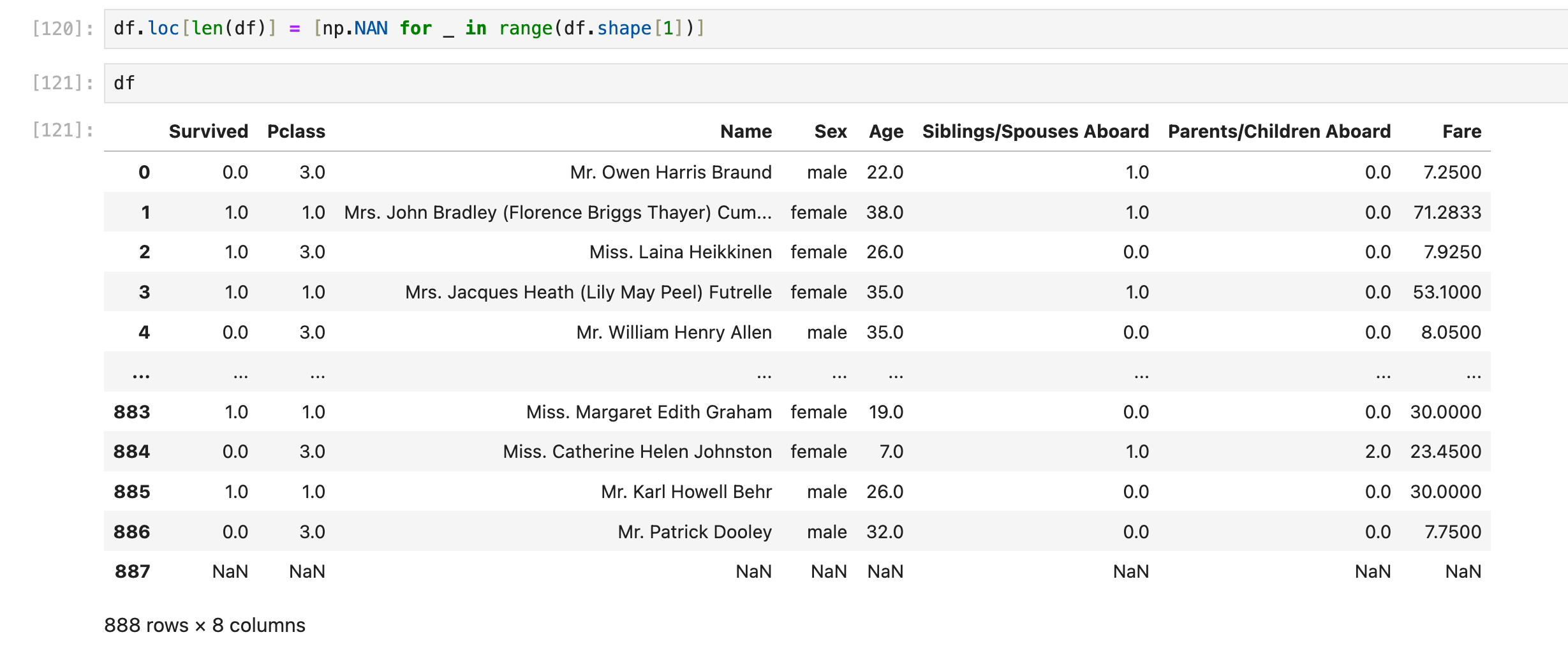
新增一行(空行)
这里只考虑简单情形:df的row index按照自然数0, 1, 2, ...排列,没有跳跃(比如从100跳到103)
另外:上面这种用df.loc的写法其实自由度比较大:
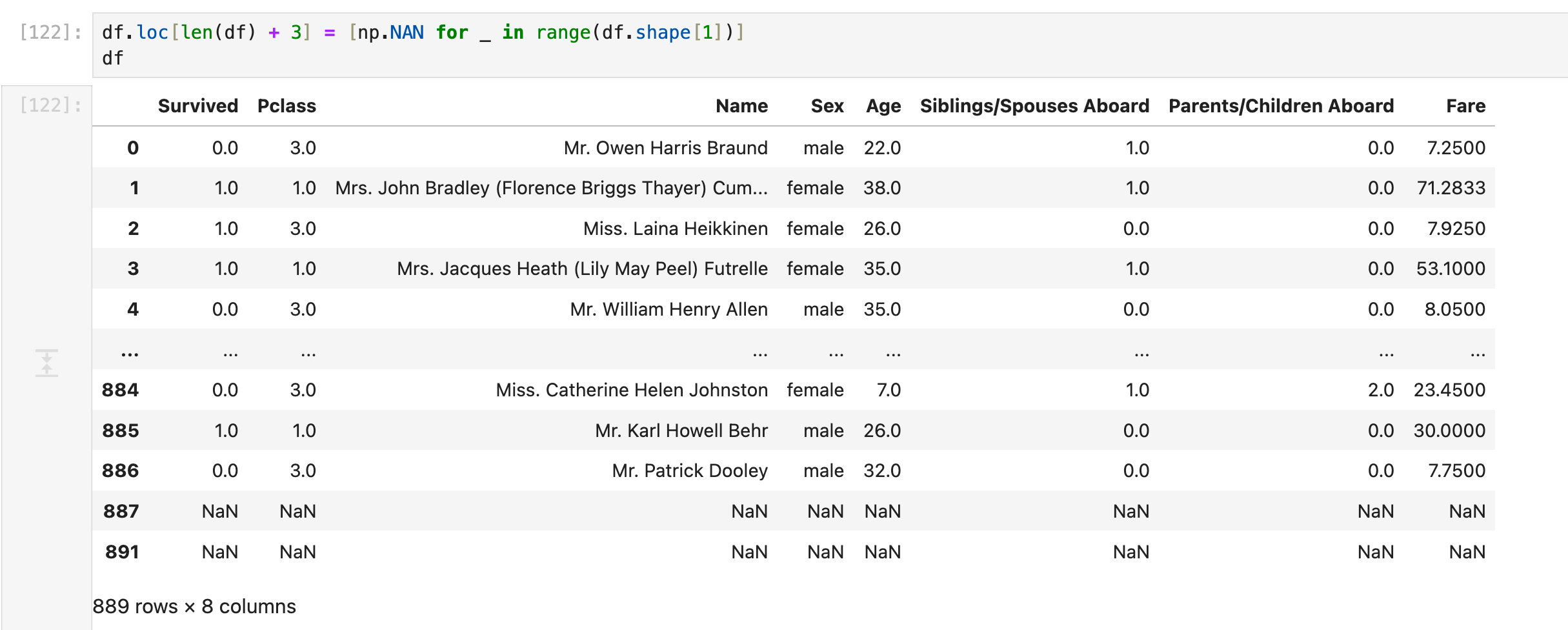
