 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2022-01-26. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.Table of Contents
继续复习C语言
函数的声明
基本规则1:需要在main函数前定义,或者在main函数前声明
基本规则2:函数的定义和函数的声明需要保持一致
一个有趣的问题
注意这段代码:
#include<stdio.h>
void print1();
int main(int argc, char const *argv[]) {
print1(1.1);
return 0;
}
void print1(float a){
printf("print1");
}
当然这段代码是会报错的:

但是如果对第7, 11行进行修改:
#include<stdio.h>
void print1();
int main(int argc, char const *argv[]) {
print1(1); // 修改了这里
return 0;
}
void print1(int a){ // 修改了这里
printf("print1");
}
就不会报错,得到:
print1(暂时先鸽了),目前在网上查到的最类似的问答:🔗 [c - Why does gcc allow arguments to be passed to a function defined to be with no arguments? - Stack Overflow] https://stackoverflow.com/questions/12643202/why-does-gcc-allow-arguments-to-be-passed-to-a-function-defined-to-be-with-no-ar
目前对这个问题的了解进度:
1,如果函数的参数没有特别声明为 void ,那么确实可以在定义中给若干个参数;
(上面的程序只用了1个参数,但其实多个参数也是OK的),比如:
#include<stdio.h>
void print1();
int main(int argc, char const *argv[]) {
print1(1, 2);
return 0;
}
void print1(int a, int b, double c) {
printf("%d\n", a);
printf("%d", b);
}
结果:
1
22, void print1(float a) 为什么不行?因为调用这个函数的语句 print1(1.1); 传过去的实际上是double类型;
3,根据上一条,把 void print1(float a) 改为 void print1(double a) 是OK的;
4,但我还是想写 void print1(float a) ,能不能调用这个函数的时候使用 print1(1.1f) 或者 print1((float)1.1) ?是不可以的,它们最后还是会被强制转换为double类型,导致变量类型冲突。
当然,这样做真的没有什么实际意义,所有的功课都是在给C语言编译器的老旧兼容模式让路:🔗 [C function float argument takes different value inside the function - Stack Overflow] https://stackoverflow.com/questions/36833308/c-function-float-argument-takes-different-value-inside-the-function
指针、取地址、解引用、引用
引用符号:Reference operator & ,但并不是所有场景下都被视为reference operator .
解引用符号:de-reference operator * ,但并不是所有场景下都被视为de-reference operator .
关于int* p和int *p的写法:🔗 [C/C++ 里指针声明为什么通常不写成 int* ptr 而通常写成 int *ptr ? - 知乎] https://www.zhihu.com/question/52305847?rf=21136956

同时要注意:

如何正确理解
int v = 10;
int *p = &v;p 是指针;等号右边 &v 代表地址;
在 int *p = &v 的声明中, * 不代表de-reference operator ,仅仅代表指针的声明。所以 不能 用这样的方法去推断:"p代表指针,那么*p代表数值,但等号左边是数值等号右边是地址,不对怎么混乱了...".
