 WARNING: This article may be obsolete
WARNING: This article may be obsoleteThis post was published in 2021-09-19. Obviously, expired content is less useful to users if it has already pasted its expiration date.
 This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.
This article is categorized as "Garbage" . It should NEVER be appeared in your search engine's results.主要内容:python3,朴素贝叶斯,文本分类,情感分析,交叉验证,Maximum likelihood,MAP estimation .
首先是一些现成的教程和代码:https://blog.csdn.net/csqazwsxedc/article/details/69488938 , https://zhuanlan.zhihu.com/p/74207933
我长期以来一直把tiny这个单词读错了,遗憾的是一直没有机会发现...直到今天才感到不对劲。
一个简单的入门视频:https://www.bilibili.com/video/BV1AC4y1t7ox
哎呀,非常不妙,这个视频被删掉了,但还好我凭借视频的简短笔记找到了它的英文版,大概率就是它了:🔗 [Naive Bayes, Clearly Explained!!! - YouTube] https://www.youtube.com/watch?v=O2L2Uv9pdDA
这个视频讲解了朴素贝叶斯的基本算法(用于一个简单的垃圾邮件判断),以及为什么要统一加上 pseudo count (或者又称smoothing/Lapace smoothing)。(后文有更详细的内容)
最后的总结里提到了navie bayes的特点:high bias和low variance .(后文有更详细的内容)
这个视频里同时提到了这些关键词:probability, maximum likelihood, likelihood, prior probability
关于Lapace smoothing:根据https://stats.stackexchange.com/questions/108797/in-naive-bayes-why-bother-with-laplace-smoothing-when-we-have-unknown-words-in 以及 https://en.wikipedia.org/wiki/Additive_smoothing :
(...) Instead of using a Laplace smoothing (which comes from imposing a Dirichlet prior on the multinomial Bayes), (...)
https://stats.stackexchange.com/questions/108797/in-naive-bayes-why-bother-with-laplace-smoothing-when-we-have-unknown-words-in
有关machine learning的bias和variance: 见https://zhuanlan.zhihu.com/p/45213397