为了以防万一,可以在写这句话的前/后 重排row index:
删除行/删除列
删除行/删除列,本质上也是一种查询,因为df.drop()和df.filter()并不直接修改df
使用df.drop()
写在前面:df.drop()可以看成df.filter()的相反作用
需要注意的是,因为df.drop()并不修改df,而是返回另一个df,所以不需要事先deepcopy备份原本的df. df.filter()也是这样:
删除列,使用axis=1
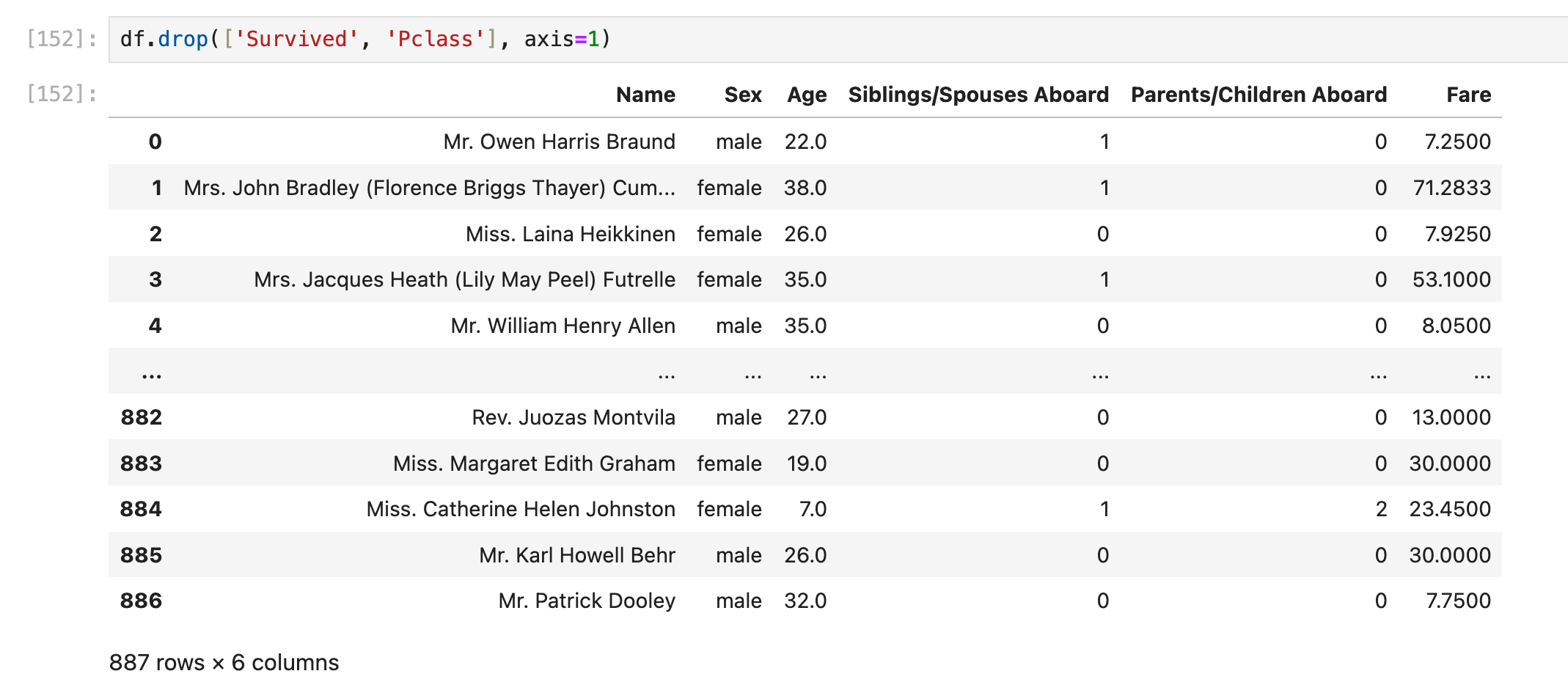
删除行,使用axis=0
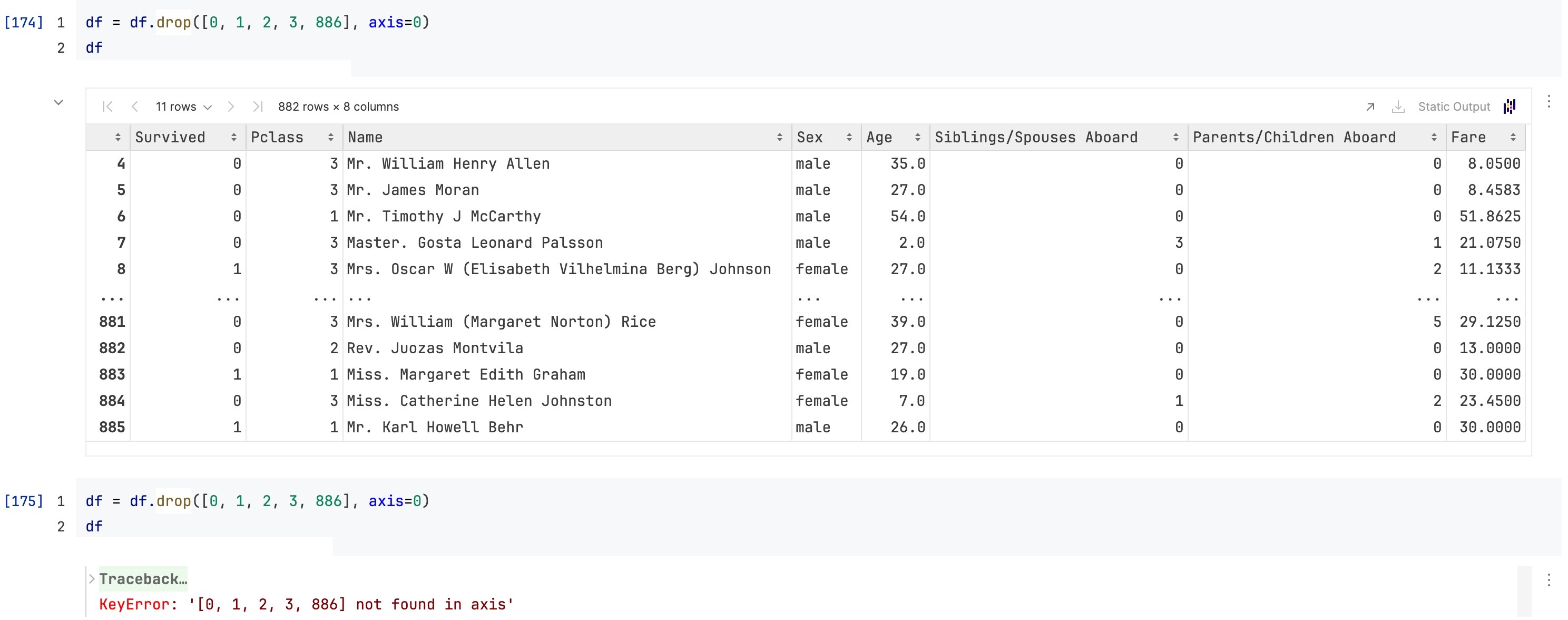
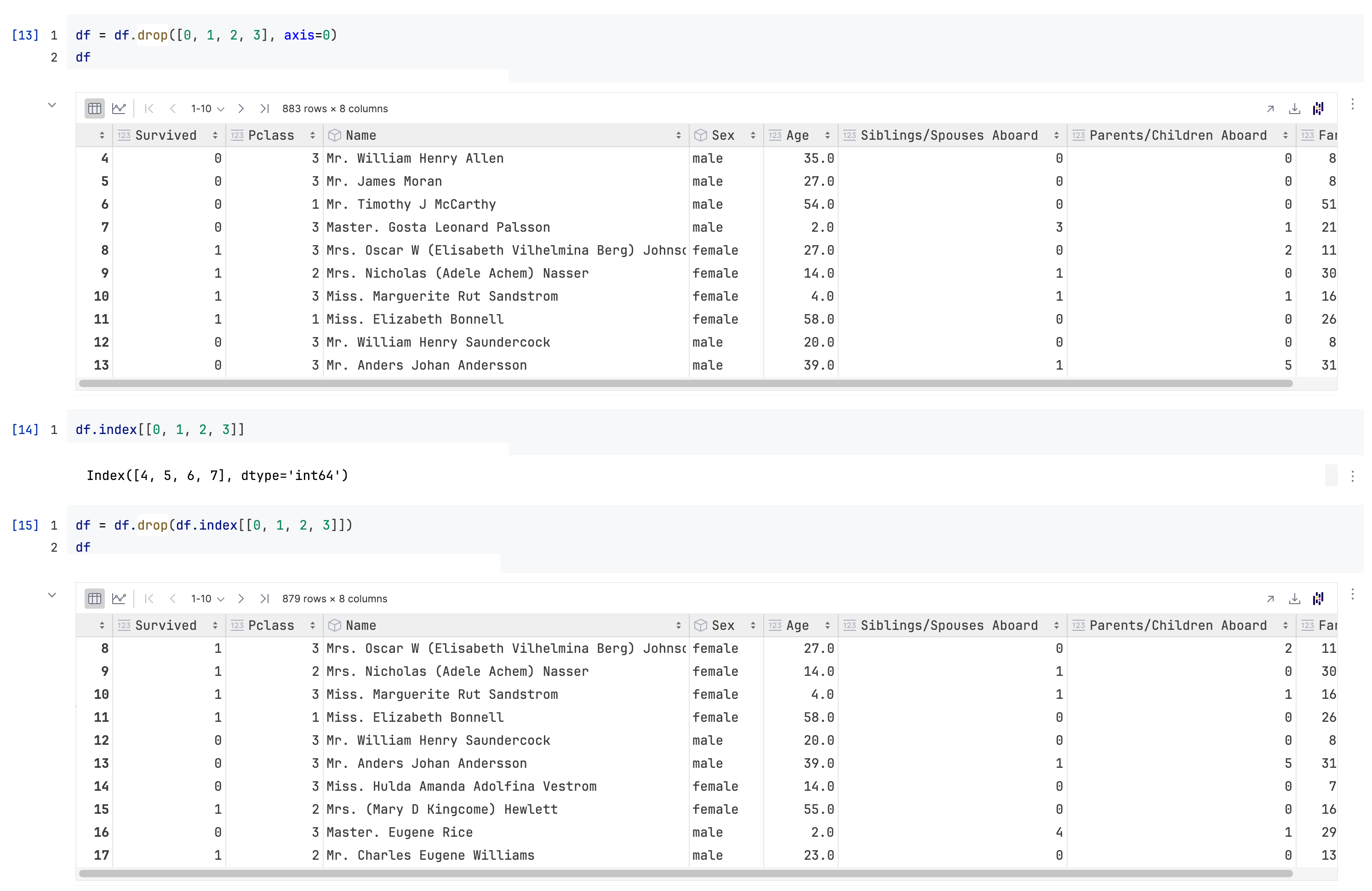
需要特别注意的是,