所以还是 int* p = &v 这样的写法更容易懂一点。
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 10, v2 = 100;
int *p = &v;
// 另一种理解:
// int* p = &v;
// p是一个指针,指向int v=10所在的地址; [*]是dereference operator,所以[*p]取得了[指针p所指向的地址的数值]
printf("value of v is %d\n", *p);
// value of v is 10
printf("pointer p(指向v)指向的地址: %p\n\n", p);
// pointer p(指向v)指向的地址: 0x7ffd51383c34
// 把指针p指向的地址修改成了int v2=100的地址
p = &v2;
printf("value of v2 is %d\n", *p);
// value of v2 is 100
printf("pointer p(指向v2)指向的地址: %p\n\n", p);
// pointer p(指向v2)指向的地址: 0x7ffd51383c30
// 把指针p指向的地址(当前指向了int v2=100)里面的数值修改成了1000
*p = 1000;
printf("value of new p is %d\n", *p);
// value of new p is 1000
printf("pointer p(指向v2)指向的地址: %p\n", p);
// pointer p(指向v2)指向的地址: 0x7ffd51383c30
printf("value of v2 NOW is:%d\n", v2);
// value of v2 NOW is:1000
printf("value of v2,另一种写法:%d", *&v2);
// value of v2,另一种写法:1000
return 0;
}value of v is 10
pointer p(指向v)指向的地址: 0x7ffd51383c34
value of v2 is 100
pointer p(指向v2)指向的地址: 0x7ffd51383c30
value of new p is 1000
pointer p(指向v2)指向的地址: 0x7ffd51383c30
value of v2 NOW is:1000
value of v2,另一种写法:1000注意到第13行, *p = 1000; 这句话并没有改变指针p指向的地址。长时间写python导致我很容易搞错这一点。另外注意第16行输出的结果:p指向了v2的地址,改变了这个地址下的数值,所以变量v2的数值也会改变。
指针地址的救捞
我们都会写 int *p = & v 这样的语句,那么如果写成 int p = &v 呢?
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 10;
int p = &v; // 危险!
printf("%d\n", p);
// -762018736
return 0;
}可以看到,这段程序还是可以运行的,编译器也不会罢工。那么我们继续危险一步:
我们能不能从 int p 这个变量里捞出正确的指针呢?
使用int是不行的,下面的程序直接异常退出了,说明我们无法从int类型的变量里救捞出正确的指针地址:
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 10;
int reverse = &v;
int *save_me = (int *) reverse; // 这一步捞出了一个错误的地址
printf("save me: %d\n", *save_me);
return 0;
}
// segmentation fault ./a.out但我们仍不死心,还记得sizeof(指针)=8吗?可能是因为sizeof(int)=4不够用,我们也许可以试试sizeof(long)=8!
首先我们熟悉一下(64位环境)int, long 和 int指针 所占用的空间大小:
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 10;
long l = 10;
int *p = &v;
printf("size of int: %lu\n", sizeof(v));
// size of int: 4
printf("size of pointer: %lu\n", sizeof(p));
// size of pointer: 8
printf("size of long: %lu\n", sizeof(l));
// size of long: 8
return 0;
}然后我们尝试用long类型去救捞指针地址:
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 999;
long reverse = &v;
int *save_me = (int *) reverse;
printf("save me: %d\n", *save_me);
// 999
return 0;
}野鸡方法到此为止,接下来是官方推荐的做法:使用 uintptr_t :
#include<stdio.h>
int main(int argc, char const *argv[]) {
int v = 999;
uintptr_t reverse = (uintptr_t) &v;
int *save_me = (int *) reverse;
printf("save me: %d\n", *save_me);
// 999
return 0;
}事实上, uintptr_t 这个东西就是 unsigned long . 头文件
社区对这个话题的其他讨论:🔗 [c++ - converting int to pointer - Stack Overflow] https://stackoverflow.com/questions/9212219/converting-int-to-pointer
参数传递
一个最简单的例子:
#include<stdio.h>
void helper(int *p) {
printf("p是指针,指向了%d\n", *p);
// p是指针,指向了10
}
int main(int argc, char const *argv[]) {
int v = 10;
int *p = &v;
helper(p);
return 0;
}同样,使用 void helper(int* p) 这样的方法理解参数传递更容易懂一些。
特别注意到C++独有的 reference parameter 写法,这是因为 C语言只支持pointers,不支持references .