如果要简单了解,那就是:
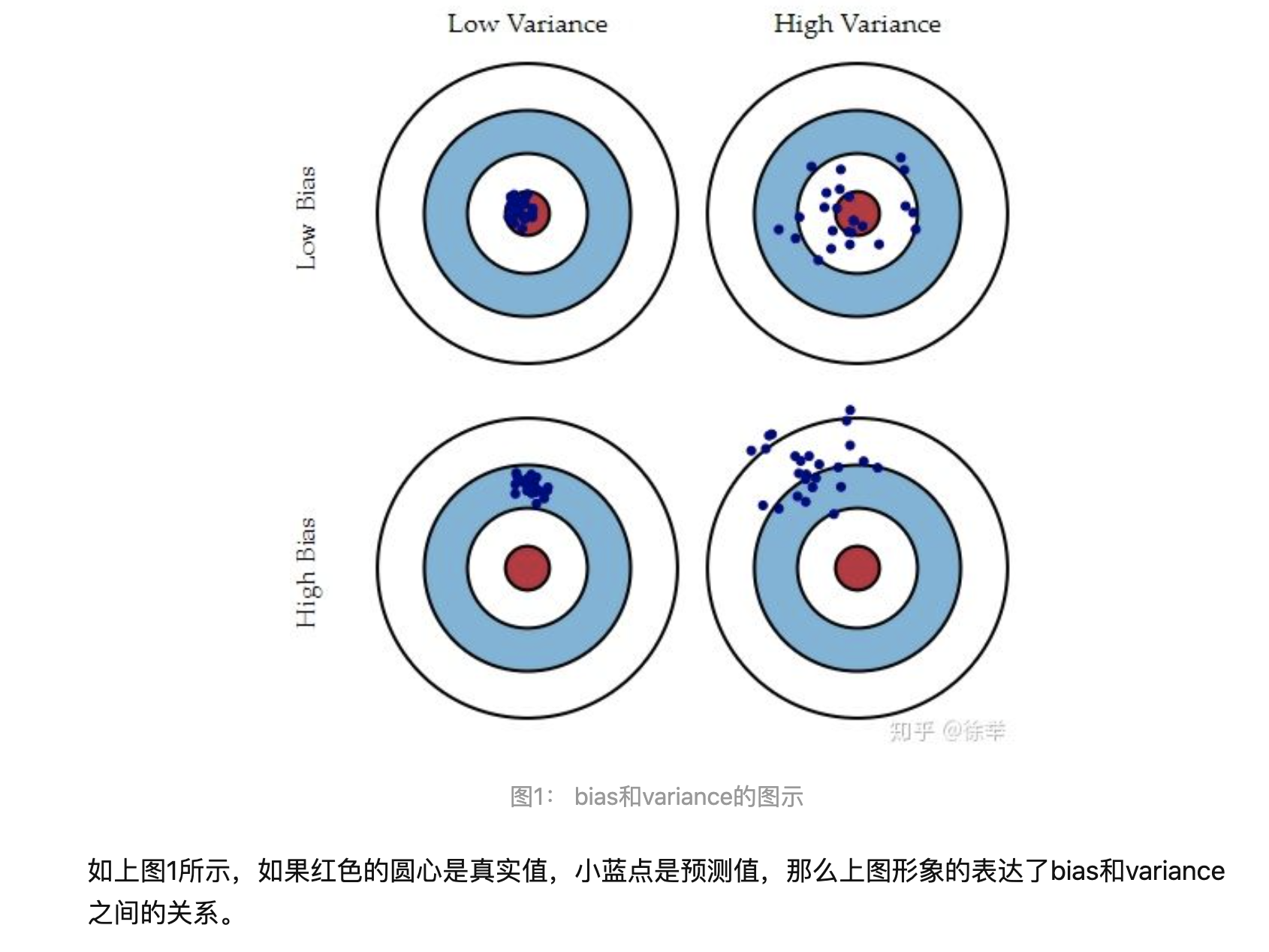
(2025-04-10)
但由于这张图对我的影响实在太深,所以我在理解(machine learning) model bias/variance的时候也下意识套用了上面这张图进行理解,就没理解对。
对于model bias/variance,正确的理解方式应该是:
high variance = overfitting; high bias = underfitting
为什么high variance是overfitting呢?可以这样理解:“Model variance refers to how much the model’s predictions change if you train it on different subsets of the data."(来自GPT, 2025)
同理,对model bias的理解:“Bias refers to how much the model’s predictions consistently miss the true pattern”(2025 gpt).
参考上面提到的“一个简单的入门视频:https://www.bilibili.com/video/BV1AC4y1t7ox ”,假设我们现在要开始复现一个非常简单的朴素贝叶斯文本分类器,我们首先要确定我们使用哪些基本方法:
1,使用MLE:分类计算过程中没有pseudo count/smoothing,这样大概率会在实际计算中出现乘数为0的情况。
2,使用MAP:分类计算过程中添加了pseudo count/smoothing,避免了乘0的情况发生。一般来说我们会把pseudo count设置为1。
有的时候我们会在英文资料里看到【token】这样的术语:https://www.zhihu.com/question/64984731 。
Chopping up sentences into single words (called tokens) is called tokenization. In Python, generally a string is tokenized and stored in a list.
计算token的数量意味着计算所有拆分词汇的数量之和,注意重复的也要被计算在内,比如:
{the dog is walking}{he is walking},在这里:|vocabulary|=6,而|token|=7
词袋模型与标点符号(字符):
强制去掉任何标点符号character: https://stackoverflow.com/questions/265960/best-way-to-strip-punctuation-from-a-string
import string
a='hello$hello!'
print(a.translate(str.maketrans('', '', string.punctuation))) # 'hellohello'
regex验证:
\b\w+\b交叉验证
关于smoothing parameter的选择问题:
OCR辅助查找工具
Low Variance High Variance Bias Low 岳High 卿乎@饼華图1: bias和variance的图示如上图1所示,如果红色的圆心是真实值,小蓝点是预测值,那么上图形象的表达了bias和variance之间的关系。