df.drop([0, 1, 2, 3, 886], axis=0)实际上去掉的是index为0, 1, 2, 3, 886的这几行,而不是physical index/iloc意义上的第0, 1, 2, 3, 886行(见本篇笔记的前面部分:row index)
所以第二次执行这句话的时候就会出问题(因为index为0, 1, 2, 886的这几行已经被删掉了)
那如果我就是想删掉“iloc意义上的第0行”,应该怎么做?
配合df.index:
使用df.drop()和df.filter()实现之前的一个要求:
把所有numeric columns抽出来单独组成一个dataframe;把所有non-numeric columns抽出来单独组成一个dataframe:
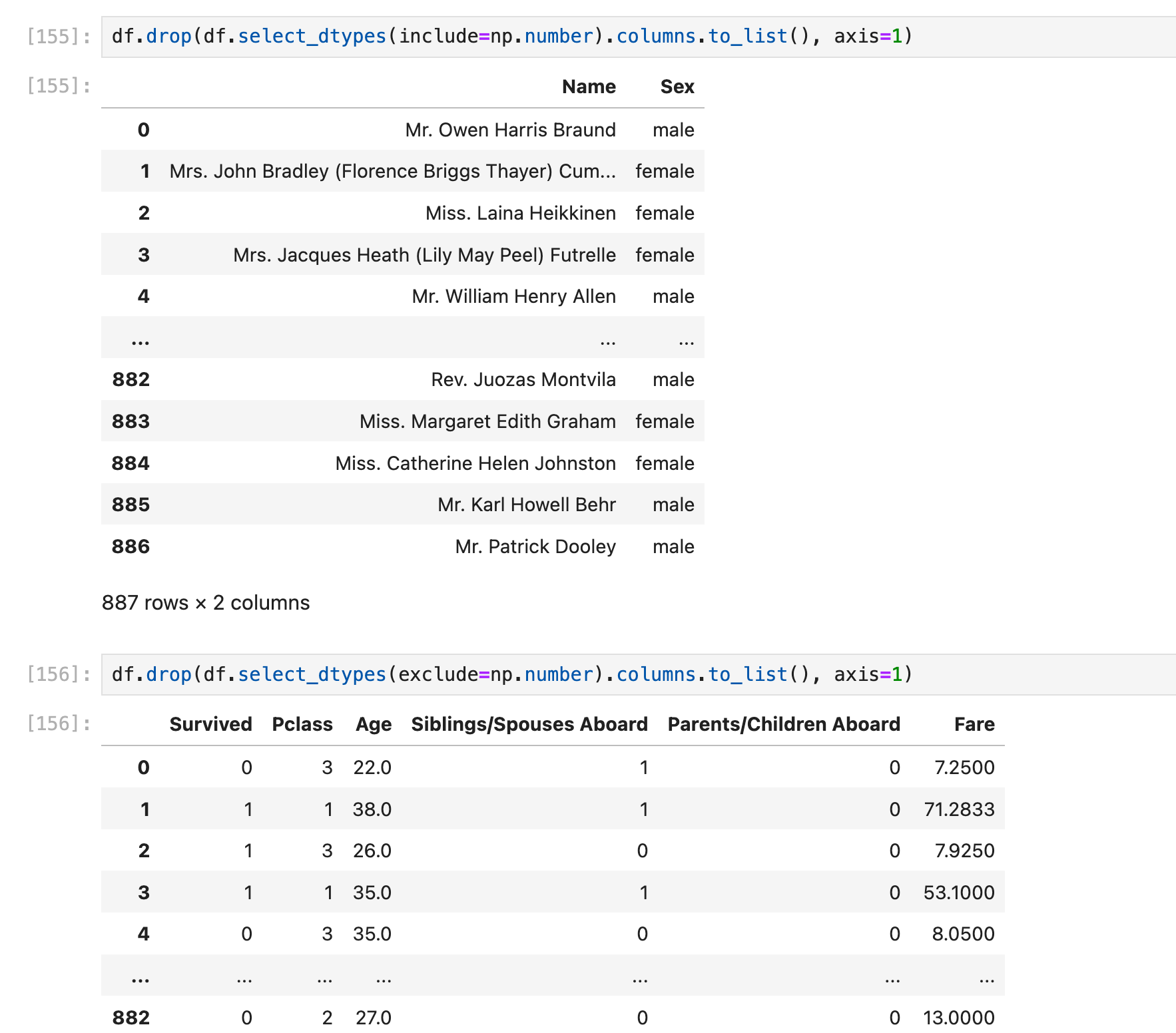