#include <iostream>
void increment(int &x)
{
x++;
}
int main()
{
int value = 10;
std::cout << "Before increment: value = " << value << std::endl;
// Before increment: value = 10
increment(value);
std::cout << "After increment: value = " << value << std::endl;
// Before increment: value = 11
return 0;
}
extern关键字
准备两个文件,1.c和2.c:
1.c:
// 1.c
#include<stdio.h>
int num = 10001;
void forfun() {
printf("File 1.c: void forfun()");
}2.c:
// 2.c
#include<stdio.h>
#include"1.c"
extern int num;
extern void forfun();
int main() {
printf("In file 2.c, display variable num: %d\n", num);
forfun();
return 0;
}编译2.c,运行结果:
In file 2.c, display variable num: 10001
File 1.c: void forfun()后续阅读材料:🔗 [C语言正确使用extern关键字_xingjiarong的专栏-CSDN博客_c extern] https://blog.csdn.net/xingjiarong/article/details/47656339
static关键字
简单介绍:

static的一个重要应用:

并发,并行,串行,异步,同步,多线程,进程,线程
| 并发 | Concurrent | |
| 并行 | Parallel | |
| 串行 | Sequential | |
| 异步 | Asynchronous | 异步强调的是非阻塞,是一种编程模式(pattern),主要解决了UI响应被阻塞的问题,可借助线程技术或者硬件本身的计算能力解决。 |
| 同步 | Synchronous | |
| 进程 | Process | |
| 线程 | Thread | |
| 多线程 | Multithreading | 多线程是对cpu剩余劳动力的压榨,是一种技术,强调的是并发(想想web server 需要处理大量并发请求的场景)。 |
| 多任务处理 | Computer multitasking | 多任务处理(Computer multitasking)是指计算机同时运行多个程序的能力。(wikipedia) |
| 多道程序 | Multiprogramming | 多道程序是令CPU一次读取多个程序放入内存,先运行第一个程序直到它出现了IO操作。 因为IO操作慢,CPU需要等待。为了提高CPU利用率,此时运行第二个程序。(wikipedia) |
| 并发,并行 | Concurrent, Parallel | 并发的关键是你有处理多个任务的能力,不一定要同时; 并行的关键是你有同时处理多个任务的能力。 |
| 并行,串行 | Parallel, Sequential | 串行是指多个任务时,各个任务按顺序执行,完成一个之后才能进行下一个; 并行指的是多个任务可以同时执行。 |