当然这个df.drop()在这里还可以使用df.filter()替换,结果刚好反过来:
df.apply(lambda)
对一整列的每个元素都进行操作
简单的操作不需要用到lambda
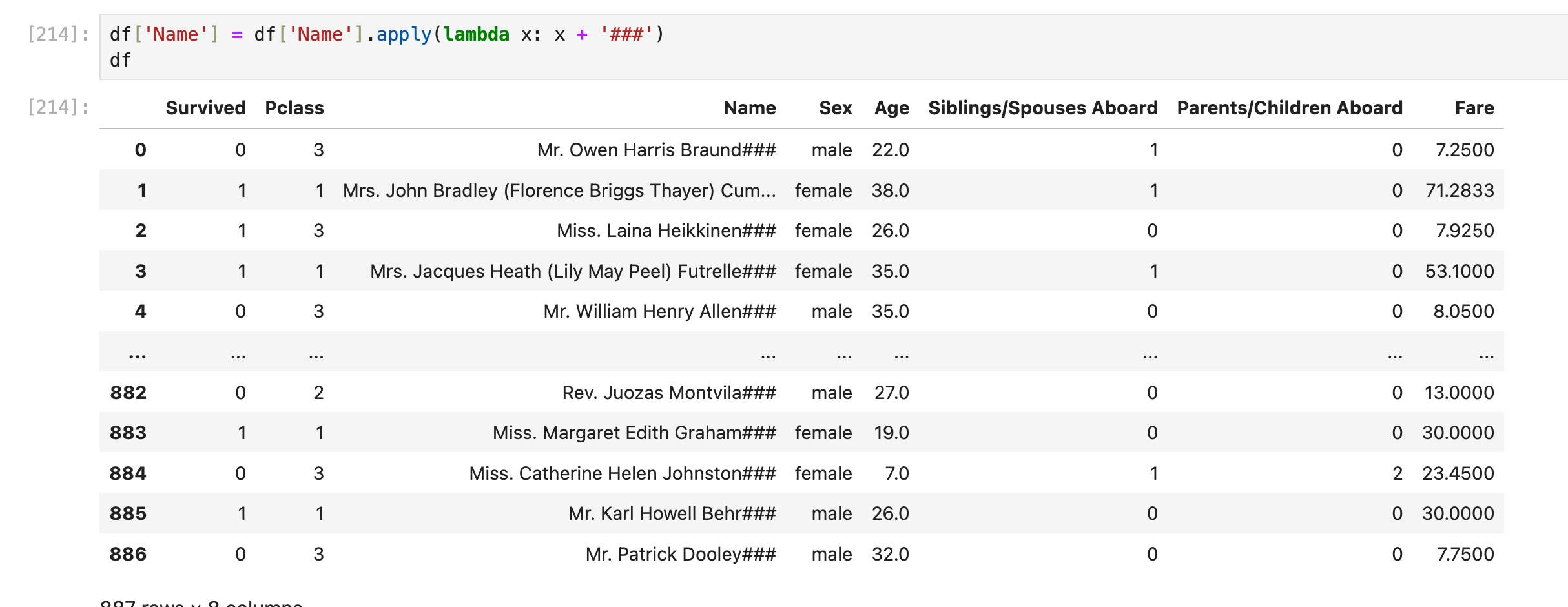
复杂点的操作可能就需要了:
对一整行的每个元素都进行操作(不常用)
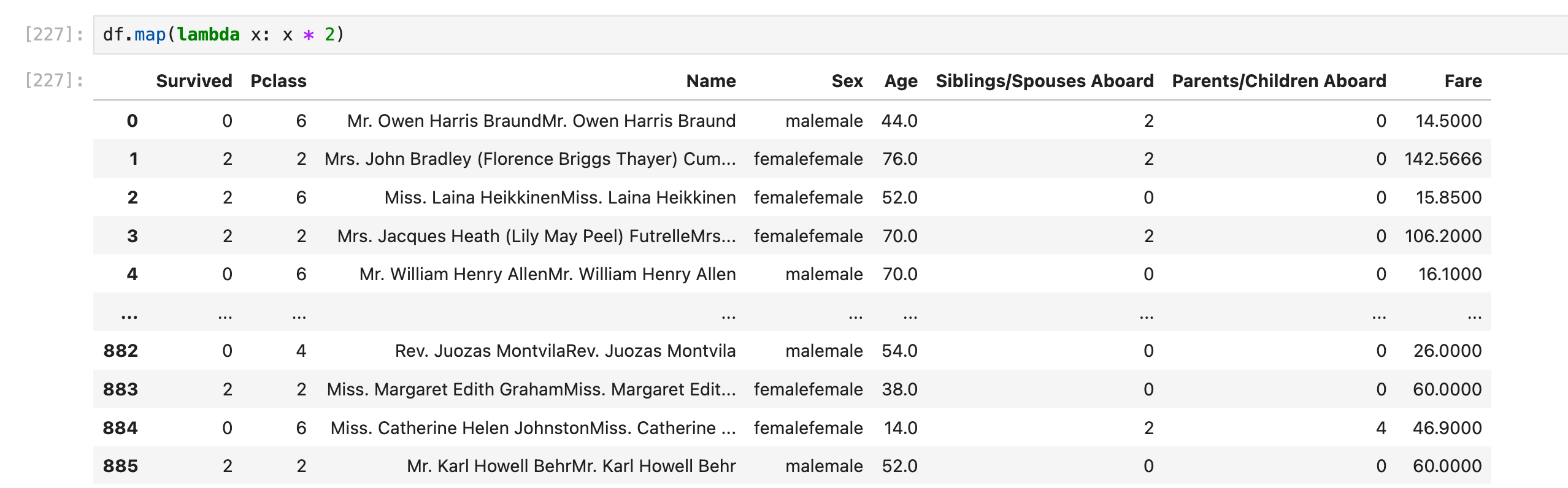
(这里仅仅为了演示lambda的用法,实际操作效果没有实际意义)对每一行row的所有元素x都执行x = x*2(如果是string就复制一份,比如"abc"变成"abcabc",如果是数字就乘以2,比如44变成88)
要用到2个lambda

或者还可以直接用df.map():
筛选特定的列(不常用)
似乎没啥意义,反正我看不出相比于df.loc它有什么独特价值