| 进程,线程 | Process, Thread | “进程 = 火车,线程 = 车厢, 一列火车可以有多个车厢“ (见后文) |
| 多线程,多进程 | multithreading, multiprocessing | (各有利弊,见后文的详细分析) |
并发和并行
🔗 [并发与并行的区别是什么? - 知乎] https://www.zhihu.com/question/33515481

串行和并行
(注:目前暂时不是很赞同下面这张图的最后一句话)

异步,多线程和并行
🔗 [异步,多线程和并行的区别? - 知乎] https://www.zhihu.com/question/28550867

线程和进程
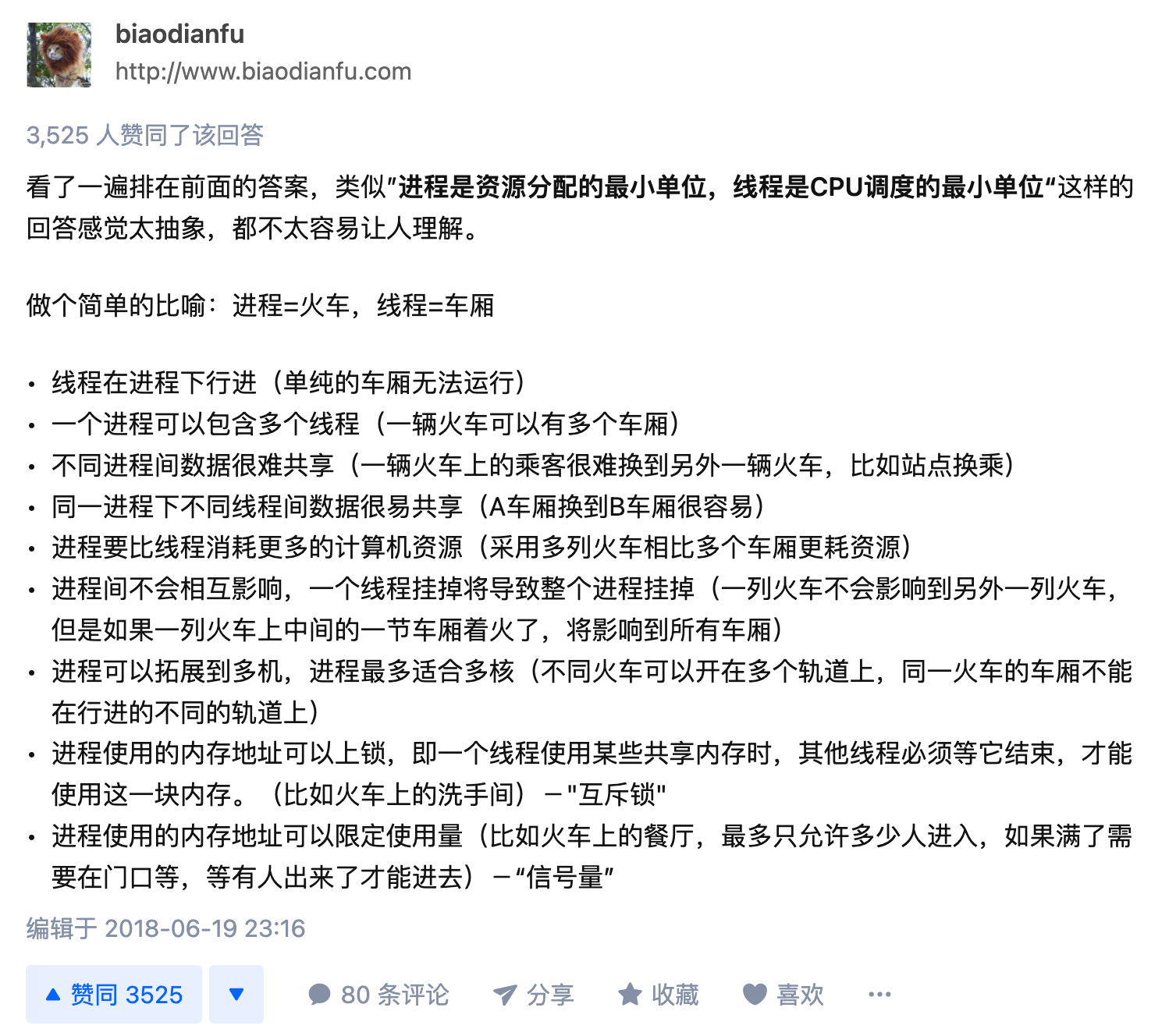
多线程和多进程
🔗 [多线程与多进程的思考 - 知乎] https://zhuanlan.zhihu.com/p/45233772
🔗 [多线程还是多进程的选择及区别 - 贺大卫 - 博客园] https://www.cnblogs.com/virusolf/p/5458325.html
OCR辅助查找工具
冯东编程话题下的优秀答主王赟Maigo等363人赞同了该回答C语言设计的本意并不是把Tint作为类型声明。它的设计本意是解一个方程™, int …让⋯的类型是int。也就是ptr的类型是int。从而反推出ptr是int指针。解方程的语义,才是int pt, pt2;的写法的由来。函数指针也是这样, int (func) ();最早调用是必须写成(func)()的。后来变成写func()也可以了。但是本意是解方程,(func)(表达式是int类型。后来C++加了&搞乱了这个规矩。但是为了对一兼容很多文化还是保留下来了。我自己还是写成int ptr的。参考1. ^ C Traps and Pitfalls, 2.1编辑于2021-01-10 23:19还有个陷阱,int* ptr_1, ptr_2看起来它应该声明两个指针,但是ptr_1是一个指针,而ptr_2是一个整数。char digit to hex char (int digit) ~ const char hex chars [16]三“0123456789ABCDEFWreturn hex chars [digit];一每次调用digit to hex char函数时,都会把字符0123456789ABCDEF复制给数组hex chars来对其进行初始化。现在,把数组设为static的:char digit to hex char (int digit) ~ static const char hex chars [16]二“0123456789ABCDEF”;return hex chars [digit];一由于static型变量只进行一次初始化,这样做就改进了digit to hex char函数的速度。知乎用户UOXW9H2,277人赞同了该回答你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以我认为它们最关键的点就是:是否是『同时』编辑于2015-08-12 03:083.串行、并行:并行和串行指的是任务的执行方式。串行是指多个任务时,各个任务按顺序执行,完成一个之后才能进行下一个。并行指的是多个任务可以同时执行,异步是多个任务并行的前提条件。 Alfred反者道之动 173人赞同了该回答先搞懂概念: 多线程是对cpu剩余劳动力的压榨,是一种技术,强调的是并发(想想web server需要处理大量并发请求的场景)。--并发与并行的区别? 异步强调的是非阻塞,是一种编程模式(pattern),主要解决了U!响应被阻塞的问题,可借助线程技术或者硬件本身的计算能力解决。 并行虽然同样也是对cpu剩余劳动力的压榨,且基于多线程技术,但它强调的是高效完成计算任务,而不是并发数量。 问题比较抽象,举个例子: 背景:作为一个北漂,准备结束北漂生涯,谋划如何搬家。其余家当都变买了,就剩下有一辆小轿车,和一辆摩托车需要带回家。 1.阻塞式编程:先开其中一辆回去,再回来开另一辆车回去。 2.传统异步式编程:摩托车办理快递,我开汽车回去。注意,快递公司派件(回调)时我不一定已经开车到家,如果必须本人签收,就比较麻烦了。----此种通过回调进行异步编程的方式,没法编写符合思维顺序的代码。 3.基于多线程的异步编程:我获得了瞬间移动的超能力(cpu计算速度提升),以毫秒级的速度在汽车与摩托车之间切换驾驶。汽车(主线程)上有车载电话,可以使用处理其它事情。----期间频繁的上下文切换,会造成额外的损耗,造成反应能力比较差,只能开到60迈。 4.并行编程:我获得了分身的超能力(多核cpu的出现),两个我同时开两辆车回家。----充分发挥了cpu的能力,没有额外切换上下文的损耗,精力充沛,在120的时速狂飙。发布于2018-07-23 06:54 赞同173 22条评论1分享食收藏喜欢biaodianfu http://www.biaodianfu.com 3,525人赞同了该回答看了一遍排在前面的答案,类似”进程是资源分配的最小单位,线程是CPU调度的最小单位“这样的回答感觉太抽象,都不太容易让人理解。 做个简单的比喻:进程=火车,线程=车厢线程在进程下行进(单纯的车厢无法运行)一个进程可以包含多个线程(一辆火车可以有多个车厢)不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)一”互斥锁”进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)一“信号量” 编辑于2018-06-19 23:16 赞同3525 80条评论7分享收藏喜欢对比维度多进程多线程总结数据共享、同数据共享复杂,需要用IPC;数据是分开的,同步简单因为共享进程数据,数据共享简单,但也是因为这个原因导致各有优步同步复杂势内存、CPU占用内存多,切换复杂,CPU利用率低占用内存少,切换简单,CPU利用率高线程占优创建销毀、切创建销毁、切换复杂,速度慢创建销毁、切换简单,速度很快线程占换优编程、调试编程简单,调试简单编程复杂,调试复杂进程占优可靠性进程间不会互相影响一个线程挂掉将导致整个进程挂掉进程占优分布式适应于多核、多机分布式;如果一台机器不够,扩展到多台机器适应于多核分布式进程占比较简单优 10.1.1静态局部变量在局部变量声明中放置单词static可以使变量具有静态存储期限而不再是自动存储期限。因为具有静态存储期限的变量拥有永久的存储单元,所以在整个程序执行期间都会保留变量的值。思考下面的函数: void f(void) -A static int i; /* static 1ocal variable */ On因为局部变量讠己经声明为static,所以在程序执行期间它所占据的内存单元是不变的。在f返回时,变量讠不会丢失其值。静态局部变量始终有块作用域,所以它对其他函数是不可见的。概括来说,静态变量是对其他函数隐藏数据的地方,但是它会为将来同一个函数的再调用保留这些数据。
